mysql千万级大表的优化

千万级大表,这是一个很有技术含量的问题。一般碰到这种问题,我们下意识的会想对表进行拆分或者分区,但是其实,要从多个维度去考虑这个事情。
问题分解
我们首先找到关键字:
千万级大表
优化
那么也就对应了相应的知识点:
数据量操作对象
动作和结果
数据量
千万级是什么概念呢?
假设我们的主键是bigint类型,占据64位(8字节)空间,从btree进行索引的查找。需要遍历几次呢?
这里我们首先需要了解一个东西,即操作系统的分页。一般现在的操作系统页大小为4K,mysql的innodb的页大小默认配置的为16K。 而根据b+tree结构,每个节点保存的KEY的数量为pagesize/(keysize+pointsize)(如果是B-TREE索引结构,则是pagesize/(keysize+datasize+pointsize))。一个节点可以存贮的数据量为16*1024/(8+8)*8,最多可以存储128个索引值。
假设我们的数据为3000W(2的25次方为33554432)可以得出,(log2^25)/log128 ≈ 25/7 ≈ 3.57。因此一个千万量级,且存储引擎是MyISAM或者InnoDB的表,其索引树的高度在3~5之间。可以看出,高度并不是特别的大。
当然,数据量我们也要通过业务属性来进行合理优化。
流水、日志型记录。
通常是一些数据流水,日志记录的业务,里面的数据随着时间的增长会逐步增多,超过千万门槛是很容易的一件事情。
一个相对稳定的数据。
比如一个稳定的用户表,业务稳定期不会得到大规模增长。
过分的冗余了数据。
操作对象,数据表
数据操作的过程就好比数据库中存在着多条管道,这些管道中都流淌着要处理的数据,这些数据的用处和归属是不一样的。
根据业务区分的话,一般分为3中数据类型。
- 流水型数据
- 状态型数据
- 配置型数据
流水型数据
流水型数据,一般也称之为日志型数据,并没有实际的强业务关联,每次业务都一定会产生,因此,体量比较大,并且不依赖前面和后面的数据,数据一般按时间线性增长。
状态型数据
状态型数据就是有状态,这个状态怎么理解呢?可以引申为事务,强关联。当A成功B也必须成功这种。
配置型数据
配置型数据,一般数据量都很小,这里就不用参与讨论了。
通常,对业务的数据量分析,应该具有一个辩证的思维去看待,进行合理的优化。
优化,动作和结果
优化,我们可以从哪些方面开始呢?
- 规范设计,这个可以参照(阿里巴巴mysql规范),记住,是参照,不是抄。
- 业务层优化
- 架构层优化
- 数据库优化
- 管理优化
其实我们通常所说的分库分表等方案只是其中的一小部分,如果展开之后就比较丰富了。
作为一个业务开发者角度,我们并不多赘述DBA应该尽的职责,我们多从业务角度去考虑怎么优化。
规范设计
规范的本质不是解决问题,而是杜绝一些潜在的问题实现。
举个栗子,索引的建立,数据库字段的长度。这些都应该有规范可依循。
配置规范
innodb项目内部字符集统一,utf8mb4
默认事务级别调整,RR=》RC,提高并发性能(根据业务来)
预估数据表数据量,提前进行合理的建表拆分。mysql建议在2000W以内
建表规范
外键不适合innodb浮点数建议用decimal而非float和double
整型定义不去进行自定义宽度
enum使用tiny替代
尽量少用长文本、长二进制类型,如果业务要求使用,尽量拆分
字段not null
命名规范
小驼峰长度建议小于12
尽量要能见名知意
索引规范
命名: idx_col1_col2......,uniq_col1_col2......联合索引字段不超过5个
单表索引不超过5个
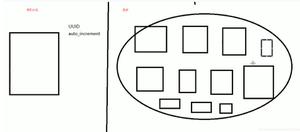
主键索引一般选用自增或者雪花算法实现,保证整体有序
不建议使用%前缀模糊查询,例如LIKE “%weibo”,无法用到索引,会导致全表扫描
UPDATE、DELETE语句需要根据WHERE条件添加索引。
避免在索引字段上使用函数,否则会导致查询时索引失效。
开发规范(主流业务瓶颈基本出在mysql)
避免使用mysql自带功能:存储过程、触发器、自定义函数减少排序
统计尽量使用缓存,进行离线计算
字段变更需标注原有意义
使用预处理防止sql注入
sql in长度限制
禁止select *
批量insert长度的限制
业务层优化
此处常见的就是对数据表的业务类型进行分析。读多写少,读少写多
业务拆分:
- 将混合业务拆分为独立业务
- 讲状态和日志型数据分离
表水平拆分:
- 按照日期拆分(全局日志类型)
- 按照取模拆分 (恒定关联的数据类型)
- 分区,mysql我个人不建议
另外,对高频读数据可以进行缓存优化
高频写的业务一般进行解耦,异步写入,防止阻塞,并且还可以通过降低写入频率(比如合并写入)
架构层优化
这一块其实通常是DBA职责,如果我们已经晋级高T的话,通常会需要和DBA协商。
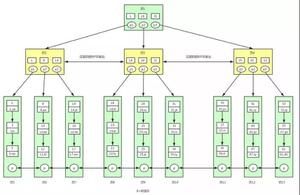
- 系统扩展,使用中间件
- 读写分离
- 负载均衡
- 离线业务剥离
- nosql异构
数据库优化
事务优化,减小事务影响的数据和表
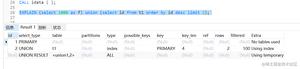
sql优化,通常出现slow sql进行explain分析,尽量减少关联和查询条件
索引优化,尽量命中索引,尽量减少范围查询,尽量在大表中杜绝全表扫描。
总结:
千万级大表的优化是根据业务场景,以成本为代价进行优化的,绝对不是孤立的一个层面的优化。一定要结合业务进行,否则,优化就是吹牛逼。
以上是 mysql千万级大表的优化 的全部内容, 来源链接: utcz.com/z/535452.html