问题定位|XtraBackup8.0数据重建避坑事件始末

作者:卢文双 资深数据库研发工程师 目前负责青云云数据库的研发工作,热衷于研究主流数据库架构、源码,对关系型数据库 MySQL/PostgreSQL 及分布式数据库有深入研究。
前言
在为 Xenon[1] 适配新版 Percona XtraBackup 8.0[2](原有代码适配于 2.4 版本)时遇到的一些问题,在定位过程中对比了 XtraBackup 2.4 和 8.0 的异同。
版本信息[3]:
- Percona-Server 8.0.19-10
- Percona-Xtrabackup 8.0.13
问题描述
问题 1
MySQL 8.0 + Semi-Sync + 持续写入数据期间执行重建后, change master to && start slave 报错:
Last_Error: Could not execute Write_rows event on table db1.t1; Duplicate entry "28646" for key "t1.PRIMARY", Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event"s master log mysql-bin.000052, end_log_pos 437问题 2
MySQL 8.0 + Group Replication + 持续写入数据期间执行重建后,change master to && start group_replication 报错:
2020-08-21T14:51:09.977606+08:00 61 [System] [MY-010597] [Repl] "CHANGE MASTER TO FOR CHANNEL "group_replication_applier" executed". Previous state master_host="<NULL>", master_port= 0, master_log_file="", master_log_pos= 4, master_bind="". New state master_host="<NULL>", master_port= 0, master_log_file="", master_log_pos= 4, master_bind="".2020-08-21T14:51:09.987494+08:00 61 [ERROR] [MY-013124] [Repl] Slave SQL for channel "group_replication_applier": Slave failed to initialize relay log info structure from the repository, Error_code: MY-013124
2020-08-21T14:51:09.987542+08:00 61 [ERROR] [MY-011534] [Repl] Plugin group_replication reported: "Error while starting the group replication applier thread"
2020-08-21T14:51:09.987651+08:00 7 [ERROR] [MY-011669] [Repl] Plugin group_replication reported: "Unable to initialize the Group Replication applier module."
2020-08-21T14:51:09.987831+08:00 7 [ERROR] [MY-011735] [Repl] Plugin group_replication reported: "[GCS] The member is leaving a group without being on one."
要解释这两个问题,首先要弄清楚 XtraBackup 2.4 和 8.0 的区别。
XtraBackup 2.4/8.0 版本区别
通过查到可知 XtraBackup 2.4 与 8.0 版本备份记录信息有如下不同点:
- 2.4 备份生成的 xtrabackup_binlog_info 文件记录的 GTID 信息是准确的,但是备份恢复后
show master status显示的 GTID 是不准确的; - 8.0 备份的实例中只有 InnoDB 表时,xtrabackup_binlog_info 文件记录的 GTID 信息不一定是准确的,但是备份恢复后
show master status显示的 GTID 是准确的; - 8.0 备份的实例中有非 InnoDB 表时,xtrabackup_binlog_info 文件记录的 GTID 信息是准确的,备份恢复后
show master status显示的 GTID 也是准确的。
两个版本执行过程如下:
2.4 8.0
1. start backup
2. copy ibdata1 / copy .ibd file
3. excuted FTWRL
4. backup non-InnoDB tables and files
5. writing xtrabackup_binlog_info
6. executed FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS
7. executed UNLOCK TABLES
8. copying ib_buffer_pool
9. completed OK!
1. start backup
2. copy .ibd file
3. backup non-InnoDB tables and files
4. executed FLUSH NO_WRITE_TO_BINLOG BINARY LOGS
5. selecting LSN and binary log position from p_s.log_status
6. copy last binlog file
7. writing /mysql/backup/backup/binlog.index
8. writing xtrabackup_binlog_info
9. executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS
10. copy ib_buffer_pool
11. completed OK!
注意:当存在非 InnoDB 表时,8.0 会执行 FTWRL。
通过两个版本执行过程命令不难看出,主要区别在于 8.0 版本当只存在 InnoDB 表时,执行步骤 5 命令来获取 LSN、binlog position、GTID。
手册中[4],对于表 log_status 的描述如下:
The log_status table provides information that enables an online backup tool to copy the required log files without locking those resources for the duration of the copy process.
When the log_status table is queried, the server blocks logging and related administrative changes for just long enough to populate the table, then releases the resources. The log_status table informs the online backup which point it should copy up to in the source"s binary log and gtid_executed record, and the relay log for each replication channel. It also provides relevant information for individual storage engines, such as the last log sequence number (LSN) and the LSN of the last checkpoint taken for the InnoDB storage engine.
