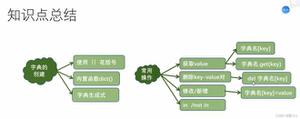
Day2:列表与字典

1.列表:使用[ ]存储
切片:
取列表中的某值,其中元素从0开始,如:取第一个元素,则 列表名[0]
取列表中的某些连续值,如:取第三和第四个元素,则 列表名[2:4] “顾头不顾尾”
取列表中的某些值,如:从头取到尾且步长为2,则 列表名[起始位置:终止位置:步长]
取列表中的最后一个值,则 列表名[-1]
取列表中的最后3个值,则 列表名[-3:](实际上从头取的时候前方也可以省略掉)
插入:
在最后添加元素 列表名.append(元素)
在固定位置添加元素 列表名.insert(位置号,元素)
改写:
改写某元素: 列表名[位置] = 元素
删除:
删除某元素 列表名.remove(元素) 或 del 列表名[位置号] 或 列表名.pop(位置号),使用pop时若不写位置则默认删除最后一个元素
索引:print(列表名.index(元素名)) 输出位置
print(列表名.[列表名.index(元素名)] 输出该元素
计数:列表名.count(元素名)
清空列表: 列表名.clear()
反转列表: 列表名.reverse()
排序列表: 列表名.sort() 排序规则按ASCII码排序规则制定
合并列表: 列表名.extend(要合并的列表名) 执行操作后被合并的列表仍存在,要删除的话需要del 该列表
1import copy 2 names = ["Sun", "Li", "Ji", [1, 3, 5], "Fan"] 34print(names[::3])
5for i in names:
6print(i)
7 name2 = copy.copy(names) # 浅copy
8print(names, name2)
9 name2[2] = "吉"
10 name2[3][1] = 4
11print(names, name2)
12 names.append("Lei") # 在列表末尾插入
13 names.insert(1, "Zhang") # 在列表位置1处插入
14 names[2] = "Xie"# 替换
15 names.remove("Sun") # 删除
16 names.insert(0, "Sun")
17del names[0] # 删除
18 names[0] = "Sun"
19 names.pop(0) # 删除
20print(names)
21print(names.index("Ji"))
22print(names[names.index("Ji")])
23print(names[1], names[2])
24print(names[0:2]) # 切片
25print(names[3]) # 切片
26print(names[-1]) # 切片
27print(names[-3:]) # 切片
28 names2 = ["1", "2", "3"]
29 names.extend(names2) # 扩展(合并)列表
30print(names)
31 names.reverse() # 翻转列表
32print(names)
33"""names.sort() # 表内数据类型不同时不能排序
34print(names)"""
35 names.clear() # 清空列表
36print(names)
list operate
1 ["Sun", [1, 3, 5]] 2Sun 3Li 4Ji 5 [1, 3, 5] 6Fan 7 ["Sun", "Li", "Ji", [1, 3, 5], "Fan"] ["Sun", "Li", "Ji", [1, 3, 5], "Fan"] 8 ["Sun", "Li", "Ji", [1, 4, 5], "Fan"] ["Sun", "Li", "吉", [1, 4, 5], "Fan"] 9 ["Xie", "Ji", [1, 4, 5], "Fan", "Lei"]10 111Ji
12 Ji [1, 4, 5]
13 ["Xie", "Ji"]
14Fan
15Lei
16 [[1, 4, 5], "Fan", "Lei"]
17 ["Xie", "Ji", [1, 4, 5], "Fan", "Lei", "1", "2", "3"]
18 ["3", "2", "1", "Lei", "Fan", [1, 4, 5], "Ji", "Xie"]
19 []
Output-LO
2.元组
只有两个命令 count , index
3.字符串常用操作
1 name = "My name is {name}, and I"m {age} years-old."2
3print(name.capitalize()) # 首字母大写,其余小写
4print(name.count("s")) # 字符串中某字符出现的次数,可指定开始结束位置
5print(name.casefold()) # 将所有大写字母转换为小写,类似lower()方法
6print(name.center(50, "-")) # 打印50个字符,不够的用-补齐,且将name放于中间
7print(name.endswith("C")) # 判断字符串是否以指定后缀结尾,是True否False,可指定开始结束位置
8print(name.startswith("M")) # 判断字符串是否以指定前缀开始,是True否False,可指定开始结束位置
9print(name.expandtabs(tabsize=0)) # 将字符串中的 转换为指定数量的空格
10print(name.find("name")) # 索引字符(串)的开始位置-可用于字符串切片
11print(name.format(name="SJC", age=18)) # 格式化
12print(name.format_map({"name": "SJC", "age": 18})) # 可传字典格式
13print(name.isalnum()) # 检测字符串是否由字母和数字组成
