数据库索引知识点整理
初识索引
索引的概念
索引是定义在存储表的基础上,有助于无需检查所有记录而快速定位所需记录的一种辅助存储结构,由一系列存储在磁盘上的索引项组成,每一索引项又由两部分构成。即索引字段和行指针。
索引字段
由表中某些列通常是一列中的值串接而成。索引中通常存储了索引字段的每一个值。
行指针
指向表中包含索引字段值的记录在磁盘上的存储位置。
存储索引项文件的为索引文件,存储表称为主文件。
索引文件组织方式
(相对照的,主文件组织有堆文件,排序文件,散列文件,聚簇文件等多种方式)
排序索引文件:按索引字段值的某一种顺序组织存储
散列索引文件:依据索引字段值使用散列函数分配散列桶的方式存储
索引的作用
在一个表上针对不同属性或者属性组合建立不同的索引文件,索引字段值可以是表中任何一个属性的值或者属性值的组合;
索引文件比主文件小得多,通过检索一个小的索引文件(可以完全装载进内存),快速定位之后,再有针对性的读取非常大的主文件中的相关记录;
有索引时,更新操作必须同步更新索引文件和主文件。保持其数据一致性。
SQL语言中的索引创建与维护
基础知识
当定义table之后,如果定义了主键,系统自动生成主索引;
索引可以由用户定义或者撤销;
当索引被创建后,不论是主索引还是用户定义的索引,DBMS都将自动维护所有索引;
当table被删除之后,定义在该表上的所有索引自动撤销。
创建,撤销索引
CREATE INDEX idxSname ON Student(Sname);
DROP INDEX idxSname;
稠密索引与稀疏索引
稠密索引
对于主文件中每一个记录(形成的每一个索引字段值),都有一个索引项和它相对应,指明该记录所在位置。这样的索引称稠密索引。(dense index)
稀疏索引
对于主文件中的部分记录(形成的索引字段值),有索引项和它对应,这样的索引称为非稠密索引或者稀疏索引(sparse index)。
稀疏索引如何定位记录
定位索引字段值为K的记录,需要
首先找相邻的小于K的最大索引字段值所对应的索引项;从该索引项所对应的记录开始顺序进行table的检索
稀疏索引的使用要求:主文件必须是按照对应索引字段属性排序存储
相比稠密索引:空间占用更少,维护任务更轻,但速度更慢
平衡:索引项不指向记录指针,而是指向记录所在的存储块的指针,即每一存储块有一个索引项,而不是每条记录有一索引项——主索引
稠密索引如何定位记录
1.候选键属性的稠密索引 一一对应即可
2.非候选键属性的稠密索引,主文件按照索引字段值排序,对每一个不重复的第一个索引字段值建立索引项,相同索引字段值则在附近寻找;
3.非候选键属性的稠密索引,主文件未按照索引字段值排序,不要求索引项中的索引字段唯一,可以重复出现,以实现对主文件中对应索引字段值的指向;
4.非候选键属性的稠密索引,主文件未按照索引字段值排序,若要求索引中索引字段是唯一的,则可以引入一个中间层,指针桶;该指针桶就是第3种情况。
主索引
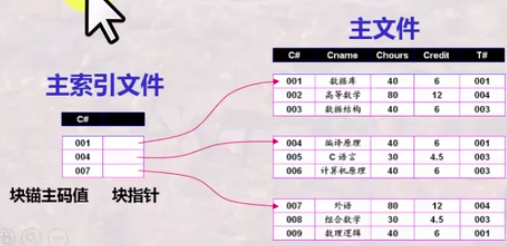
主索引概念
通常是对每一个存储块有一个索引项,索引项的总数和存储表所占的存储块数目相同,存储表的每一存储块的第一条记录,又称为锚记录,简称块锚。
主索引的索引字段值为块锚的索引字段值,而指针指向其所在的存储块。
主索引是按索引字段值进行排序的一个有序文件,通常建立在有序主文件的基于主码的排序字段上,即主索引的索引字段与主文件的排序码(主码)有对应关系。
主索引是稀疏索引。
辅助索引
