Zookeeper机制

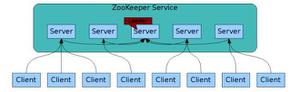
顾名思义 zookeeper 就是动物园管理员,他是用来管 hadoop(大象)、Hive(蜜蜂)、pig(小 猪)的管理员, Apache Hbase 和 Apache Solr 的分布式集群都用到了 zookeeper;Zookeeper: 是一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目。他提供的主要功 能包括:配置管理、名称服务、分布式锁、集群管理。
功能特性
- 最终一致性:client 不论连接到哪个 Server,展示给它都是同一个视图,这是 zookeeper 最重要的性能。
- 可靠性:具有简单、健壮、良好的性能,如果消息 m 被到一台服务器接受,那么它 将被所有的服务器接受。
- 实时性:Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或 者服务器失效的信息。但由于网络延时等原因,Zookeeper 不能保证两个客户端能同时得到 刚更新的数据,如果需要最新数据,应该在读数据之前调用 sync()接口。
- 等待无关(wait-free):慢的或者失效的 client 不得干预快速的 client 的请求,使得每 个 client 都能有效的等待。
- 原子性:更新只能成功或者失败,没有中间状态。
顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消 息 a 后被同一个发送者发布,a 必将排在 b 前面。
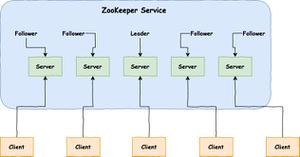
进程角色
- leader:由集群成员投票选举出来的领导者,负责处理外部发到集群的读写请求,处理写请求时会发起投票,只有集群内超过半数节点通过后写操作才会被通过。
- follower:负责处理都请求并返回结果,如果接收到写请求则将之转发给leader,还要负责leader选举时的投票。
observer:可以理解为没有选举权的follower,只负责处理业务,时为了提高集群吞吐率,同时又能保证集群快速完成选举而引进的机制。
机制
- 集群的两种模式
- 恢复模式:集群的一种非稳定状态,集群不能处理外部请求;集群启动或遇到leader崩溃时,集群进入恢复模式,在本模式中选举leader,leader选举完成后其他节点与leader进行数据同步,当过半节点完成同步后恢复模式结束,进入广播模式。
- 广播模式:集群的稳定状态,集群能正常的处理外部请求;此时若有新节点加入,新节点会自动从leader同步数据。
- 集群启动过程:
- leader选举原则
- 集群中只有超过半数的节点处于正常状态,集群才能稳定,才能处理外部请求。
- 集群正常工作之前myid小的节点会优先给myid大的节点投票,直到选出leader为止。
- 选出leader之前,集群所有节点都处于looking状态,选举成功后,除leader节点外,其余节点的状态由looking变为following,角色也成为了follower。
- leader选举过程
- 假设集群有5个节点,myid分别为1~5,假设集群第一次启动,所有节点都没有历史数据,启动顺序1~5。由集群节点数量可知,至少要有3个节点正常,集群才能稳定工作。
- 节点1启动,其初始状态为looking,发起一轮选举,节点1投自己一票,由于不过半,本轮选举无法完成。节点1仍然保持looking状态。
- 节点2启动,其初始状态为looking,它也发起一轮选举,节点2投自己一票;节点1也参与进本轮投票,打算给自己投一票,但是发现节点2的myid比自己的大,就改投节点2一票;本轮投票过后节点1得0票,节点2得2票,由于节点2的得票数不过半,所以本轮选举未能完成;节点1、2都保持looking状态。
- 节点3启动,其初始状态为looking,它也发起一轮选举,且节点3先投自己一票;节点1、2也都参与进本轮投票中来,打算投自己一票,发现本轮中节点3的myid大于自己的,所以节点1、2都转投节点3一票;此时节点3就收获了3票,超过了集群节点的半数,节点3率先当选,并从looking状态变为leading状态。节点1、2的状态变为following。
- 节点4启动,其初始状态为looking,它也发起一轮选举;此时由于节点1、2处于following状态,这两个节点就不参与本轮选举。节点4本打算投自己一票,但是发现节点3已进入leading状态,且票数已经过半,此时节点4就会将自己的一票转投给节点3。节点4未收到投票,状态由looking变为following。
- 节点5的启动过程与节点4一样,最终未获得投票,也处于following状态。
- 最终节点3成为leader,节点1、2、4、5成为follower。
- leader选举原则
- 崩溃恢复过程:当leader崩溃后,集群中的其他follower节点会重新变为looking状态,重新进行leader选举。选举过程同启动时的leader选举一样。
- 消息广播算法:
- leader接收到一个写请求后,leader会给此请求标记一个全局自增的64位事务id(zxid)。
- leader以队列未载体将每个事务依此发送给follower,follower读取也严格遵循队列的顺序,这就避免了paxos算法的全序问题。
