mysql常见笔试题

一、Mysql常见笔试题
1、Mysql 中有哪几种锁?
(1)表级锁:开销小,加锁快。不会出现死锁,锁定粒度大,发生锁冲突的概率高,并发度低。
(2)行级锁:开销大,加锁慢。会出现死锁,锁定粒度小,发生锁冲突的概率低,并发度高。
(3)页面锁:开销时间、加锁时间、锁定粒度在 表级锁 与 行级锁 之间,会出现死锁,并发度中等。
2、CHAR 与 VARCHAR 的区别?
(1)CHAR 长度不可变,范围 1~255。若存储长度未达到定义的长度,则以 空格 填充。存取速度快,但容易浪费空间。
(2)VARCHAR 长度可变,范围 1~65535。若存储长度未达到定义的长度,则存实际长度数据。存取速度稍慢,但节约空间。
3、ACID 属性?
事务:数据库中,对数据的一系列操作可以看成一个整体,称为事务。这个整体要么全部执行、要么全部不执行。
ACID 属性的存在确保了 事务的可靠。
(1)Actomicity(原子性):原子性要求 事务中的操作要么全部完成,要么回退成之前未操作的状态。即事务中某个操作失败后,会相当于什么都没发生,不会出现改了部分数据的情况。
(2)Consistency(一致性):一致性要求 事务执行前后,数据库的状态一致,即从一个一致性状态切换到另一个一致性的状态。
(3)Isolation(隔离性):隔离性要求 并发的事务相互隔离、不可见。即一个事务看不见另一个事务内部的操作以及操作的数据。
(4)Durability(持久性):持久性要求 事务对数据库数据的修改是永久的。即数据一旦修改提交后,其状态将永久不变。
4、并发问题 -- 脏读、不可重复读、幻读?
对于同时运行的多个事务,若这些事务访问同一数据时,没有采用必要的隔离机制,则会造成如下的并发问题。
(1)脏读:脏读 指的是当一个事务正在访问某数据,并对这个数据进行的修改,且这条数据还未提交到数据库中,此时若另一个事务也访问到这条数据,获取到的是这条被修改的数据,此时得到的数据不对,即脏读。
比如:tom 年龄为 22,事务 A 修改 tom 年龄为 30,此时还未提交到数据库,此时事务 B 获取 tom 年龄,得到的是 30,事务 A 回滚数据,数据库的数据依旧是 22,但事务 B 拿到的数据是 30,这就是脏读,读错了数据。
(2)不可重复读:指一个事务,多次读取同一条数据,在这个事务还未结束时,另一个事务也访问该数据并对其修改,那么可能造成事务多次读取的数据不一致,即不可重复读。
比如:tom 年龄为 22,事务 A 读取 tom 年龄为 22,事务未结束。此时事务 B 修改 tom 年龄为 30,并提交到数据库,当事务 A 再次读取 tom 年龄为 30,事务 A 两次读取的数据不一致,即不可重复读。
(3)幻读:指事务并不是独立执行时产生的现象。一个事务修改某个表,涉及表的所有行,同时另一个事务也修改表,比如增加或删除一条数据。此时第一个事务发现多出或者少了一条数据。这种情况就是幻读。
比如:事务 A 查询当前表的数据总数为 11, 此时事务 B 向表中插入一条数据,事务 A 再次查询当前表数据总数为 12,即幻读。
注:
不可重复读、幻读理解起来有些类似。
不可重复读是对一条数据操作,重点在于修改某条数据。
幻读是对表进行操作,重点在于新增或删除某条数据。
5、事务的隔离级别?
