MySQL优化之索引

SQL为什么需要优化?
对于初学者来说,能够写出实现功能的SQL语句而不出错,查询出所需要的结果,就已经能够满足日常使用了。但在某些场景,对性能的要求比较高,因此,要求SQL的执行响应速度快,就需要对SQL进行一定程度的优化。
在实际应用场景中,MySQL经常会存在诸如性能低、执行时间过长、等待时间过长、SQL语句欠佳(尤其是连接查询)、索引失效、服务器参数设置不合理等问题,这时候就需要对SQL进行优化,从而达到我们所需要的的性能需求。
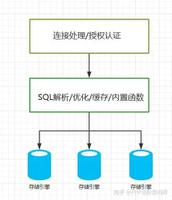
SQL解析过程
要对SQL进行优化,首先需要知道SQL的解析过程是什么样子的。在此之前,我们要明确SQL编写过程和解析过程的区别。
SQL编写过程
select [distinct] ... from ... join ... on ... where ... group by ... having ... order by ... limit ...;SQL解析过程
from ... on ... join ... where ... group by ... having ... select [distinct] ... order by ... limit ...;以上语法中sql关键字的含义,不是本文的重点,网络上有很多教程,此处不再说明,我们只需要知道,SQL的编写过程和实际解析过程并不是一致的。这点在后续的相关优化中将会进一步说明。
索引
索引相当于字典的目录,其目的是帮助在MySQL中更快的查询到所需要的数据。其本质是一种BTREE的数据结构。
所以可以得出一个结论:索引是一种数据结构。 如果您对数据结构有所了解,可以更明白的讲,索引是一种叫树的数据结构。树有很多种,如二叉树,哈希树等。索引是B树(和二叉树比较类似)。
举个例子说明:
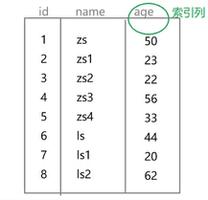
假设我们有一张表student,其结构及其中的数据如下:
id name score
1
zs
75
2
ls
82
3
ww
62
4
ll
88
5
wq
77
6
wb
53
其中,score列是索引。那么,该索引的大致结构是如下图所示的样子:
因此,如果有这样一条SQL:
select score from student where score = 77;如果没有索引,那么需要全表扫描,从第一条数据开始,需要到第5次才能查找到我们所需要的数据;而如果有了索引,则只需要3次就能查找到(75->62->77),由此可见,索引确实能够提升查询效率,尤其是当表中的数据量特别大,达到了百万级别,甚至千万级别的时候,索引的优势就更加明显。
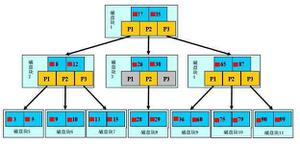
Btree除了常见的二叉树,还有三叉树,三叉树的结构如下所示:
Btree一般指的都是B+树。实际上,索引的数据全部存储在叶节点中,这也就意味着,对于Btree中,查询任意数据的次数都是n次(n为树的深度)。
由于客户端和服务器之间主要是通过IO,所以索引会大大降低IO的使用率,并且能一定程度的降低CPU的使用率。(比如SQL语句中有order by,由于索引的数据结构本身就是排好序的,所以直接省去了这一步,从而降低CPU使用率)。
索引固然有诸多好处,但也有一定的弊端:
- 索引本身很大,因为它本身也是数据结构,存储时必然要占空间;
- 索引不是所有情况均适用
- 少量数据(数据量少,比如只有一条数据,没有必要通过索引查询)
- 频繁更新的字段(因为索引是B树,频繁更新的字段除了要更新该字段本身,还得更新索引的值,甚至会引起索引结构的变动)
- 很少使用的列(很少使用,意味着不经常查询,设置索引意义不大)
- 索引确实可以提高查询的效率,但会降低增删改的效率(因为对数据增删改,同时会引起索引的变动,需要额外对索引进行增删改。而实际应用中,因为查询使用到的场景远远多于增删改,所以索引还是有存在的必要的)。
索引分类:
- 单值索引:单列的值,一张表可以有多个单值索引。
- 唯一索引:不能重复(unique index)
- 复合索引:多个列构成的索引,相当于书的二级目录。(不是100%多个索引同时用)
- 主键索引:如果一个字段设置为主键(primary key),则默认是主键索引,因此主键索引也不能重复。
主键索引和唯一索引的区别是:主键索引列的值不能为null,唯一索引列的值可以为null。
索引常见操作
创建索引:
create 索引类型 索引名 on 表(字段)alter table 表明 add 索引类型 索引名(字段)
删除索引:
drop index 索引名 on 表名查询索引:
show index from 表名以本文中的student表为例,加以说明:
mysql> desc student;+-------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+----------------+
| id | int(4) | NO | PRI | NULL | auto_increment |
| name | char(20) | YES | | NULL | |
| score | double | YES | | NULL | |
+-------+----------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
在student表上对name字段创建单值索引stu_idx1:
mysql> create index stu_idx1 on student(name);Query OK, 0 rows affected (0.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
在student表上对id字段创建唯一索引stu_idx2:
mysql> create unique index stu_idx2 on student(id);Query OK, 0 rows affected (0.20 sec)
