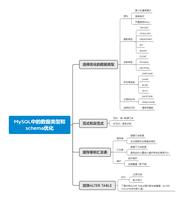
FlinkSQL源码阅读schema管理

在Flink SQL中, 元数据的管理分为三层: catalog-> database-> table,
我们知道Flink SQL是依托calcite框架来进行SQL执行树生产,校验,优化等等, 所以本文讲介绍FlinkSQL是如何来结合Calcite来进行元数据管理的.
calcite开放的接口
public interface Schema { Table getTable(String name);
Schema getSubSchema(String name);
....
}
如接口所示, Schema接口,可以通过table名来获得一张表, 可以通过schema名来获得一个子schema.
public interface Table { RelDataType getRowType(RelDataTypeFactory typeFactory);
....
}
看Table的接口, 主要就是返回table的RelDataType.
Flink的相关实现
接下来,我们来看下Flink是如何实现这些接口的:
public class CatalogManagerCalciteSchema extends FlinkSchema { @Override
public Schema getSubSchema(String schemaName) {
if (catalogManager.schemaExists(name)) {
return new CatalogCalciteSchema(name, catalogManager, isStreamingMode);
} else {
return null;
}
}
}
public class CatalogCalciteSchema extends FlinkSchema { @Override
public Schema getSubSchema(String schemaName) {
if (catalogManager.schemaExists(catalogName, schemaName)) {
return new DatabasecalciteSchema(schemaName, catalogNmae, catalogManager, isStreamingMode);
}
}
}
public class DatabaseCalciteSchema extends FlinkSchema { private final String databaseName;
private final String catalogName;
private final CatalogManager catalogManager;
@Override
public Table getTable(String tableName) {
ObjectIdentifier identifier = ObjectIdentifier.of(catalogName, databaseName, tableName);
return catalogManager.getTable(identifier)
.map(result -> {
CatalogBaseTable table = result.getTable();
FlinkStatistic statistic = getStatistic(result.isTemporary(), table, identifier);
return new CatalogSchemaTable(identifier,
table,
statistic,
catalogManager.getCatalog(catalogName)
.flatMap(Catalog::getTableFactory)
.orElse(null),
isStreamingMode,
result.isTemporary());
})
.orElse(null);
}
@Override
public Schema getSubSchema(String name) {
return null;
}
}
很容易发现,CatalogSchema返回DatabaseSchema, DatabaseSchema返回Table,
这样就容易理解,Flink的三层结构是怎样的了. 同时, 具体的元数据实际上都是在catalogManager中。
DatabaseSchema中返回的Table类型为CatalogSchemaTable,我们来看下具体的结结构是怎样的,
上文中也提到了,Table接口主为getRowType函数, 用于返回某个table的type信息。
TableSchema是Flink内部用于保存各个字段的类型信息的类, 通过相关的转化函数,转换为calcite的type类型.
public class CatalogSchemaTable extends AbstractTable implements TemporalTable { private final ObjectIdentifier tableIdentifier;
private final CatalogBaseTable catalogBaseTable;
private final FlinkStatistic statistic;
private final boolean isStreamingMode;
private final boolean isTemporary;
...
private static RelDataType getRowType(RelDataTypeFactory typeFactory,
CatalogBaseTable catalogBaseTable,
boolean isStreamingMode) {
final FlinkTypeFactory flinkTypeFactory = (FlinkTypeFactory) typeFactory;
TableSchema tableSchema = catalogBaseTable.getSchema();
final DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
if (!isStreamingMode
&& catalogBaseTable instanceof ConnectorCatalogTable
&& ((ConnectorCatalogTable) catalogBaseTable).getTableSource().isPresent()) {
// If the table source is bounded, materialize the time attributes to normal TIMESTAMP type.
// Now for ConnectorCatalogTable, there is no way to
// deduce if it is bounded in the table environment, so the data types in TableSchema
// always patched with TimeAttribute.
// See ConnectorCatalogTable#calculateSourceSchema
// for details.
// Remove the patched time attributes type to let the TableSourceTable handle it.
// We should remove this logic if the isBatch flag in ConnectorCatalogTable is fixed.
// TODO: Fix FLINK-14844.
for (int i = 0; i < fieldDataTypes.length; i++) {
LogicalType lt = fieldDataTypes[i].getLogicalType();
if (lt instanceof TimestampType
&& (((TimestampType) lt).getKind() == TimestampKind.PROCTIME
|| ((TimestampType) lt).getKind() == TimestampKind.ROWTIME)) {
int precision = ((TimestampType) lt).getPrecision();
fieldDataTypes[i] = DataTypes.TIMESTAMP(precision);
}
}
}
return TableSourceUtil.getSourceRowType(flinkTypeFactory,
tableSchema,
scala.Option.empty(),
isStreamingMode);
}
}
CatalogBaseTable接口定义如下, Flink的Table的参数(schema参数,connector参数)都可以最终表示为一个map.
public interface CatalogBaseTable { /**
* Get the properties of the table.
*
* @return property map of the table/view
*/
Map<String, String> getProperties();
/**
* Get the schema of the table.
*
* @return schema of the table/view.
*/
TableSchema getSchema();
/**
* Get comment of the table or view.
*
* @return comment of the table/view.
*/
String getComment();
/**
* Get a deep copy of the CatalogBaseTable instance.
*
* @return a copy of the CatalogBaseTable instance
*/
CatalogBaseTable copy();
/**
* Get a brief description of the table or view.
*
* @return an optional short description of the table/view
*/
Optional<String> getDescription();
/**
* Get a detailed description of the table or view.
*
* @return an optional long description of the table/view
*/
Optional<String> getDetailedDescription();
}
FlinkSchema的使用
上面都是的相关接口都是Flink用于适配calcite框架元数据的相关实现。
那么这些类具体是在哪里调用的? 已经什么时候会被调用到?
calcite中的schema,主要是在validate过程中, 获得对应table的字段信息, 对应的function的返回值信息,
确保SQL的字段名, 字段类型是正确的.
类的依赖关系为:
validator ---> schemaReader ---> schema
FlinkPlannerImpl.scala中
private def createSqlValidator(catalogReader: CatalogReader) = { val validator = new FlinkCalciteSqlValidator(
operatorTable,
catalogReader,
typeFactory)
validator.setIdentifierExpansion(true)
// Disable implicit type coercion for now.
validator.setEnableTypeCoercion(false)
validator
}
PlanningConfigurationBuilder.java
private CatalogReader createCatalogReader( boolean lenientCaseSensitivity,
String currentCatalog,
String currentDatabase) {
SqlParser.Config sqlParserConfig = getSqlParserConfig();
final boolean caseSensitive;
if (lenientCaseSensitivity) {
caseSensitive = false;
} else {
caseSensitive = sqlParserConfig.caseSensitive();
}
SqlParser.Config parserConfig = SqlParser.configBuilder(sqlParserConfig)
.setCaseSensitive(caseSensitive)
.build();
return new CatalogReader(
rootSchema,
asList(
asList(currentCatalog, currentDatabase),
singletonList(currentCatalog)
),
typeFactory,
CalciteConfig.connectionConfig(parserConfig));
}
综上所诉, 我们就知道了Flink是如何来利用calcite的schema来管理Flink的table信息的.
以上是 FlinkSQL源码阅读schema管理 的全部内容, 来源链接: utcz.com/z/534264.html