数据库系统必须具有隔离并发运行的事务的能力,使各事务间不会相互影响,避免并发问题。
隔离级别:指的是一个事务与其他事务的隔离程度。隔离级别越高,则并发能力越弱。
(1)Read Uncommitted(读未提交):即读取到 未提交的内容。
一般不使用。此隔离级别下,查询不会加锁,即可能存在两个事务操作同一个表的情况。可能会导致 “脏读”、“不可重复读”、“幻读”。
(2)Read Committed(读提交):即只能读取到 已提交的内容。
常用(oracle、SQL Server 默认隔离级别)。此隔离级别下,查询采用 快照读 的机制,即不会读取到未提交的数据,从而避免 “脏读”,但是仍可能导致 “不可重复读”、“幻读”。
(3)Repeatable Read(可重复读)
常用(mysql 默认隔离级别)。此隔离级别下,查询采用 快照读 的机制,且事务启动后,当前数据不能被修改,从而可以避免 “不可重复读”,但是仍可能导致 “幻读”(新增或删除某条数据)。
(4)Serializable(串行化)
一般不使用。此隔离级别下,事务会串行化执行(排队执行),执行效率差、开销大。可以避免 “脏读”、“不可重复读”、“幻读“。
【举例:】select @@transaction_isolation;
-- 用于查看当前数据库的隔离级别(8.0版本)set session transaction isolation level read committed;
--用于设置隔离级别为 read committed
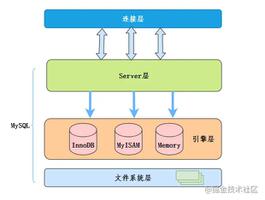
6、Mysql 中表类型 MyISAM 与 InnoDB 的区别?
Mysql 采用 插件式的表存储引擎 管理数据,基于表而非基于数据库。
常见存储引擎(表类型):MyISAM 与 InnoDB。
(1)MyISAM:不支持事务,但是每次查询都是原子的。支持表级锁,即每次操作都是对整个表加锁。存储表的总行数。
(2)InnoDB:支持 ACID 属性,支持事务的四种隔离级别。支持行级锁以及外键约束。不存储表的总行数。
7、自增主键、UUID?
(1)自增主键,数据在物理结构上是顺序存储,性能好,占用空间小。可以是 int 和 bigint 类型。int 4字节,bigint 8 字节,项目中理论不应出现 自增主键达到最大值的情况,因为数据太大,效率会大大降低,当出现一定的数据量后,应进行分库分表操作。
(2)UUID,数据在物理结构上是随机存储,性能较差,占用空间大。唯一ID,绝不冲突。
8、mysql 的约束分类?
(1)约束的作用:是一种限制,用于限制表中的数据,为了保证数据的准确性以及可靠性。
(2)约束分类:
NOT NULL,非空,用于保证某个字段不为空。支持列级约束。
DEFAULT,默认,用于保证某个字段具有默认值。支持列级约束。
PRIMARY KEY,主键,用于保证某个字段具有唯一性且非空。支持列级约束以及表级约束。
UNIQUE,唯一,用于保证某个字段具有唯一性。支持列级约束以及表级约束。
FORGIEN KEY,外键,用于限制两个表间的关系。支持表级约束。
注:
列级约束:指的是定义列的同时指定的约束。
表级约束:指的是列定义之后指定的约束。
外键常用于一对多的关系。即表的某条数据,对应另外一张表的多条数据。
将 “一” 的一方称为 :主表。将 “多” 的一方称为 :从表。
通常将 外键 置于从表上,即 从表上增加一列作为外键,并依赖于主表的某列。
【举例:】员工与部门间的关系。
一个部门可以有多个员工,而一个员工属于一个部门。此时部门与员工间为 一对多 的关系。
部门表为主表,员工表为从表。外键建立在 员工表(从表)上。
CREATE TABLE dept (
-- 此处的 primary key 为 列级约束。deptId
int primary key auto_increment,deptName varchar(
20) not null);
CREATE TABLE emp (
id
int primary key auto_increment,name varchar(
32),age
int,deptId
int,-- 此处的 foreign key 为表级约束。foreign key(deptId) references dept(deptId)
);
9、drop、delete 与 truncate 的区别:
(1)格式:
droptable 表名; -- 用于删除数据表。truncatetable 表名; -- 用于删除数据表的数据,但保留表结构。
deletefrom 表名 [where 条件]; -- 用于删除数据标的数据,但保留表结构,可回滚。
(2)delete 与 truncate 相比较:
delete 可以添加删除条件,truncate 不可以。delete 删除后可以回滚,truncate 不可以。delete 效率较低,truncate 效率较高。delete 可以返回受影响的行数,truncate 没有返回值。delete 删除数据后再次插入数据时,标识列从断点处开始,truncate 标识列从 1 开始。
10、隐式事务、显式事务?