14print(name.isalpha()) # 检测字符串是否只由字母组成
15print(name.isdecimal()) # 检查字符串是否只包含十进制字符
16print(name.isdigit()) # 检测字符串是否只由数字组成
17print("Name".isidentifier()) # 判断是否是一个合法的标识符(变量名)
18print(name.islower()) # 检测字符串是否由小写字母组成
19print(name.isnumeric()) # 检测字符串是否只由数字组成。这种方法是只针对unicode对象。
20print(name.istitle()) # 检测字符串是否是标题格式
21print(name.isupper()) # 检测字符串是否由大写字母组成
22print(",".join(["1", "2", "3"])) # 将序列(字符串、列表等)中的元素以指定的字符连接生成一个新的字符串 str.join(sequence)
23print(name.ljust(50, "*")) # 打印50个字符,不够的用*补齐,将name放于前方
24print(name.rjust(50, "@")) # 打印50个字符,不够的用*补齐,将name放于后方
25print(name.lower()) # 大写换小写
26print(name.upper()) # 小写换大写
27print("
SJC
".lstrip()) # 从左侧去除空格或回车
28print("
SJC
".rstrip()) # 从右侧去除空格或回测
29print("
SJC
".strip()) # 去除两侧空格或回车
30 p = str.maketrans("SJC", "123")
31# 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标
32# 两个字符串的长度必须相同,为一一对应的关系
33print("SJC".translate(p)) # 用p的映射关系转换字符SJC后输出
34print("baidu.com".partition(".")) # 据指定的分隔符将字符串进行分割
35# 如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
36print("python is funny".replace("n", "*", 1)) # 替换且可指定最大替换次数
37print(name.rfind("a")) # 从左向右查找,找到最右侧的a并返回其位置
38print(name.rsplit())
39print("1+2+3+4".split("+")) # 将字符串按照要求分割为列表(默认为空字符,可指定其他字符),可指定分割次数
40print(name.swapcase()) # 大小写互化
41print(name.title()) # 化成标题格式
42print(name.zfill(50)) # 从左侧用0填充字符串至指定长度
String Operate
1 ["Sun", [1, 3, 5]] 2Sun 3Li 4Ji 5 [1, 3, 5] 6Fan 7 ["Sun", "Li", "Ji", [1, 3, 5], "Fan"] ["Sun", "Li", "Ji", [1, 3, 5], "Fan"] 8 ["Sun", "Li", "Ji", [1, 4, 5], "Fan"] ["Sun", "Li", "吉", [1, 4, 5], "Fan"] 9 ["Xie", "Ji", [1, 4, 5], "Fan", "Lei"]10 111Ji
12 Ji [1, 4, 5]
13 ["Xie", "Ji"]
14Fan
15Lei
16 [[1, 4, 5], "Fan", "Lei"]
17 ["Xie", "Ji", [1, 4, 5], "Fan", "Lei", "1", "2", "3"]
18 ["3", "2", "1", "Lei", "Fan", [1, 4, 5], "Ji", "Xie"]
19 []
Output
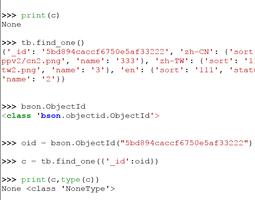
4.字典:一种key – value 的数据类型,使用就像上学用的字典,通过笔画、字母来查对应页的详细内容
1 info = {2"stu1101": "SJC",3"stu1102": "WRR",4"stu1103": "WK"5 }
dic_ex
4.1 字典操作
增改:字典名[key] = value 若键值存在,则改数据;若不存在,则字典内新增一条
删除:del 字典名[key]/字典名.pop(key)
查找:字典名[key] 如果key不存在会报错
字典名.get(key) 通过print输出存在则返回值,不存在则返回None
‘key’ in 字典名-通过print输出False 或 True看key是否存在
查找字典内全部数据:字典名.values()
查找字典内全部键值:字典名.keys()
字典名.setdefault(“key”,”value”):若存在key则返回其值,若不存在则创建新key与值
字典名.update(字典名2) 合并字典,有相同key则覆盖原字典内value
字典名.items() 字典转列表
dict.fromkeys([6,7,8],”test”) 初始化一个字典,有三个key 6, 7 ,8且values全部为test
1 info = { 2"stu1101": "SJC", 3"stu1102": "WRR", 4"stu1103": "WK"5}
6print(info)
7print(info["stu1101"]) # 如果key不存在会报错
8 info["stu1101"] = "ZYH"# key存在则改其value不存在则新增
9print(info)
10print("stu1104"in info) # key存在返回True否则返回False
11print(info.get("stu1104")) # 如果key不存在会返回None
