【赵强老师】搭建Hadoop环境

说明:这里我们以本地模式和伪分布模式伪列,为大家介绍如何搭建Hadoop环境。有了这个基础,大家可以自行搭建Hadoop的全分布模式。
需要使用的安装介质:
- hadoop-2.7.3.tar.gz
- jdk-8u181-linux-x64.tar.gz
- rhel-server-7.4-x86_64-dvd.iso
一、安装前的准备工作
- 安装好Redhat Linux 7.4(安装包rhel-server-7.4-x86_64-dvd.iso),并在Linux上创建tools和training两个目录
- 关闭防火墙,执行下面的命令
systemctl stop firewalld.servicesystemctl disable firewalld.service
- 配置主机名,使用vi编辑器编辑文件/etc/hosts,输入以下内容
bigdata111 192.168.157.111
- 配置免密码登录,在命令行中输入下面的命令
ssh-keygen -t rsassh-copy-id -i .ssh/id_rsa.pub root@bigdata111
二、安装JDK
- 通过FTP工具将jdk-8u181-linux-x64.tar.gz和hadoop-2.7.3.tar.gz上传到Linux的/root/tools目录
- 在xshell中,解压jdk-8u181-linux-x64.tar.gz,执行下面的命令
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /root/training/
- 设置Java的环境变量,使用vi编辑器编辑~/.bash_profile文件。执行下面的命令
vi /root/.bash_profile
- 在vi编辑器中,输入以下内容
JAVA_HOME=/root/training/jdk1.8.0_181export JAVA_HOME
PATH=$JAVA_HOME/bin:$PATH
export PATH
- 生效环境变量,执行下面的命令
source /root/.bash_profile
- 输入下图中,红框中的命令验证Java环境
三、解压Hadoop,并设置环境变量
- 执行下面的命令,解压hadoop-2.7.3.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
- 设置Hadoop的环境变量,编辑~/.bash_profile文件,并输入以下内容
HADOOP_HOME=/root/training/hadoop-2.7.3export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
- 生效环境变量
source ~/.bash_profile
四、搭建Hadoop的本地模式
- 进入目录/root/training/hadoop-2.7.3/etc/hadoop
- 使用vi编辑器编辑文件:hadoop-env.sh
- 修改JAVA_HOME
export JAVA_HOME=/root/training/jdk1.8.0_181
- 测试Hadoop的本地模式,执行MapReduce程序。准备测试数据:vi ~/temp/data.txt
- 输入下面的数据,并保存退出
- 进入目录:/root/training/hadoop-2.7.3/share/hadoop/mapreduce
- 执行WordCount任务
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /root/temp /root/output/wc
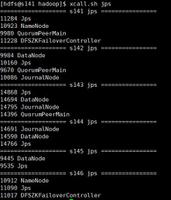
- 根据下图的命令,查看输出结果
五、搭建Hadoop的伪分布模式
- 首先,搭建好Hadoop的本地模式
- 创建目录:/root/training/hadoop-2.7.3/tmp
mkdir /root/training/hadoop-2.7.3/tmp
- 进入目录:/root/training/hadoop-2.7.3/etc/hadoop
cd /root/training/hadoop-2.7.3/etc/hadoop
- 修改hdfs-site.xml
<property><name>dfs.replication</name>
<value>1</value>
</property>
- 修改core-site.xml
<!--配置NameNode的地址--><!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property>
<!--HDFS对应的操作系统目录-->
<!--默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
- 修改mapred-site.xml(注意:这个文件默认没有)
<property><name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 修改yarn-site.xml
<!--配置ResourceManager的地址--><property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property>
<!--MapReduce运行的方式是洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- 格式化NameNode
hdfs namenode -format
- 启动Hadoop
start-all.sh
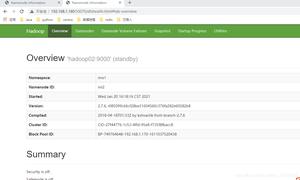
- 访问Web Console
http://192.168.157.111:50070http://192.168.157.111:8088
以上是 【赵强老师】搭建Hadoop环境 的全部内容, 来源链接: utcz.com/z/532983.html