- follower在本地缓存了它最新执行的事务的zxid,当接收到新事务后,会取出zxid与本地的zxid做比较,如果接收到的zxid大于本地的就执行此事务并给leader返回确认消息,否则拒绝执行。
当leader接收到过半数量的follower确认消息后,代表着事务已在整个集群中执行,leader就给所有follower发送事务提交指令。
zxid:是一个32+32位的数字;前32位称为epochId,是当前leader的全局自增编号,如果把leader比作皇帝,那epochId则是皇帝的年号。后32位是每个事务特定的标识,相当于皇帝发布的号令,对一个皇帝来说这个编号也是全局自增的。
数据结构
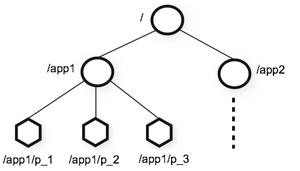
- Znode
在 Zookeeper 中,znode 是一个跟 Unix 文件系统路径相似的节点,可以往这个节点存储 或获取数据。 Zookeeper 底层是一套数据结构。这个存储结构是一个树形结构,其上的每一个节点, 我们称之为“znode” zookeeper 中的数据是按照“树”结构进行存储的。而且 znode 节点还分为 4 中不同的类 型。 每一个 znode 默认能够存储 1MB 的数据(对于记录状态性质的数据来说,够了) 可以使用 zkCli 命令,登录到 zookeeper 上,并通过 ls、create、delete、get、set 等命令 操作这些 znode 节点
- Znode 节点类型
- PERSISTENT 持久化节点: 所谓持久节点,是指在节点创建后,就一直存在,直到 有删除操作来主动清除这个节点。否则不会因为创建该节点的客户端会话失效而消失。
- PERSISTENT_SEQUENTIAL 持久顺序节点:这类节点的基本特性和上面的节点类 型是一致的。额外的特性是,在 ZK 中,每个父节点会为他的第一级子节点维护一份时序, 会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属 性,那么在创建节点过程中,ZK 会自动为给定节点名加上一个数字后缀,作为新的节点名。 这个数字后缀的范围是整型的最大值。 在创建节点的时候只需要传入节点 “/test_”,这样 之后,zookeeper 自动会给”test_”后面补充数字。
- EPHEMERAL 临时节点:和持久节点不同的是,临时节点的生命周期和客户端会 话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提 到的是会话失效,而非连接断开。另外,在临时节点下面不能创建子节点。 这里还要注意一件事,就是当你客户端会话失效后,所产生的节点也不是一下子就消失 了,也要过一段时间,大概是 10 秒以内,可以试一下,本机操作生成节点,在服务器端用 命令来查看当前的节点数目,你会发现客户端已经 stop,但是产生的节点还在。
EPHEMERAL_SEQUENTIAL 临时自动编号节点:此节点是属于临时节点,不过带 有顺序,客户端会话结束节点就消失。
目录结构
- bin:放置运行脚本和工具脚本,如果是 Linux 环境还会有有 zookeeper 的运 行日志 zookeeper.out
- conf:zookeeper 默认读取配置的目录,里面会有默认的配置文件
- contrib:zookeeper 的拓展功能
- dist-maven:zookeeper的 maven 打包目录
- docs:zookeeper 相关的文档
- lib:zookeeper 核心的 jar
- recipes:zookeeper 分布式相关的 jar 包
src:zookeeper 源码
单机部署
Zookeeper 在启动时默认的去 conf 目录下查找一个名称为 zoo.cfg 的配置文件。 在 zookeeper 应用目录中有子目录 conf。其中有配置文件模板,手动拷贝重命名:zoo_sample.cfg cp zoo_sample.cfg zoo.cfg。zookeeper 应用中的配置文件为 conf/zoo.cfg。 修改配置文件 zoo.cfg - 设置数据缓存路径
安装jdk,配置相关环境变量,上传zookeeper压缩包
[zk_hom]# tar -zxvf apache-zookeeper-3.5.5-bin.tar.gz //解压
[zk_hom]# mkdir zkdata //新建一个数据持久化目录
[zk_hom]# cd conf //进入配置目录
[zk_hom/confg]# cp zoo_example.cfg zoo.cfg //复制配置文件样本,并重命名未zoo.cfg
编解zoo.cfg,将其中的dataDir = zk_home/zkdata
[zk_hom/bin]# sh ./zkServer.sh start //启动节点
[zk_hom/bin]# sh ./zkServer.sh status //查看节点状态
集群部署
- 各个节点上的准备工作同单机的一样,都需要jdk,zookeeper压缩包,同时要拷贝配置并配置数据持久化目录,同时为各节点新建持久化目录。
- 不同的是需要在各节点的zookeeper持久化目录中新建一个名为“myid”的文件,文件中各自写上节点编号1~5。
- 配置文件中需要追加集群中其他节点的访问地址:
【server.myid = ip:通信端口:选举端口】
server.1 = 192.168.50.1:2181:3181
