SQL点滴系列之删除数据(五)

> 本节讲述 在数据库中删除表中的数据,以及 having 与 where 的分析
1 删除表中所有的记录
实际开发中,我们有时需要删除一个表中的所有的数据,我们可以使用 delete 命令来操作
delete from t_user2 删除表中指定的记录
删除表中指定数据或者说是满足某些条件的数据,我们可以使用 where 子句,例如删除表中 年龄小于 18 岁的用户,我们可以这样写
delete from t_user where user_age <18这里使用到的是满足条件的记录,如果要删除单个记录,那么在指定的判断条件一般使用 主关键字或其他唯一的关键字来作为判别条件,例如我们这样写
delete from t_user where user_id =118在这里使用到的 user_id 就是用户表中用户的唯一关键标识,所以这里只是删除了其中一条数据。
3 删除违反参照完整性的记录
例如,某些用户员工被分配到了一个不存在的部门中,要将这些员工删除,那么我们可以使用 not exists 和子查询来判断删除
delete from t_emp e where not exists (
select * from t_dep d where d.did = e.did
)
也可以使用 not in 来查询
delete from t_emp ewhere e.did not in (select d.did from t_dep d)
> t_emp 表用来保存被分配部门的用户信息数据
> t_dep 表用来保存部门信息
4 删除表中的重复记录
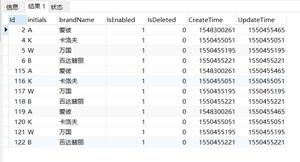
例如在表 t_dup 中有这样的数据
我们想保留一个 name 为张三的记录,其他 name 为张三的记录,不需要关心 id 是多少,最终表中只有一条有关张三的记录,我们可以这样写
delete from t_dup where id not in (select min(id) from t_dup group by name)
在 MySQL 中,使用上述写法会有异常
Error : You can"t specify target table "t_dup" for update in FROM clause不能先select出同一表中的某些值,再update这个表(在同一语句中),所以在 MySQL 中可以这样写
delete from t_dup where name in (
select t.name from
(
select name from t_dup group by name HAVING count(1) > 1
) t
)
要删除重复记录,首先要明确定义这个重复的概念,也就是说你要删除什么样的重复数据,而在上述的操作中,定义的是 name 是重复的
5 删除从其他表引用的记录
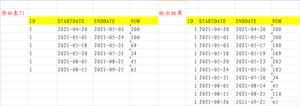
从一个表中删除被另一个表中引用的记录,例如下面的表中记录来了来透支经费的部门,每行记录了透支发生的部门与透支金额以及事由
例如在这里我们需要删除所在部门已经发生了三次以上的透支申请的所有部门的记录,在这里我们可以这样来写
delete from t_emp where dep_id in(select acc_dep_id from t_acc group by acc_dep_id having count(*) >=3)
上述sql 操作中,子查询
select acc_dep_id from t_acc group by acc_dep_id having count(*) >=3)这里用来查询那些发生过三次以上的透支申请的部门,然后 delete 命令将删除由子查询返回的部门。
6 HAVING 关键字一谈
HAVING 子句可以让我们筛选分组后的各组数据,也就是说HAVING语句通常与GROUP BY语句联合使用,用来过滤由GROUP BY语句返回的记录集。
6.1 SQL语言中中的聚合函数
例如 SUM, COUNT, MAX, AVG等这些函数和其它函数的根本区别就是它们一般作用在多条记录上
select sum(acc_count) from t_acc如上 通过 sum 函数来统计 所有部门的透支金额
通过使用 GROUP BY 子句,可以让SUM 和 COUNT 这些函数对属于一组的数据起作用
6.2 显示每个地区的总人口数和总面积
select region, sum(population), sum(area) from t_user_city group by region
先以region把返回记录分成多个组,这就是GROUP BY的字面含义,分完组后,然后用聚合函数 sum 对每组中的不同字段(一或多条记录)作运算。
然后我们在上述的查询结果再进一步筛选,显示每个地区的总人口数和总面积,但人口数量超过1000000的地区,我们可以这样来写
select region, sum(population), sum(area) from t_user_city group by region
having sum(population)>1000000
在这里使用到了 having 来筛选了数据,没有使用 where 关键字,where关键字有个区别是where是group by之前进行条件筛选,而having是group by之后进行条件筛选,我们上述的需求,是需要在分组之后筛选,还有一点就是where后的条件表达式里不允许使用聚合函数,而having可以。
以上是 SQL点滴系列之删除数据(五) 的全部内容, 来源链接: utcz.com/z/532377.html