mysql explain的用法(使用explain优化查询语句)
首先我来给一个简单的例子,然后再来解释explain列的信息。
表一:catefory 文章分类表:
CREATE TABLE IF NOT EXISTS `category` (
`id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=MyISAM
INSERT INTO `test`.`category` VALUES (NULL , '分类1');
INSERT INTO `test`.`category` VALUES (NULL , '分类2');
INSERT INTO `test`.`category` VALUES (NULL , '分类3');
表二:article文章表:
CREATE TABLE IF NOT EXISTS `article` (
`aid` int(11) NOT NULL,
`cid` int(11) NOT NULL,
`content` text NOT NULL,
PRIMARY KEY (`aid`),
KEY `cid` (`cid`)
) ENGINE=MyISAM
INSERT INTO `test`.`article` (`aid`, `cid`, `content`) VALUES ('', '7', '(jb51.net)教程');
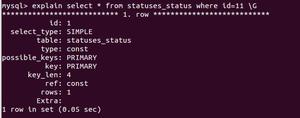
执行explain:
EXPLAIN SELECT name, content
FROM category, article
WHERE category.id = article.cid
得到结果:

EXPLAIN列的解释:
id:选定的执行计划中查询的序列号。表示查询中执行select子句或操作表的顺序,id值越大优先级越高,越先被执行。id相同,执行顺序由上至下。
select_type:查询类型 说明
1、SIMPLE:简单的select查询,不使用union及子查询
2、PRIMARY:最外层的select查询
3、UNION:UNION中的第二个或随后的select查询,不依赖于外部查询的结果集
4、DEPENDENT UNION:UNION中的第二个或随后的select查询,依赖于外部查询的结果集
5、UNION RESULT: UNION查询的结果集SUBQUERY子查询中的第一个select查询,不依赖于外部查询的结果集
6、DEPENDENT SUBQUERY:子查询中的第一个select查询,依赖于外部查询的结果集DERIVED用于from子句里有子查询的情况。
MySQL会递归执行这些子查询,把结果放在临时表里。
7、UNCACHEABLE SUBQUERY:结果集不能被缓存的子查询,必须重新为外层查询的每一行进行评估
8、UNCACHEABLE UNION:UNION中的第二个或随后的select查询,属于不可缓存的子查询
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL
all: full table scan ;mysql将遍历全表以找到匹配的行;
index : index scan; index 和 all的区别在于index类型只遍历索引;
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值的行,常见与between ,< ,>等查询;
ref:非唯一性索引扫描,返回匹配某个单独值的所有行,常见于使用非唯一索引即唯一索引的非唯一前缀进行查找;
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用于主键或者唯一索引扫描;
const,system:当mysql对某查询某部分进行优化,并转为一个常量时,使用这些访问类型。如果将主键置于where列表中,mysql就能将该查询转化为一个常量。
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows:MYSQL认为必须检查的用来返回请求数据的行数
Extra:关于MYSQL如何解析查询的额外信息。将在表4.3中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢。
因为真正的优化会考虑到大数据,我会在后面写更详细的优化教程,今天累了!分享一个详细的mysql explain语法及使用教程(Mysql_Explain_语法详细解析.pdf)!
以上是 mysql explain的用法(使用explain优化查询语句) 的全部内容, 来源链接: utcz.com/p/227921.html