Records: 0 Duplicates: 0 Warnings: 0
在student表上对name,score字段创建复合索引stu_idx3:
mysql> create index stu_idx3 on student(name,score);Query OK, 0 rows affected (0.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
使用alter的方式对student表的score字段创建单值索引stu_idx4:
mysql> alter table student add index stu_idx4(score);Query OK, 0 rows affected (0.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
查看创建的索引:
mysql> show index from student;+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 6 | NULL | NULL | | BTREE | |
|
| student | 0 | stu_idx2 | 1 | id | A | 6 | NULL | NULL | | BTREE | |
|
| student | 1 | stu_idx1 | 1 | name | A | 6 | NULL | NULL | YES | BTREE | |
|
| student | 1 | stu_idx3 | 1 | name | A | 6 | NULL | NULL | YES | BTREE | |
|
| student | 1 | stu_idx3 | 2 | score | A | 6 | NULL | NULL | YES | BTREE | |
|
| student | 1 | stu_idx4 | 1 | score | A | 6 | NULL | NULL | YES | BTREE | |
|
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
6 rows in set (0.00 sec)
从以上表格,可以读出以下信息:
- 第一条数据,索引名是PRIMARY,这条索引不是手动创建的,而是建表时因为指定了id为primary key,因此自动创建的主键索引;
- 第11列Index_type可以看出索引的数据结构均为BTREE;
- 第4、5条数据索引名都为stu_idx3,索引序号Seq_in_index分别为1和2,因此,这两个是一对,代表是一个复合索引。
- Non_unique值为0,代表是唯一索引(或主键索引),为1代表不是唯一索引,也就是说该索引列的值可以重复。
假如要删除索引stu_idx2和stu_idx4,则执行如下语句:
mysql> drop index stu_idx2 on student;Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> drop index stu_idx4 on student;
Query OK, 0 rows affected (0.09 sec)
Records: 0 Duplicates: 0 Warnings: 0
再次查询:
mysql> show index from student;+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 6 | NULL | NULL | | BTREE | |
|
| student | 1 | stu_idx1 | 1 | name | A | 6 | NULL | NULL | YES | BTREE | |
|
| student | 1 | stu_idx3 | 1 | name | A | 6 | NULL | NULL | YES | BTREE | |
|
| student | 1 | stu_idx3 | 2 | score | A | 6 | NULL | NULL | YES | BTREE | |
|
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
4 rows in set (0.00 sec)
索引的一些注意事项
创建索引需要注意的事项:
- 选择表关联(JOIN)的关联条件列;
- 数据查询(WHERE)过滤条件列;
- 重复键值数少的列;
- 复合索引应该将重复键值数少的列放在首字段;
- 如果表的数据比较少(如少于1000行),应根据实际情况评估是否需要创建索引;
- 复合索引字段的个数不建议超过3个;
- 不建议在大字段(如char(100)等字段类型)上创建索引;
- 对于频繁访问的业务表,索引数量不建议超过5个;
- 对于数据很少变化的静态表、历史表,索引数量不建议超过8个;
使用索引需要注意的事项:
- 避免在索引上进行运算;
- 避免使用 in 和 not in;
- 尽量不适用like;
- 避免在索引列上使用函数;
- 避免在索引上使用 is null或 is not null;
- 避免使用 !=, >, < 等符号;
- 避免改变索引列的类型;
- 避免使用having子句;
- 对于复合索引,应按照索引中字段的顺序编制查询条件 ;
以上这些已经涉及到后面的索引优化范畴,这里大概有个印象,在下一篇文章中会详细讲述。
唯一索引和主键的区别:
- 一张表里可以有多个唯一索引,但只能有一个主键;
- 主键保证记录唯一且非空(null),唯一索引只能保证记录唯一,可以为空(null);
- 主键一定是唯一索引,但唯一索引可以不是主键;
- 主键可以被其他表引为外键,唯一索引不可以;
- 主键是约束,不占空间,唯一索引是数据结构,是表的冗余结构,占存储空间,这是二者的本质区别。
以上是 MySQL优化之索引 的全部内容, 来源链接: utcz.com/z/532903.html