数据库知识扫盲,数据库索引

1、存储引擎
早期存储引擎都是把数据库相关数据固化到磁盘的,在并发上每张表都是表锁,
后期的存储引擎(例如innodb,in-memory等)大多都是元数据在磁盘上,索引数据在内存中,在并发上每张表都是行锁
2、磁盘型数据库索引
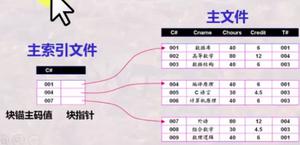
数据库如一本词典,存储很多数据,但要快速找到你需要查的词,就需要目录,在数据库中这个目录就叫索引,索引存的啥呢,
索引存的是被建索引字段的有序集合,并且每个字段都跟着一个数据的磁盘物理地址,有了索引表,如何查呢,在我们学习数据
结构与算法的时候,就接触到二叉树查找,那个时候就了解到树结构在查询上的优良性能,所以为了提高索引表的查询性能,索引
表数据是被存在树结构上的,SQL是b+树,MongoDB是b树,简单区别就是b+树数据存放在叶子节点,叶子节点上有横向指针,
这也就确定了SQL在范围查询上的优良性能,b树数据存放在各个节点,这就确定MongoDB在精准数据查询上的优良性能。
既然大致了解了索引结构,那索引是如何提升查询性能呢,索引树存在内存上,当你查询被索引数据时,数据库会遍历索引树,
匹配数据,找到数据磁盘物理地址,取出数据,这个过程因索引树参与数据匹配,会大大降低扫描的数据量,由此大大提升查询
性能,从这里我们能看出索引两大特点,有序集合和树结构。既然索引这么好,是不是应该给所有字段建立索引呢,其实非也,
索引会大大提升查询性能,但也会增加数据插入负担,因为每插入一条数据,所有相关索引要更新的,所以索引要查询量大的字段
上面,查询量不大想优化性能的要权衡增加的插入负担。常用的索引类型有三种,有序索引,hash索引,text索引,最常用的是
有序索引,就是上边讲的内容。复合索引是多字段索引,字段索引用途常为查询和排序,如果复合字段都为查询功能,则按照主次
建立索引即可,如果复合字段有查询也有排序,排序字段要放在查询字段前面建立索引。
索引性能调试有俩重要参数,毫秒数跟扫描量,具体参考以毫秒数为主,毫秒数和扫描量正相关,但毫秒数跟索引好坏不一定正相关,
这中间还牵涉到一个参数是数据量。
3、查询语法
关系型数据库大多遵循SQL语法规范,非关系型数据库语法各异。
4、存取性能
数据库按照存储位置分内存型数据库,磁盘型数据库。内存型数据库数据存在内存中,查询性能秒杀磁盘数据库。
5、数据库管理工具
这个因人而异,我个人比较喜欢Navicat,因为Navicat能连接各种数据库,并且交互比较友好,界面为中文。
6、数据库集群
每种数据库都有配置文件,一个配置文件启动一个数据库实例,集群就是配置多个数据库文件,可以分布在不同服务器上,
启动多个实例,建立主仆关系,主少从多, 集群一般为主写从读。
以上是 数据库知识扫盲,数据库索引 的全部内容, 来源链接: utcz.com/z/535883.html