SQL索引碎片的产生,处理过程。

本文参考
https://www.cnblogs.com/CareySon/archive/2011/12/22/2297568.html
https://www.jb51.net/softjc/126055.html
https://docs.microsoft.com/zh-cn/sql/relational-databases/system-dynamic-management-views/sys-dm-db-index-physical-stats-transact-sql?view=sql-server-ver15
本文需要对“索引”和MSSQL中数据的“存储方式”有一定了解。
软件经常在使用一段时间过后会无缘无故卡顿,这是因为在数据库(MSSQL)频繁的插入和更新的操作过程中会产生分页,在分页的过程中产生碎片导致的。所以,对于碎片需要定时的处理。基本上所有的办法都是基于对索引的重建和整理,只是方式不同。
- 删除索引并重建
- 使用DROP_EXISTING语句重建索引
- 使用ALTER INDEX REBUILD语句重建索引
- 使用ALTER INDEX REORGANIZE
以上方式各有优缺点,下面存储过程主要使用3,4
先看一个整理碎片的存储过程,然后采用作业的方式定时执行。
CreatePROCEDURE[dbo].[proc_rebuild_index]@retINT OUTPUT
AS
SET NOCOUNT ON
BEGIN
DECLARE@fldDefragFragmentINT=10;
DECLARE@fldRebuildFragmentINT=30;
DECLARE@fldMinPageCountINT=1000;
DECLARE@fldTableVARCHAR(256);
DECLARE@fldIndexVARCHAR(256);
DECLARE@fldPercentINT;
DECLARE@SqlVARCHAR(256);
declare@DBIDint;
BEGIN TRY
SET@ret=-1;
set@DBID=db_id();
-- 获取索引碎片状况
DECLARE curIndex CURSOR LOCAL STATIC READ_ONLY FORWARD_ONLY FOR
SELECT
TBL.NAME TABLE_NAME
,IDX.NAME INDEX_NAME
,AVGP.AVG_FRAGMENTATION_IN_PERCENT
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(@DBID, NULL,NULL, NULL, "LIMITED") AS AVGP
INNERJOIN SYS.INDEXES AS IDX
ON AVGP.OBJECT_ID= IDX.OBJECT_ID
AND AVGP.INDEX_ID = IDX.INDEX_ID
INNERJOIN SYS.TABLES AS TBL
ON AVGP.OBJECT_ID= TBL.OBJECT_ID
INNERJOIN SYS.DM_DB_PARTITION_STATS PS
ON AVGP.OBJECT_ID= PS.OBJECT_ID
AND AVGP.INDEX_ID = PS.INDEX_ID
WHERE
AVGP.INDEX_ID >=1
AND AVGP.AVG_FRAGMENTATION_IN_PERCENT >=@fldDefragFragment
AND PS.RESERVED_PAGE_COUNT >=@fldMinPageCount;
-- 打开游标
OPEN curIndex;
-- 获取游标
FETCHNEXTFROM curIndex
INTO@fldTable,@fldIndex,@fldPercent;
WHILE@@FETCH_STATUS=0
BEGIN
--碎片率大于30,重建索引
IF@fldPercent>=@fldRebuildFragment
BEGIN
SET@Sql="ALTER INDEX "+@fldIndex+" ON "+@fldTable+" REBUILD";
EXEC(@Sql);
END
ELSE
--碎片率小于30,重组索引
BEGIN
SET@Sql="ALTER INDEX "+@fldIndex+" ON "+@fldTable+" REORGANIZE";
EXEC(@Sql);
END
-- 获取游标
FETCHNEXTFROM curIndex
INTO@fldTable,@fldIndex,@fldPercent;
END
-- 关闭游标
CLOSE curIndex;
DEALLOCATE curIndex;
SET@ret=0;
END TRY
BEGIN CATCH
SET@ret=-1;
DECLARE@ErrorMessagenvarchar(4000);
DECLARE@ErrorSeverityint;
DECLARE@ErrorStateint;
SELECT
@ErrorMessage= ERROR_MESSAGE()
, @ErrorSeverity= ERROR_SEVERITY()
, @ErrorState= ERROR_STATE();
RAISERROR( @ErrorMessage, @ErrorSeverity, @ErrorState);
RETURN;
END CATCH;
END
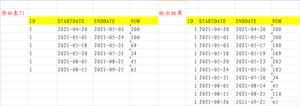
下面直观的看一下碎片产生的过程
--创建测试表ifobject_id("test") isnotnull
droptable test
go
createtable test
(
col1 int,
col2 char(985),
col3 varchar(10)
)
Go
--创建聚焦索引
createCLUSTEREDindex cix on test(col1);
go
--插入数据
declare@varint
set@var=100
while (@var<900)
begin
insertinto test(col1, col2, col3)
values (@var, "xxx", "")
set@var=@var+100
end;
--查看页存储情况
select page_count, avg_page_space_used_in_percent, record_count,
avg_record_size_in_bytes, avg_fragmentation_in_percent, fragment_count,
*from[master].sys.dm_db_index_physical_stats(db_id(), OBJECT_ID("test"), null, null, "sampled")
--然后做更新操作后,继续查看页存储情况。
update test set col3="更新测试"where col1=100
--再次插入数据后查看页存储情况declare@varint
set@var=100
while (@var<900)
begin
insertinto test(col1, col2, col3)
values (@var, "插入测试", "")
set@var=@var+100
end;
--下面看下对碎片整理之前和之后的IOsetstatistics io on
select*from test
alterindex cix on test rebuild
select*from test
setstatistics io off
明显的逻辑读取减少了。从而提高了性能
以上是 SQL索引碎片的产生,处理过程。 的全部内容, 来源链接: utcz.com/z/531605.html