初识Hadoop的三种安装模式

特点:高可靠性(不怕丢)、高效性(处理速度快)、高容错性
- ps:使用Hadoop版本:
接下来所用到的Hadoop2.8.5,虽然目前Hadoop已经更新到3.x了;但是我们始终秉持一个观点“用旧不用新”,因为毕竟旧版本较为稳定(目前虽然jdk出到版本为16了,但是我们还是会使用jdk8和jdk11),包括后期使用的各项Hive、Hbase等都需要与hadoop版本相对应,很难去找此类资源;当然如果到公司以后,公司也会给你提供好相应版本的,直接用就可以。
Hadoop
HDFS:分布式文件系统---需要安装
MapReduce:分布式离线计算框架----不需要安装----逻辑概念-----需要编码实现
Yarn:分布式资源调度系统----需要安装
安装方式:
- 本地模式
- 伪分布式模式---一台电脑
- 完全分布式
1.本地模式配置
(本模式下:hdfs和yarn组件无法使用,只能使用mapreduce-----一般只用来测试mapreduce)
一般会将目录设置为(/opt目录一般存放第三方软件)---app下放安装的软件,software下放第三方软件的压缩包
- 解压hadoop压缩包至/opt/app目录下
vim /etc/profile来更改系统环境变量(配置Hadoop的环境变量:目的是为了能够在任何目录下都能使用hadoop命令)
export HADOOP_HOME=/opt/app/hadoop-2.8.5export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profilehadoop version
2.伪分布式模式
(本模式下:hadoop的组件hdfs和yarn都在一台机器上,需要去修改配置文件)
前言:一个巨大的文件需要进行存储,单台计算机肯定是不能存储这个文件的,因此我们可以将这个文件切割成几个部分,分别放到不同计算机上。但是这时出现了一个问题:三台机器上存储的文件互相没有联系,大文件怎么能下载呢? 此时可以在每个电脑上安装HDFS进行 “关系定义”,接下来讨论下这个关键性技术HDFS
主从模式--分布式软件:一个主节点,多个从节点
熟悉概念
HDFS{
NameNode:存储元数据{领导,知道数据放到哪里}
DataNode:存储数据(员工)
SecondaryNameNode:(秘书)
}
Yarn{
ResourceManager (相当于NameNode:领导)
NodeManager (相当于DataNode:员工)
}
配置项
(.sh文件进行与java相连的jdk配置:配置JAVA_HOME=/opt/app/jdk1.8)
(.xml文件进行相应配置:core(common公共的)、hdfs、mapred、yarn)
1.core-site.xml<!--指定Hadoop运行时产生临时文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.8.5/temp</value>
</property>
2.hdfs-site.xml<!--指定HDFS中namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.20:9000</value>
</property>
<!--指定HDFS中副本的数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3.mapred-site.xml<!--通过yarn去运行-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.yarn-site.xml<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的ResourceManager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.20</value>
</property>
格式化NameNode
(相当于创建core-site.xml中声明的temp目录)
{只能格式化1次,如果非要格式化的话,那么可以将产生的temp文件删除}
hadoop namenode -format开启hdfs服务和yarn服务
start-dfs.shstart-yarn.sh
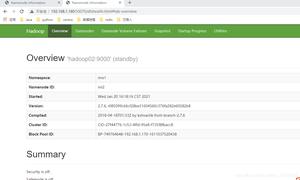
访问验证
namenode访问网址{http://ip:50070}yarn的访问网址{http://ip:8088}
补充
通过此种方式,你会发现在启动各个节点时需要反复输入密码,不想要这样的话,就寻找解决方式:
配置SSH免密钥登录
1.生成密钥
cd ~/.sshssh-keygen -t rsa
2.把密码给别人
ssh-copy-id 192.168.0.20
3.完全分布式
(最少有3台节点组成的集群)----一般在生产部署时使用
1.需要准备3台虚拟机:通过克隆(创建完整克隆)方式创建
2.配置3台虚拟机的静态网络
192.168.0.20 、192.168.0.21、192.168.0.22
3.配置3台虚拟机的免密登录
---过程与伪分布式中所谈到的免密登录一致
(成功界面)
4.同步时间
安装ntp
yum install -y ntpvim /etc/ntp.conf
此处第一个圆圈内,我的网段应该为192.168.0.0
(以上两张图片为需要在ntp.conf中修改和添加的)
修改/etc/sysconfig/ntpd
添加代码SYNC_HWCLOCK=yes
添加成开机启动
systemctl enable ntpd
然后在node2和node3上配置定时任务
crontab -e*/1 * * * * /usr/sbin/ntpdate 192.168.0.20每隔1分钟,同步node1主服务器上的时间
以上是 初识Hadoop的三种安装模式 的全部内容, 来源链接: utcz.com/z/535797.html