MongoDB(八):索引

1. 索引
索引支持查询的有效地提高效率。没有索引,MongoDB必须扫描集合的每个文档,以选择与查询语句匹配的文档。这种扫描效率很低,需要MongoDB处理大量的数据。
索引是特殊的数据结构,以易于遍历的形式存储数据集的一小部分。 索引存储特定字段或一组字段的值,按照索引中指定的字段值排序。
1.1 索引案例
首先创建大量数据。
向集合中插入10万条文档。
for(i=0;i<100000;i++){db.t1.
insert({name:"test"+i, age:i})}
然后进行数据查找性能分析。
查找姓名为"test10000"的文档。
db.t1.find({name:"test10000"})使用explain()命令进行查询性能分析。
db.t1.find({name:"test10000"}).explain("executionStats")其中的executionStats下的executionTimeMillis表示整体查询时间,单位是毫秒。
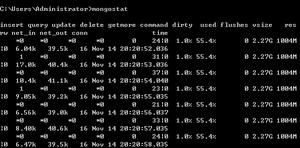
性能分析结果如下:
然后我们创建索引。
1表示升序,-1表示降序。
db.集合.ensureIndex({属性:1})如
db.t1.ensureIndex({name:
1})执行上面相同的查询,并进行查询性能分析。
db.t1.find({name:"test10000"}).explain("executionStats")性能分析结果如下:
1.2 ensureIndex()方法
创建索引,需要使用MongoDB的ensureIndex()方法。
语法:
db.COLLECTION_NAME.ensureIndex({KEY:1})这里的key是要在其上创建索引的字段的名称。
ensureIndex()方法也接受选项列表(可选)。
以下是列表:
参数 类型 描述
background
Boolean
在后台构建索引,以便构建索引不会阻止其他数据库活动,则指定background的值为true。默认值为false。
unique
Boolean
创建一个唯一的索引,使得集合不会接受索引键或键匹配索引中现有值的文档的插入。 指定true以创建唯一索引。 默认值为false。
name
String
索引的名称。如果未指定,则MongoDB通过连接索引字段的名称和排序顺序来生成索引名称。
dropDups
Boolean
在可能有重复项的字段上创建唯一索引。MongoDB仅索引第一次出现的键,并从集合中删除包含该键的后续出现的所有文档。指定true以创建唯一索引。 默认值为false。
sparse
Boolean
如果为true,则索引仅引用具有指定字段的文档。这些索引在某些情况下(特别是排序)使用的空间较小,但行为不同。默认值为false。
expireAfterSeconds
integer
指定一个值(以秒为单位)作为TTL,以控制MongoDB在此集合中保留文档的时间。
v
索引版本
索引版本号。默认索引版本取决于创建索引时运行的MongoDB的版本。
weights
文档
权重是从1到99999之间的数字,并且表示该字段相对于其他索引字段在分数方面的意义。
default_language
String
对于文本索引,确定停止词列表的语言以及句柄和分词器的规则。 默认值为英文。
language_override
String
对于文本索引,要指定文档中包含覆盖默认语言的字段名称。默认值为language。
1.3 索引的命令
建立唯一所有,实现唯一约束的功能。
db.t1.ensureIndex({"name":1},{"unique":true})联合所有,对多个属性建立一个索引,按照find()出现的顺序。
db.t1.ensureIndex({name:1,age:1})查看文档所有索引。
db.t1.getIndexes()
查看集合索引大小。
db.t1.totalIndexSize()
删除索引。
db.ti.dropIndexes("索引名称")
删除集合所有索引。
db.t1.dropIndexes()
以上是 MongoDB(八):索引 的全部内容, 来源链接: utcz.com/z/531863.html