Spark内存管理

1、spark的一大特性就是基于内存计算,Driver只保存任务的宏观性的元数据,数据量较小,且在执行过程中基本不变,不做重点分析,而真正的计算任务Task分布在各个Executor中,其中的内存数据量大,且会随着计算的进行会发生实时变化,所以Executor的内存管理才分析的重点。
2、在执行Spark应用程序时,集群会启动Driver和Executor两种JVM进程,前者为主控进程,负责创建spark上下文(context),提交spark作业(job),将作业转化为计算任务(task),在各个Executor进程间协调任务的调度。后者负责在工作节点上执行具体任务,并将结果返回给Driver,同时为需要持久化的RDD提供存储功能。
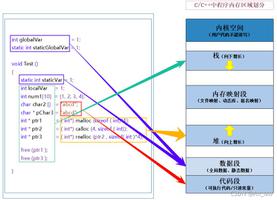
3、作为一个JVM进程,Executor的内存管理时基于JVM内存管理机制的,spark对JVM-on-heap内存进行了更为详细的规划,以充分利用。同时spark还引入了off-heap内存,使之可以直接从运行节点的系统内存中开辟空间,进一步优化内存的使用。
【堆内存的分配和回收完全依赖JVM的gc机制,应用不能灵活的操作内存,使用堆外内存则可以通过OS来分配和释放,较为灵活】
早期静态内存管理:on-heap分为四个区域,分别是Storage(20%)、Execution(60%)、Other(20%)、Ext,Storage用于缓存持久化的RDD数据和广播变量等,Execution用于缓存shuffle过程中产生的中间数据,Other区用于存储运行中的其他对象,Ext是一块较小的预留空间,用以防止OOM的发生,起到兜底作用,几个区块间有严格的界限,不可逾越。off-heap分为两个区,Storage(50%)、Execution(50%),也有严格界限,不可逾越。
spark1.6后引入统一内存管理:与静态管理机制的不同在于初始Storage(50%)、Execution(50%),在执行过程中两个区域可以根据自己和对方的内粗余量弹性的越界分配,更加灵活高效。off-heap也是两个区域,没有严格界限可以动态占用。
4、内存的动态占用:
0.存储 < 50% && 执行 < 50%:互不占用
1.存储 > 50% && 执行 > 50%:溢写磁盘(前提是缓存级别包含磁盘,若级别为纯内存则丢弃数据)
2.存储 > 50% && 执行 < 50%:存储跨界借用,若一段时间后执行内存不足,则删除被借用内存,优先满足执行的内存需要。
3.存储 < 50% && 执行 > 50%:执行跨界借用,若一段时间后存储内存不足,则不能被执行占用的存储区内存,因为执行的优先级更高,要优先保证执行数据。
***
5、统一内存管理机制,有效的提高了堆内存和堆外内存的使用效率,降低了使用复杂度,但是并不能就此高枕无忧。由于RDD数据往往是长期生存的,如果存储在内存中的数据过多,会引发频繁的full-gc,降低了程序的吞吐量。
以上是 Spark内存管理 的全部内容, 来源链接: utcz.com/z/532319.html