Spark中Broadcast的理解

广播变量
应用场景:在提交作业后,task在执行的过程中,
有一个或多个值需要在计算的过程中多次从Driver端拿取时,此时会必然会发生大量的网络IO,
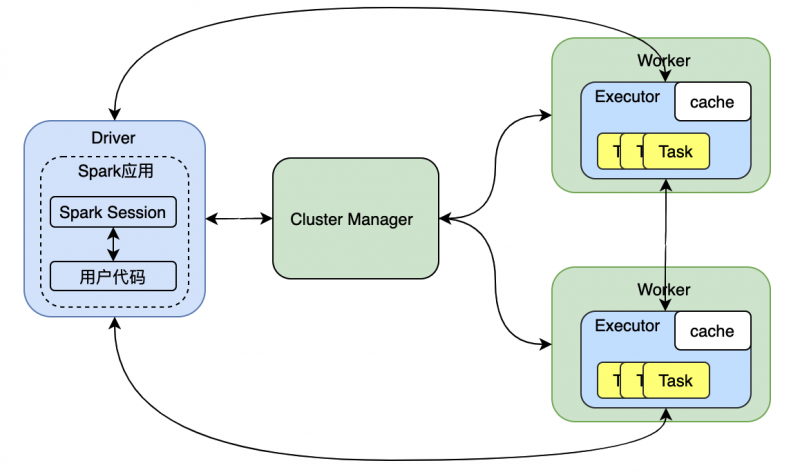
这时,最好用广播变量的方式,将Driver端的变量的值事先广播到每一个Worker端,
以后再计算过程中只需要从本地拿取该值即可,避免网络IO,提高计算效率。
广播变量在广播的时候,将Driver端的变量广播到每一个每一个Worker端,一个Worker端会收到一份仅一份该变量的值
注意:广播的值必须是一个确切的值,不能广播RDD(因为RDD是一个数据的描述,没有拿到确切的值),
如果想要广播RDD对应的值,需要将该RDD对应的数据获取到Driver端然后再进行广播。
广播的数据是不可改变的。
广播变量的数据不可太大,如果太大,会在Executor占用大量的缓存,相对于计算的时候的缓存就少很多。
以上是 Spark中Broadcast的理解 的全部内容, 来源链接: utcz.com/z/533561.html