隐式事务:事务没有明显的开启与关闭的标志。比如 insert、delete、update等语句会自动提交。
显式事务:事务具有明显的开启与关闭的标志,前提需禁用自动提交功能。
show variables like "autocommit"; -- 用于查看自动提交功能是否打开set autocommit=1; -- 用于打开自动提交功能
set autocommit=0; -- 用于关闭自动提交功能
【显式事务步骤:】
Step1:开启事务,关闭自动提交功能。
set autocommit=0;
Step2:编写事务语句。
select、insert、delete、update。
SAVEPOINT A; -- 可以设置回滚点
Step3:结束事务。
commit; -- 提交事务
rollback; -- 回滚事务
rollbackto A; -- 回滚到回滚点
11、视图
(1)视图:是一种虚拟存在的表,其数据是使用视图的过程中动态创建的数据,其只保存 sql 逻辑,不保存查询的结果数据。
注:
可以理解成 java 的封装好的一段方法,直接调用即可。
(2)格式:
【创建视图】CREATEVIEW 视图名AS查询语句;
【使用视图(与使用普通表类似)】
SELECT*FROM 视图名
【举例:】
CREATEVIEW testView
AS
SELECT*
FROM DEPT;
SELECT*
FROM testView;
【修改视图:(方式一)】
-- 若视图存在则修改,若视图不存在则创建
CREATEORREPLACEVIEW 视图名
AS
查询语句;
【修改视图:(方式二)】
ALTERVIEW 视图名
AS
查询语句;
【删除视图:】
dropview 视图名;
(3)好处:
可以重用 sql 语句。
简化复杂的 sql 操作,不必清楚查询细节。
保护数据,提高安全性。
12、变量
(1)系统变量:变量由系统提供。可以细分为 全局变量(global,针对数据库的所有连接))以及 会话变量(session,默认,仅针对当前连接)。
【查看当前所有的变量:】show
[global | session] variables;【查看部分变量:】
show
[global | session] variables like"%transaction%";【查看具体的变量:】
select @@[global | session].变量名;【设置具体的变量】
set[global | session] 变量名 = 值;或者
set @@[global | session].变量名;
(2)自定义变量:变量由用户自定义。可以细分为 用户变量(针对当前连接,声明的位置任意)以及 局部变量(仅在begin ~ end 块中使用,且声明的位置为 begin ~ end 块的第一句话)。
========================用户变量===========================【声明用户变量并赋值:(三种方式)】
set@变量名=值;set@变量名:=值;select@变量名:=值;【赋值给用户变量:(通过select
into)】select 字段 into@变量名from 表;
【查看用户变量值:】
select@变量名;
【举例:】
selectcount(*) into@count
from dept;
select@count;
========================局部变量===========================
【声明局部变量:】
declare 变量名 类型;
declare 变量名 类型 default 值;
【局部变量赋值:(先声明再赋值,直接赋值会出错)】
set 变量名=值;
set 变量名:=值;
select 字段 into 变量名
from 表;
【查看用户变量值:】
select 变量名;
13、存储过程
(1)存储过程:
指的是 一组预先编译好的 sql 语句的集合,可以理解成批处理语句。类似于 Java 中的方法,使用时调用方法名即可。
(2)好处:
提高了代码的重用性。
简化操作。
减少了编译次数、与数据库交互的次数,提高了效率。
(3)语法:
【创建存储过程:】DELIMITER $
CREATEPROCEDURE 存储过程名(参数列表)BEGIN存储过程体(一组合法的 sql 语句)
END $DELIMITER ;
注:
参数列表分三个部分,分别为 参数模式、参数名、参数类型
参数模式:
IN、OUT、INOUT。IN:指该参数可以作为输入,即接收值(默认)。OUT:指该参数可以作为输出,即返回值。
INOUT:指该参数即可作为输入、又可作为输出。
