hadoop伪分布配置

任务配置说明:
VMware 15
Centos 6.5
java -jdk 1.8
hadoop-2.6.0-cdh5.14.0.tar.gz
自行安装虚拟机
第二步 开始大配置
修改主机名和用户名
vim /etc/sysconfig/network --(将HOSTNAME=) 改为master(主机的意思)vim /etc/hosts --(增加一行内容 ip master)
配置静态ip
vim /etc/sysconfig/network-scripts/ifcfg-eth0修改内容如下:
DEVICE=eth0 (网卡名称)
HWADDR=00:0C:29:63:C3:47
TYPE=Ethernet
UUID=7cce5090-6637-40fc-a47e-9f5e2d561b46
ONBOOT=yes (必须设置 设置启动)
NM_CONTROLLED=yes
BOOTPROTO=static (静态)
IPADDR=192.168.65.21 --(你的ip)
NETMASK=255.255.255.0 --(子网掩码)
GATEWAY=192.168.65.1 --(网关)
DNS1=114.114.114.114 --(DNS)
配置SSH无密码连接
关闭防火墙
service iptables stop --(仅一次性关闭防火墙 再次开机防火墙就重新开启了)chkconfig iptables off --(永久关闭防火墙 防止重启防火墙自启动)
配置 SSH
安装 ssh
yum install ssh
安装 rsync
yum install rsync
启动 SSH 服务命令
service sshd restart检查 ssh 是否已经安装成功 可以执行 rpm -qa | grep openssh
出现
[hadoop代表成功
检查 rsync 是否安装成功 可执行 rpm -qa | grep rsync
出现
[hadoop代表成功
生成 SSH 公钥 (只可以生成当前执行用户的秘钥)
ssh-keygen -t rsa --(连续回车即可)ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop(用户名)验证 ssh master
4.配置 java 环境
安装 Java jdk
卸载初始系统存在的jdk
检查 是否安装了jdk
rpm -qa | grep jdk如果出现了返回值 那么使用 yum -y remove xxx(将返回值输入即可)
安装 JDK (需要实现上传)
tar -zxvf jdk-8u221-linux-x64.tar.gz --(解压压缩包)修改环境配置文件
vim /etc/profile
文件末尾添加
#java --(注释代表java)
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_221 --(你java安装目录)
export PATH=$PATH:$JAVA_HOME/bin
让配置文件修改后生效
source /etc/profile
验证 java是否安装成功 --(输入java命令即可)
[hadoop@master jdk1.8.0_221]$ java如若返回一大页东西则安装成功 java -version可以查看当前java版本信息
5.配置 hadoop 环境
老样子 先解压
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz
修改配置文件信息
进入 hadoop 配置文件目录 cd /home/hadoop/app/hadoop-2.6.0-cdh5.14.0/etc/hadoop/
修改 hadoop-env.sh 文件 末尾追加以下内容
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_221export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.14.0
修改 core-site.xml 文件
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>修改 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/app/hadoop-2.6.0-cdh5.14.0/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/app/hadoop-2.6.0-cdh5.14.0/hdfs/data</value>
</property>
</configuration>修改 mapred-site.xml
可以看到我们目录中没有mapred-site.xml 我们可以通过模板拷贝出来一个
cp mapred-site.xml.template mapred-site.xmlvim mapred-site.xml
添加如下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8080</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>修改 slaves
master
至此,Hadoop 安装配置工作全部完成,为了能在任何路径下使用 Hadoop 命令,还需要配置环境变量
对 /etc/profile 追加如下信息
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.14.0
export PATH=$PATH:$HADOOP_HOME/bin对 环境配置文件生效
[hadoop@master hadoop]$ source /etc/profile
在第一次启动 Hadoop 之前,必须对 HDFS 格式化,执行命令
[hadoop
第三步
启动 Hadoop
格式化 Hadoop 完成后,便可以启动 hadoop ,不过首先我们赋予脚本可执行权限
[hadoop然后就可以启动集群了 执行启动脚本 --(进入hadoop的sbin脚本目录)
[hadoop执行脚本
[hadoop最后检查要启动的节点是否正常启动
[hadoop至此 一切完成
第四步
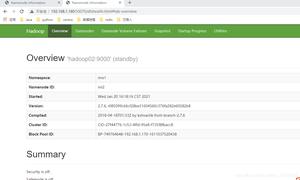
我们可以打开浏览器查看我们的HDFS
如果 linux 有浏览器可以通过浏览器地址输入
master:50070 --(即可访问)如果 想在windows访问 打开浏览器
linuxip:50070
例如我的:192.168.65.21:50070
大功告成了
以上是 hadoop伪分布配置 的全部内容, 来源链接: utcz.com/z/533327.html