Explain详解

执行计划中输出各列:
table:查询语句中包含的表
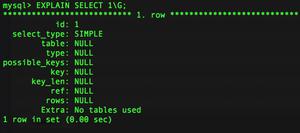
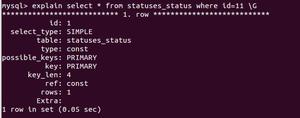
id:查询语句中的每个SELECT都对应一个唯一id值,对于连接查询,id是相同的,第一条为驱动表,第二条为被驱动表;对于子查询来说,id可能不同,查询优化器可能将子查询转换为连接查询;对于union子句,会在内部建立临时表去重,因此出现id为null的结果。
select_type:
SIMPLE:查询语句不包含UNION或子查询均算作SIMPLE类型
PRIMARY:对于多个小查询组成的大查询,最左边的查询就是PRIMARY
UNION:对于UNION和UNION ALL查询,除最左边查询均为UNION
UNION RESULT:使用临时表完成去重工作时,针对临时表的查询即UNION RESULT
SUBQUERY:子查询不能转换为semi-join且子查询时不相关子查询时,通过物化方案执行子查询时,该子查询的第一个SELECT关键字代表的查询就是SUBQUERY
DEPENDENT SUBQUERY:子查询不能转换为semi-join且子查询时相关子查询时,该子查询的第一个SELECT关键字代表的查询就是DEPENDENT SUBQUERY
DEPENDENT UNION:在UNION和UNION ALL大查询中,如果各个小查询均依赖于外层查询,除最左边的小查询,其余小查询均为DEPENDENT UNION
DERIVED:对于采用物化的方式执行的包含派生表的查询,该派生表对应的子查询的select_type就是DERIVED
MATERIALIZED:当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,该子查询对应的select_type属性就是MATERIALIZED
UNCACHEABLE SUBQUERY:对于外层的主表,子查询不可被物化,每次都需要计算(耗时操作)
UNCACHEABLE UNION:UNION操作中,内层的不可被物化的子查询
partitions:
type:执行查询时的访问方法,包含InnoDB存储引擎进行单表访问的方法
system:表中只有一条记录且该表的存储引擎统计数据是精确的
const:根据主键或唯一二级索引进行等值匹配时
eq_ref:连接查询时,被驱动表通过主键或唯一二级索引等值匹配进行访问
ref:根据普通二级索引与常量匹配查询某个表
fulltext:全文索引
ref_or_null:根据普通二级索引与常量匹配且该索引列可以为null
index_merge:使用索引合并进行查询
unique_subquery:查询可以用到主键等值匹配且优化器将IN查询转EXISTS
index_subquery:查询可以用到普通索引等值匹配且优化器将IN查询转EXISTS
range:使用索引获取范围区间
index:当使用覆盖索引,但需要扫描全部的索引记录时
ALL:全表扫描
possible_keys和key:可能使用到的索引和实际使用到的索引。可能使用到的索引越多,优化器计算查询成本也就越高,索引应该删除不使用的索引
key_len:优化器使用索引执行查询时,索引记录的最大长度
ref:当使用索引列等值匹配条件查询时,如果访问方法是const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery之一时,ref标识与索引列做等值匹配的是什么。
rows:表示预计需要扫描的索引记录行数。
filtered:执行单表扫描时,驱动表扇出时满足搜索条件的记录数。
以上是 Explain详解 的全部内容, 来源链接: utcz.com/z/533770.html