存储过程体中每条语句必须以分号 ; 结尾。
DELIMITER 用于设置结束标记,用于存储过程末尾,执行到标记处则存储过程结束。
【调用存储过程:】
CALL 存储过程名(参数列表);
【删除存储过程:】
DROPPROCEDURE 存储过程名;【查看存储过程结构:】
SHOW
CREATEPROCEDURE 存储过程名;
(4)举例:
# 创建一个 user 表,若已经存在该表,先删除DROPTABLEIFEXISTSuser;CREATETABLEuser(id
INTPRIMARYKEY AUTO_INCREMENT,name
VARCHAR(20),password
VARCHAR(20));
# 用于设置结束标记,此处 sql 结束标记有 ; 改为 $
DELIMITER $
# 创建存储过程(无参),用于向
user 表中插入 5 个数据DROPPROCEDUREIFEXISTS user_no_parameter $CREATEPROCEDURE user_no_parameter()BEGININSERTINTOUSER(name, password) VALUES("tom", "tom123"),("jarry", "jarry123"),("jack", "jack123"),("tim", "tim123"),("rose", "rose123");
END $
# 创建有参存储过程,根据输入的用户名,找到相应的密码,并返回该用户的 id。
DROPPROCEDUREIFEXISTS user_parameter $
CREATEPROCEDURE user_parameter(IN name VARCHAR(20), OUT password VARCHAR(20), INOUT id INT)
BEGIN
SELECTuser.password, user.id INTO password, id
FROMuser
WHEREuser.name = name;
END $
# 用于设置结束标记,此处 sql 结束标记有 $ 改为 ;
DELIMITER ;
# 调用无参存储过程
CALL user_no_parameter();
# 查看当前表数据
SELECT*FROMuser;
# 调用有参存储过程
set@id=0;
CALL user_parameter("jack", @password, @id);
# 查看有参存储过程执行后的结果
SELECT@password, @id;
14、函数
(1)函数:
与存储过程类似,也是一组预先编译好的 sql 语句的集合。
注:
与存储过程的区别:
存储过程可以没有返回值,可以有多个返回值,适合进行批处理(批量插入、删除等)。
函数有且仅有一个返回值,一般用于处理数据并返回一个结果。
(2)语法:
【创建函数:】DELIMITER $
CREATEFUNCTION 函数名(参数列表) RETURNS 返回类型BEGIN函数体(一组合法的 sql 语句)
END $DELIMITER ;
注:
参数列表分两个部分,分别为 参数名、参数类型。
函数体必须包含
return 语句。【调用函数:】
SELECT 函数名(参数列表);【查看函数:】
DROPFUNCTION 函数名;【删除函数:】
SHOW
CREATEFUNCTION 函数名;
(3)举例:
# 用于设置结束标记,此处 sql 结束标记有 ; 改为 $DELIMITER $
# 创建无参函数,若函数已存在,则先删除再创建
DROPFUNCTIONIFEXISTS test1 $CREATEFUNCTION test1() RETURNSINTBEGIN
DECLARE a INTDEFAULT10;
DECLARE b INTDEFAULT10;
return a + b;
END $
# 创建有参函数,若函数已存在,则先删除再创建
DROPFUNCTIONIFEXISTS test2 $
CREATEFUNCTION test2(a INT, b INT) RETURNSINT
BEGIN
RETURN a - b;
END $
# 用于设置结束标记,此处 sql 结束标记有 $ 改为 ;
DELIMITER ;
# 调用无参函数
SELECT test1();
# 调用有参函数
SELECT test2(20, 10);
注:
若出现错误 ERROR 1418 (HY000),修改 log_bin_trust_function_creators 值即可。
【错误:】ERROR