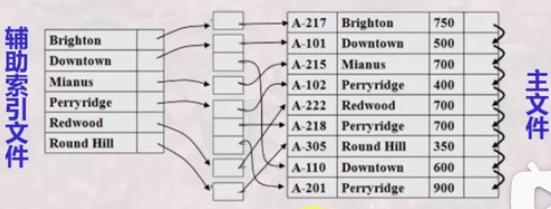
辅助索引定义
是定义在主文件的任一或者多个非排序字段上的辅助存储结构;通常是对某一非排序字段上的不同值有一个索引项,索引字段即是该字段的不同值,而指针则指向包含该纪录的块或者记录本身;
当非排序字段为索引字段时,如该字段值不唯一,则要采用一个类似链表的结构来保存该字段值的所有记录的位置;
辅助索引是稠密索引,检索速度有时候相当高
主索引和辅助索引的区别和联系
一个主文件仅有一个主索引,但可以有多个辅助索引;
主索引通常建立在主码或者排序码上;而辅助索引建立在非排序字段上;
可以利用主索引重新组织主文件数据,但辅助索引不能改变主文件数据;
主索引是稀疏索引,辅助索引是稠密索引。
聚簇索引和非聚簇索引

聚簇索引
是指索引中邻近的记录在主文件中也是临近存储的;
非聚簇索引
是指索引中邻近的记录在主文件中不一定是临近存储的
注意:
如果主文件的某一排序字段不是主码,则该字段上每个记录取值不唯一,此时该字段称为聚簇字段;聚簇索引通常是定义在聚簇字段上;聚簇索引通常是对聚簇字段上的每一个不同值有一个索引项(索引项的总数和主文件中聚簇字段上不同值的数目相同),索引字段即是聚簇字段的不同值,由于有相同聚簇字段值的记录可能存储在若干块中,则索引项的指针指向其中的第一块。一个主文件只能有一个聚簇索引文件,但可以有多个非聚簇索引文件。主索引通常是聚簇索引(但其索引项总数不一定和主文件中聚簇字段上不同值的数目相同,其和主文件存储块数目相同);辅助索引通常是非聚簇索引。主索引/聚簇索引是能够决定记录存储位置的索引;而非聚簇索引则只能用于查询,指出已存储记录的位置。
倒排索引
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
多级索引
当索引项较多时,可以对索引再建立索引,称为多级索引。
常见的多级索引:B树/B+树索引
多属性索引
索引字段由表的多个属性值组合在一起形成的索引
散列索引
使用散列技术组织的索引
网格索引
使用多索引字段进行交叉联合定位与检索
B+树索引
定义
一种以树形数据结构来组织索引项的多级索引
由于一个存储块是可以存储多个索引项,每个索引项又由指针和索引字段两部分构成。用Ki表示索引字段值,Pi表示指针,指向索引块或者数据块或者数据块中记录。
一块中通常可以存储n-1个索引项和1个指针。
B+树特点
- 能够自动保持与主文件大小相适应的树的层次
- 每个索引块的指针利用率都在50%~100%
索引字段值x在Ki-1<=x<Ki的由Pi指向,而Ki<=x<Ki+1的由Pi+1指向。
叶节点和叶子节点的指针分别指向什么
非叶结点指针指向索引块,叶结点指针指向主文件的数据块或数据记录
叶结点的最后一个指针指向下一个数据块
一个索引块实际使用的索引指针个数d,满足(根结点除外)
n/2<=d<=n
根结点至少2个指针被使用
B+树存储约定
索引字段值重复出现于叶结点和非叶结点
指向主文件的指针仅出现于叶结点
所有叶结点即可覆盖所有键值的索引
索引字段值在叶结点中是按顺序排列的
仅叶结点的集合就是主文件完整的索引
到此这篇关于数据库索引" title="数据库索引">数据库索引知识点整理的文章就介绍到这了,更多相关数据库索引内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 数据库索引知识点整理 的全部内容, 来源链接: utcz.com/p/230949.html