12print(info.values()) # 输出所有value
13print(info.keys()) # 输出所有key
14print(info.items()) # 字典转列表输出
15
16 info2 = {
17"stu1105": "LY",
18"stu1106": "SJC"
19}
20 info.update(info2) # 字典合并有交叉则覆盖
21print(info)
22 info.setdefault("stu1104", "ZJL") # key存在则返回其现有值不存在则创建新值及其value
23print(info)
Operate_ex
1 {"stu1101": "SJC", "stu1102": "WRR", "stu1103": "WK"} 2SJC 3 {"stu1101": "ZYH", "stu1102": "WRR", "stu1103": "WK"} 4False 5None 6 dict_values(["ZYH", "WRR", "WK"]) 7 dict_keys(["stu1101", "stu1102", "stu1103"]) 8 dict_items([("stu1101", "ZYH"), ("stu1102", "WRR"), ("stu1103", "WK")]) 9 {"stu1101": "ZYH", "stu1102": "WRR", "stu1103": "WK", "stu1105": "LY", "stu1106": "SJC"}10 {"stu1101": "ZYH", "stu1102": "WRR", "stu1103": "WK", "stu1105": "LY", "stu1106": "SJC", "stu1104": "ZJL"}
Output
4.2 多级字典
1 world_map = { 2"China": { 3"Hebei": ["Northeast", "flat area"], 4"Yunnan": ["Southwest", "hilly land"] 5 }, 6"Japan": { 7"Tokyo": ["Capital", "qqq"], 8"Osaka": ["South", "ppp"] 9 },10"America": {11"New York": ["Famous of interest", "Statue of Liberty"],12"Washington": ["Capital", "White House"]13 }14}15 world_map["China"]["Hebei"][1] = "Nice"16print(world_map)
Multi_level_dic
4.3 循环字典
1for i in info: # 循环字典,高效,推荐2print(i) # 只打印key
3print(i, info[i]) # 打印key及其value
4
5for k, v in info.items(): # 先将字典转为列表,数据量大时耗时长,不推荐
6print(k, v) # 打印key及其value
dic_circulation
5.练习与作业
# 购物车程序
# 1.启动程序后,让用户输入工资,然后打印商品列表
# 2.允许用户根据商品编号购买商品
# 3.用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
# 4.可随时退出,退出时,打印已购买商品和余额
S1: 自我练习版
1# 购物车程序2# 1.启动程序后,让用户输入工资,然后打印商品列表
3# 2.允许用户根据商品编号购买商品
4# 3.用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
5# 4.可随时退出,退出时,打印已购买商品和余额
6import sys
7
8 goods = ["Phone", "Necklace", "Bike", "MP4", "Ipad", "Cup"]
9 price = [2299, 8200, 1088, 888, 2469, 46] #存两个表,需要一一对应,不方便
10 pychased = []
11 price2 = price.copy()
12price2.sort()
13 salary = int(input("Please tell me your salary here:")) #强转,输入字符串会报错,不推荐
14 doc = salary
15while salary >= (price2[0]):
16for i in range(1, 7):
17print(i, ":", goods[i-1], "", price[i-1])
18 m = input("Please input goods number to buy it(Or input "q" to exit):")
19if m != "q":
20 j = int(m)
21if j < 1 or j > 7:
22print("Wrong goods number,please input again")
23elif salary >= price[j-1]:
24 balance = salary - price[j-1]
25 salary = balance
26 pychased.append(goods[j-1])
27print(f"You have bought {goods[j-1]}, and your balance is {balance}.")
28else:
29print("You don"t have enough money to buy this good, please try another cheaper one!")
30else:
31if salary >= doc:
32print(f"You ha
以上是 Day2:列表与字典 的全部内容, 来源链接: utcz.com/z/531210.html