1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration andbinary logging is enabled (you *might* want touse the less safe log_bin_trust_function_creators variable)【解决:】
SET GLOBAL log_bin_trust_function_creators =1;
15、流程控制语句
(1)IF 语句
【语法1:(IF 函数)】IF(表达式1, 结果1, 结果2);注:
表达式
1 成立,则返回 结果1.表达式
1 不成立,则返回 结果2.【语法2:需要写在
BEGIN-END 中】BEGINIF 表达式 1THEN 结果 1;
ELSEIF 表达式 2THEN 结果 2;
ELSE 结果 3;
ENDIF;
END
【举例:】
DELIMITER $
DROPFUNCTIONIFEXISTS test3 $
CREATEFUNCTION test3() RETURNSINT
BEGIN
IF2>3THENRETURN3;
ELSEIF 2>4THENRETURN4;
ELSERETURN5;
ENDIF;
END $
DELIMITER ;
SELECT test3() value1, IF(2>3, 2, 3) value2;
(2)CASE 语句
【语法1:相当于 Java 中的 switch 语句】CASE 表达式 | 变量WHEN 值 1THEN 返回的结果 1WHEN 值 2THEN 返回的结果 2
ELSE 返回的结果 3
END
【语法2:相当于 Java 中的 IF-ELSE 语句】
CASE
WHEN 表达式 1THEN 返回的结果 1
WHEN 表达式 2THEN 返回的结果 2
ELSE 返回的结果 3
END
【举例:】
SELECT (
CASE2+3
WHEN2THEN2
WHEN3THEN3
ELSE4
END
) value1,
(
CASE
WHEN2>3THEN2
WHEN2<3THEN3
ELSE4
END
) value2;
(3)循环
【分类:需要放在 BEGIN-END 里】while、loop、repeat【循环标志:】
iterate: 类似于 Java 中的
continue,结束本次循环,进行下一次循环。leave: 类似于 Java 中的
break,结束当前所有的循环。【
while 语法:(先判断再执行循环)】BEGIN[标签:]WHILE 循环条件 DO
循环体;
ENDWHILE[标签];
END
【loop 语法:(没有条件的死循环,需使用 leave 退出)】
BEGIN
[标签:] LOOP
循环体;
END LOOP [标签];
END
【repeat 语法:(先执行循环再判断)】
BEGIN
[标签:] REPEAT
循环体;
UNTIL 结束循环的条件
END REPEAT [标签];
END
【举例:】
DELIMITER $
DROPPROCEDUREIFEXISTS test1 $
CREATEPROCEDURE test1(OUT a INT, OUT b INT, OUT c INT)
BEGIN
# 测试 while 循环,temp>=10 时退出循环。
DECLAREtempINTDEFAULT0;
testWhile: WHILEtemp<10 DO
SETtemp=temp+1;
# 当 temp=8 时,给 a 赋值并退出 while 循环
IFtemp=8THENSET a =temp; LEAVE testWhile;
ENDIF;
ENDWHILE testWhile;
# 测试 repeat 循环, temp>=10 时退出循环。
SETtemp=0;
testRepeat: REPEAT
SETtemp=temp+1;
# 当 temp=7 时,给 b 赋值并退出 repeat 循环
IFtemp=7THENSET b =temp; LEAVE testRepeat;
ENDIF;
# 注意 until 是循环结束条件
UNTIL temp>=10
END REPEAT testRepeat;
# 测试 loop 循环
SETtemp=0;
testLoop: LOOP
SETtemp=temp+1;
# 当 temp=6 时,给 c 赋值并退出 loop 循环
IFtemp=6THENSET c =temp; LEAVE testLoop;
ENDIF;
END LOOP testLoop;
END $
DELIMITER ;
CALL test1(@a, @b, @c);
SELECT@a, @b, @c;
以上是 mysql常见笔试题 的全部内容, 来源链接: utcz.com/z/532569.html