mysql相关知识整理(参考《高性能MySQL》)

2.事务的隔离级别
1.未提交读:事务的修改,即使没有提交,对其他事务也都是可见的。(有脏读可能性)
2.已提交读:一个事务从开始直到提交之前,所作的任何修改对其他事务都是不可见。(有不可重复读可能性)
3.可重复读:同一个事务多次读取同样的记录是一致的。(有幻读可能性)。MySQL的默认隔离级别,InnoDB采用了MVCC(多版本并发控制)解决了幻读的问题。
4.可串行化:强制事务串行执行,避免幻读。会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁竞争的问题。一般很少用到,效率比较低。
3.死锁
两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源。
4.事务日志
使用事务日志,存储引擎在修改表的数据只需要修改其内存拷贝,再把修改行为记录到事务日志中(事务日志采用的是追加的方式),事务日志持久化以后,内存中被修改的数据在后台可以慢慢地刷回到磁盘。修改数据需要写两次磁盘。
5.索引的数据结构
1.B+Tree:所有的值都是按顺序存储,并且每个叶子页到根的距离都相同。
2.Hash:基于哈希表实现,只有精确匹配索引所有列的查询才有效。
6.索引的类型
1.普通索引 2.唯一索引 3.主键索引 4.全文索引
7.索引的策略
1.独立的列(单个索引):索引的列不能是表达式的一部分,也不能是函数的参数,否则索引会失效。(不要对索引进行计算)
2.前缀索引:选择足够长的前缀保证较高的选择性,前缀的选择性应该接近于完整列的‘基数’;一个常见的场景是针对十六进制唯一ID使用前缀索引,采用长度为8的前缀索引通常能显著的提升性能。
3.多列索引(组合索引):最左原则;通常情况下,当不需要考虑排序和分组时,将选择性最高的列放在最前面是最好的。但是性能不只是依赖于所有索引列的选择性,也和查询条件的具体值有关,也就是与值的分布有关。可能需要根据那些运行频率最高的查询来调整索引列的顺序。
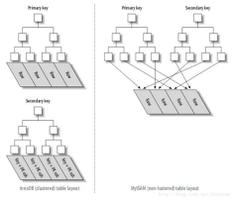
4.聚簇索引:并不是单独的索引类型,而是一种数据存储方式。叶子页中保存了索引值和数据行。InnoDB引擎中,主键索引通常为聚簇索引,若没有主键,则选择一个唯一非空索引代替。如果没有这样的索引,则会隐式的定义一个主键来作为聚簇索引。
5.非聚簇索引:也就是二级索引。聚簇索引的缺点之一:非聚簇索引的叶子节点中包含了引用行的列的主键列,通过非聚簇索引访问需要二次索引查找。因为非聚簇索引叶子节点中保存的不是行的物理位置,而是行的主键值,存储引擎需要先从叶子节点中获取对应的主键值,在根据这个主键值去聚簇索引中查找对应的列。
6.覆盖索引:一个索引包含所需要查询字段的值,就称之为覆盖索引(索引的叶子节点包含了要查询的数据)。覆盖索引对于InnoDB的聚簇索引特别有用,如果二级索引能够覆盖查询,则可以避免对主键索引的二次查询。
8.查询性能的优化
1.慢查询原因
1.是否向数据库请求了不需要的数据。(比如查询返回的所有的列)
2.是否扫描的额外的记录(响应时间、扫面的行数、返回的行数);通过检查慢日志记录找出扫描行数过多的查询是个好方法。
2.重构查询方法
1.切分查询:将一个大的DELETE查询语句,切分成多个较小的查询。
2.分解关联查询:将一个关联查询分解为多个查询,在应用层做关联查询。(充分利用缓存)
3.优化特定的查询
1.优化limit查询:当limit查询时,偏移量过大时,MySQL会扫描大量不需要的行然后在抛弃。可采用‘延迟关联’,先查询出主键,在通过主键去查询(聚簇);或者,若知道上一次去取数据的位置,可先通过where取过滤,在limit操作。
今天就到这了。。。
以上是 mysql相关知识整理(参考《高性能MySQL》) 的全部内容, 来源链接: utcz.com/z/533814.html

![Mysql必知必会挑战题和一些乱七八糟东西
[数据库教程]](/wp-content/uploads/thumbs/688113_thumbnail.jpg)