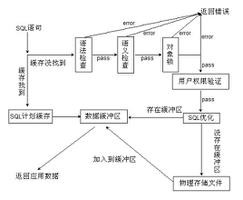
3.select语句执行过程优化器

1.有哪些
2.开启追踪
优化器追踪默认是关闭的
2.1 开启
SHOW VARIABLES LIKE "optimizer_trace";set optimizer_trace="enabled=on";
2.2 执行一个sql后查询计划
select * from information_schema.optimizer_trace它是一个 JSON 类型的数据,主要分成三部分,准备阶段、优化阶段和执行阶段。
- expanded_query 是优化后的 SQL 语句。
- considered_execution_plans 里面列出了所有的执行计划。
2.3 关闭
开启这开关是会消耗性能的,因为它要把优化分析的结果写到表里面,所以不要轻易开启
set optimizer_trace="enabled=off";SHOW VARIABLES LIKE "optimizer_trace";
3.分析查询计划 [2] [3]
3.1 命令
常用命令
explain select ...将表格形式的执行计划转化成 select语句
explain extended select ...3.2 结果说明
3.2.1 id
有一组数字组成。表示一个查询中各个子查询的执行顺序;
- id相同执行顺序由上至下。
- id不同,id值越大优先级越高,越先被执行。
- id为null时表示一个结果集,不需要使用它查询,常出现在包含union等查询语句中。
3.2.2 select_type
序号 类型 描述
1
SIMPLE
不包含任何子查询或union等查询
2
PRIMARY
包含子查询最外层查询就显示为 PRIMARY
3
SUBQUERY
在select或 where子句中包含的查询
4
DERIVED
from字句中包含的查询
5
UNION
出现在union后的查询语句中
6
UNION RESULT
从UNION中获取结果集
3.2.3 table
查询的数据表,当从衍生表中查数据时会显示 derivedx x 表示对应的执行计划id。
3.2.4 partitions
表分区、表创建的时候可以指定通过那个列进行表分区。
3.2.5 type(以下基本性能从低到高排列,数越小性能越高)
- ALL 扫描全表数据 9
- index 遍历索引 8
- range 索引范围查找 7
- index_subquery 在子查询中使用 ref
- unique_subquery 在子查询中使用 eq_ref
- ref_or_null 对Null进行索引的优化的 ref 6
- fulltext 使用全文索引
- ref 使用非唯一索引查找数据 5
ref类型还经常会出现在join操作中:
表关联查询时必定会有一张表进行全表扫描,此表一定是几张表中记录行数最少的表,然后再通过非唯一索引寻找其他关联表中的匹配行,以此达到表关联时扫描行数最少。
eq_ref 在join查询中使用PRIMARY KEY or UNIQUE NOT NULL索引关联。4
const 使用主键或者唯一索引,且匹配的结果只有一条记录。3
system const 连接类型的特例,查询的表为系统表。2
NULL,MySQL不用访问表或者索引,直接就能够得到结果 1
如 select 1 from dual
3.2.6 possible_keys
可能使用的索引,注意不一定会使用。查询涉及到的字段上若存在索引,则该索引将被列出来。当该列为 NULL时就要考虑当前的SQL是否需要优化了。
3.2.7 key
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL。
PS:查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
3.2.8 key_length
索引长度 char()、varchar()索引长度的计算公式:
(Character Set:utf8mb4=4,utf8=3,gbk=2,latin1=1) * 列长度 + 1(允许null) + 2(变长列)varchar: 编码为utf8mb4,列长为128,不允许为NULL,字段类型为varchar(128)。key_length = 128 * 4 + 0 + 2 = 514;
int类型占4位,允许null,索引长度为5。
3.2.9 ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
3.2.10 rows
返回估算的结果集数目,并不是一个准确的值。
3.2.11 extra
extra的信息非常丰富,常见的有:
- Using index 使用覆盖索引 ,不会回表查询
- Using where 使用了用where子句来过滤结果集
- Using filesort 使用文件排序,使用非索引列进行排序时出现,非常消耗性能,尽量优化。
- Using temporary 使用了临时表
- Using Index Condition 表示进行了ICP优化
ICP(Index Condition Pushdown)
Pushdown表示操作下放,某些情况下的条件过滤操作下放到存储引擎。
EXPLAIN SELECT * FROM rental WHERE rental_date="2005-05-25" AND customer_id>=300 AND customer_id<=400;在5.6版本之前:
优化器首先使用复合索引idx_rental_date过滤出符合条件rental_date="2005-05-25"的记录,然后根据复合索引idx_rental_date回表获取记录,最终根据条件customer_id>=300 AND customer_id<=400过滤出最后的查询结果(在服务层完成)。
在5.6版本之后:MySQL使用了ICP来进一步优化查询,在检索的时候,把条件customer_id>=300 AND customer_id<=400也推到存储引擎层完成过滤,这样能够降低不必要的IO访问。Extra为Using index condition就表示使用了ICP优化
注意 Explain 的结果也不一定最终执行的方式。
参考资料
- 1.https://mp.weixin.qq.com/s/PEk97JyIlUexuAjFr2pmiw
- 2.https://juejin.im/post/5a52386d51882573443c852a
- 3.https://juejin.im/post/5b63ac5d5188251b1e1fea0f
- 4.https://www.cnblogs.com/huchong/p/10235260.html
- 5.https://www.cnblogs.com/ggjucheng/archive/2012/11/11/2765237.html
以上是 3.select语句执行过程优化器 的全部内容, 来源链接: utcz.com/z/534779.html