server.2 = 192.168.50.2:2181:3181
server.3 = 192.168.50.3:2181:3181
server.4 = 192.168.50.4:2181:3181
server.5 = 192.168.50.5:2181:3181
启动各个节点
应用管理
bin/zkServer.sh start //开启服务
bin/zkServer.sh status //查看服务状态
bin/zkServer.sh stop //停止服务端
bin/zkCli.sh -server 192.168.199.175:2181 //使用客户端连接服务端
客户端命令
应用场景
- 配置管理
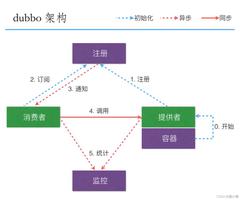
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都 是使用配置文件的方式,在代码中引入这些配置文件。当我们只有一种配置,只有一台服务 器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多, 有很多服务器都需要这个配置,这时使用配置文件就不是个好主意了。这个时候往往需要寻 找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的 都可以获得变更。Zookeeper 就是这种服务,它使用 Zab 这种一致性协议来提供一致性。现 在有很多开源项目使用 Zookeeper 来维护配置,比如在 HBase 中,客户端就是连接一个 Zookeeper,获得必要的 HBase 集群的配置信息,然后才可以进一步操作。还有在开源的消 息队列 Kafka 中,也使用 Zookeeper来维护broker的信息。在 Alibaba开源的 SOA 框架Dubbo 中也广泛的使用 Zookeeper 管理一些配置来实现服务治理。
- 名称服务
名称服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的 IP 地址,但是 IP 地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是 不能是域名的。怎么办呢?如果我们每台机器里都备有一份域名到 IP 地址的映射,这个倒 是能解决一部分问题,但是如果域名对应的 IP 发生变化了又该怎么办呢?于是我们有了 DNS 这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应 的 IP 是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候, 如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都 熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
- 分布式锁
其实在第一篇文章中已经介绍了 Zookeeper 是一个分布式协调服务。这样我们就可以利 用 Zookeeper 来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠 性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服 务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进 行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即 fail over 到另外的服务。这在很多分布式系统 中都是这么做,这种设计有一个更好听的名字叫 Leader Election(leader 选举)。比如 HBase 的 Master 就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所 以使用的时候要比同一个进程里的锁更谨慎的使用。
- 集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些 节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机 器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系 统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目 前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一 个分布式的 SOA 架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用 某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如 Alibaba 开源的 SOA 框架 Dubbo 就采用了 Zookeeper 作为服务发现的底层机制)。还有开源的 Kafka 队列就 采用了 Zookeeper 作为 Cosnumer 的上下线管理。
- 负载均衡的集群管理
以上是 Zookeeper机制 的全部内容, 来源链接: utcz.com/z/532326.html