从上述手册描述可知,performance_schema.log_status 是 MySQL 8.0 提供给在线备份工具获取复制信息的表格,查询该表时,mysql server 将阻止日志的记录和相关的更改来获取足够的时间以填充该表,然后释放资源。
log_status 表通知在线备份工具当前主库的 binlog 的位点和 gtid_executed 的值以及每个复制通道的 relay log。另外,它还提供了各个存储引擎的相关信息,比如,提供了 InnoDB 引擎使用的最后一个日志序列号(LSN)和最后一个检查点的 LSN。
表 log_status 定义参数信息示例如下:
-- Semi-Syncmysql> select * from performance_schema.log_statusG
*************************** 1. row ***************************
SERVER_UUID: 6b437e80-e5d5-11ea-88e3-52549922fdbb
LOCAL: {"gtid_executed": "6b437e80-e5d5-11ea-88e3-52549922fdbb:1-201094", "binary_log_file": "mysql-bin.000079", "binary_log_position": 195}
REPLICATION: {"channels": []}
STORAGE_ENGINES: {"InnoDB": {"LSN": 23711425885, "LSN_checkpoint": 23711425885}}
1 row in set (0.00 sec)
-- Group Replication
mysql> select * from performance_schema.log_statusG
*************************** 1. row ***************************
SERVER_UUID: 7bd32480-e5d5-11ea-8f8a-525499cfbb7d
LOCAL: {"gtid_executed": "aaaaaaaa-aaaa-aaaa-aaaa-53ab6ea1210a:1-11", "binary_log_file": "mysql-bin.000003", "binary_log_position": 1274}
REPLICATION: {"channels": [{"channel_name": "group_replication_applier", "relay_log_file": "mysql-relay-bin-group_replication_applier.000004", "relay_log_position": 311, "relay_master_log_file": "", "exec_master_log_position": 0}, {"channel_name": "group_replication_recovery", "relay_log_file": "mysql-relay-bin-group_replication_recovery.000003", "relay_log_position": 151, "relay_master_log_file": "", "exec_master_log_position": 0}]}
STORAGE_ENGINES: {"InnoDB": {"LSN": 20257208, "LSN_checkpoint": 20257208}}
1 row in set (0.00 sec)
问题定位
问题 1:MySQL 8.0 + Semi-Sync 重建
Xenon 原有的重建逻辑适配于 MySQL 5.6/5.7(重建过程中 Xenon 进程存活),一直无问题。
Xenon 重建逻辑
- 禁用 raft,将 Xenon 状态设为 LEARNER;
- 如 mysql 进程存在,则
stop mysql; - 清空 MySQL 数据目录;
- 执行
xtrabackup --backup以 xbstream 方式获取对端数据; - 执行
xtrabackup --prepare应用 redo log; - 启动 mysql;
- 执行
stop slave; reset slave all; - 执行
reset master,以 xtrabackup_binlog_info 文件中的 GTID 为准设置 gtid_purged; - 启用 raft,将 Xenon 状态设为 FOLLOWER 或 IDLE;
- 等待 Xenon 自动
change master to到主节点; - 执行
start slave。
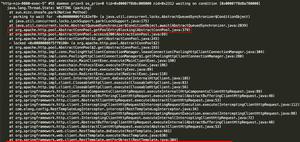
Duplicate entry "28646" for key "t1.PRIMARY" 表示主键冲突,说明表中已存在相同主键的行。跟踪重建过程中的 general log,发现在第 6 和第 7 步中间,也就是设置 gtid_purged 之前凭空多出了 change master to 和 start slave 操作。
grneral log(部分)
通过下面示例代码信息可看出,在设置 gtid_purged 之前已经启用复制获取了一部分数据,那么 xtrabackup_binlog_info 中的内容就不再准确,之后设置的 GTID 与实际数据就不一致,实际的数据比设置的 GTID 要多,会引起主键冲突。
SET GLOBAL rpl_semi_sync_master_enabled=OFFSET GLOBAL read_only = 1
SET GLOBAL super_read_only = 1
START SLAVE
STOP SLAVE
CHANGE MASTER TO MASTER_HOST = "192.168.0.3", MASTER_USER = "qc_repl", MASTER_PASSWORD = <secret>, MASTER_PORT = 3306, MASTER_AUTO_POSITION = 1
START SLAVE
BEGIN
COMMIT /* implicit, from Xid_log_event */
......
BEGIN
COMMIT /* implicit, from Xid_log_event */
SET GLOBAL rpl_semi_sync_master_enabled=OFF
SET GLOBAL read_only = 1
SET GLOBAL super_read_only = 1
START SLAVE
BEGIN
COMMIT /* implicit, from Xid_log_event */
......
BEGIN
COMMIT /* implicit, from Xid_log_event */
STOP SLAVE
RESET SLAVE ALL
RESET MASTER
SET GLOBAL gtid_purged="6b437e80-e5d5-11ea-88e3-52549922fdbb:1-102610
"
START SLAVE
SET GLOBAL read_only = 1
SET GLOBAL super_read_only = 1
SET GLOBAL sync_binlog=1000
SET GLOBAL innodb_flush_log_at_trx_commit=1
SHOW SLAVE STATUS
SHOW MASTER STATUS
SET GLOBAL rpl_semi_sync_master_enabled=OFF
SET GLOBAL read_only = 1
SET GLOBAL super_read_only = 1
START SLAVE
SHOW SLAVE STATUS
SHOW MASTER STATUS
STOP SLAVE
CHANGE MASTER TO MASTER_HOST = "192.168.0.3", MASTER_USER = "qc_repl", MASTER_PASSWORD = <secret>, MASTER_PORT = 3306, MASTER_AUTO_POSITION = 1
START SLAVE
疑问 1
问:为什么之前 MySQL 5.6/5.7 从没遇到过这个问题呢?
答:多次测试发现在 MySQL 5.6/5.7 中 set gtid_purged 前执行 change master to & start slave 会报复制错误 Slave failed to initialize relay log info structure from the repository ,在 reset slave all; reset master、set gtid_purged 后再执行 change master to & start slave 就可以正常复制,数据无误。
疑问 2
问:Xenon 中哪块逻辑引起的额外的 change master to 和 start slave?
答:在重建期间 Xenon 会设为 LEARNER 角色,而该角色在探测到 MySQL Alive后,会 change master 到主节点。
解决方案:
去掉 LEARNER 对 MySQL 的监听,要等 raft 状态变为 FOLLOWER 后,由 FOLLOWER 的监听线程
change master to到主节点。[5]对于 MySQL 8.0,重建后无需执行 reset master & set gtid_purged 操作。[6]
问题 2:MySQL 8.0 + Group-Replication 重建后无法启动 MGR
根据报错信息 Slave failed to initialize relay log info structure from the repository 看,应该是 XtraBackup 重建后的数据目录保留了 slave 复制信息导致的。
解决方案:
在启动组复制前执行 reset slave 或 reset slave all 即可解决。
XtraBackup 8.0 避坑总结
- 使用 Xtrabackup 8.0 重建集群节点后,无需执行
reset master&set gtid_purged操作; - 使用 Xtrabackup 8.0 重建 Group-Replication 集群节点后,启动组复制前要先执行
reset slave或reset slave all清除 slave 信息,否则start group_replication会失败。
备注参考
[1]. Xenon : https://github.com/radondb/xenon
[2]. Percona XtraBackup : https://www.percona.com/software/mysql-database/percona-xtrabackup
[3]. 版本名含义参考:https://www.percona.com/blog/2020/08/18/aligning-percona-xtrabackup-versions-with-percona-server-for-mysql/
[4]. MySQL 官方手册:https://dev.mysql.com/doc/refman/8.0/en/performance-schema-log-status-table.html
[5]. pr104:https://github.com/radondb/xenon/pull/104
[6]. pr102:https://github.com/radondb/xenon/pull/102
关于 RadonDB
RadonDB 开源社区是一个面向云原生、容器化的数据库开源社区, 为数据库技术爱好者提供围绕主流开源数据库(MySQL、PostgreSQL、Redis、MongoDB、ClickHouse 等)的技术分享平台,并提供企业级 RadonDB 开源产品及服务。
目前 RadonDB 开源数据库系列产品已被 光大银行、浦发硅谷银行、哈密银行、泰康保险、太平保险、安盛保险、阳光保险、百年人寿、安吉物流、安畅物流、蓝月亮、天财商龙、罗克佳华、升哲科技、无锡汇跑体育、北京电信、江苏交通控股、四川航空、昆明航空、国控生物 等上千家企业及社区用户采用。
RadonDB 可基于云平台与 Kubernetes 容器平台交付,不仅提供覆盖多场景的数据库产品解决方案,而且提供专业的集群管理和自动化运维能力,主要功能特性包括:高可用主从切换、数据强一致性、读写分离、一键安装部署、多维指标监控&告警、弹性扩容&缩容、横向自由扩展、自动备份&恢复、同城多活、异地灾备 等。RadonDB 仅需企业及社区用户专注于业务层逻辑开发,无需关注集群高可用选型、管理和运维等复杂问题,帮助企业及社区用户大幅度提升业务开发与价值创新的效率!
GitHub:
https://github.com/radondb
微信群: 请搜索添加群助手微信号 radondb
以上是 问题定位|XtraBackup8.0数据重建避坑事件始末 的全部内容, 来源链接: utcz.com/z/535690.html