序列化模块(json、pickle)

序列化模块
1、什么是序列化、反序列化?
序列:指的就是字符串(*****)
序列化:将python或者其他语言的数据类型转换成字符串类型。
python默认数据类型:int、float、str、list、tuple、dict、bool、set
过程:
序列化: 其他数据类型 ---> 字符串 ---> 文件中
反序列化: 文件中 ---> 字符串 ---> 其他数据类型
2、json模块
json是一个序列化模块,是一个“第三方”的特殊数据格式
使用json保存数据:
可以将python数据类型 ---> json数据格式 ---> 字符串 ---> 文件中,
其他语言使用pathon数据:
文件中 ---> 字符串 ---> json数据格式 ---> 其他语言的数据类型
为什么要使用json模块
为了让不同的语言之间数据可以共享
由于各种语言的数据类型不一,但数据一样,比如python不能直接使用其他语言的数据类型,必须将其他语言的数据类型转换成json数据格式,python获取到json数据之后可以将json转换成python的数据类型拿来使用
注意:在json中所有的字符串都是双引号
哪些数据类型可以被序列化?
列表、元组、字典都可以,集合set不可以
json.dumps():
- json.dumps(), f = open(), f.write
# 序列化:.dumps()将python数据 ---> json数据格式 ---> 字符串
json.loads():
- f = open(), str = f.read(), json.loads(str)
# 反序列化:.loads()字符串 ---> json数据格式 ---> python或者其他语言的数据类型
注意:上面两种方法不会内部不能读、写文件,需要手动写代码
例1:使用json模块存、取列表
# 存列表import json
list1 = ["bear", "apple", "orange", "李二狗"]
# .dumps()将python数据 ---> json数据格式 ---> 字符串
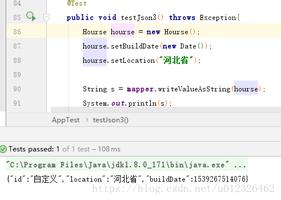
json_list1 = json.dumps(list1, ensure_ascii=False) # ensure_ascii将默认的ascii取消设置为False,可以在控制台看到中文,否则中文显示为bytes类型数据
print(json_list1)
print(type(json_list1)) # 字符串类型
# .loads()字符串 ---> json数据格式 ---> python数据
list2 = json.loads(json_list1)
print(list2)
print(type(list2)) # 列表类型
执行结果:
["bear", "apple", "orange", "李二狗"]<class"str">[
"bear", "apple", "orange", "李二狗"]<class"list">
例2:使用json模块存、取元组
# 存元组import json
tuple1 = ("bear", "apple", "orange", "李二狗")
json_tuple1 = json.dumps(tuple1, ensure_ascii=False) # ensure_ascii将默认的ascii取消设置为False,可以在控制台看到中文,否则中文显示为bytes类型数据
print(json_tuple1)
print(type(json_tuple1)) # 字符串类型
tuple2 = json.loads(json_tuple1)
print(tuple2)
print(type(tuple2)) # 列表类型
执行结果:
["bear", "apple", "orange", "李二狗"]<class"str">[
"bear", "apple", "orange", "李二狗"]<class"list">
例3:使用json模块存、取字典
# 存字典import json
dic1 = {
"name": "坦克",
"age": 18
}
json_dic1 = json.dumps(dic1, ensure_ascii=False)
print(json_dic1)
print(type(json_dic1)) # 字符串类型
dic2 = json.loads(json_dic1)
print(dic2)
print(type(dic2)) # 字典类型
执行结果:
{"name": "坦克", "age": 18}<class"str">{
"name": "坦克", "age": 18}<class"dict">案例:写一个注册功能,将用户名密码存放在字典,然后使用json序列化字典存在本地文件中
# 注册功能import json
def register():
username = input("请输入用户名>>>: ").strip()
password = input("请输入密码>>>: ").strip()
re_password = input("请再次输入密码>>>: ").strip()
if re_password == password:
user_dict = {
"name" : username,
"pwd" : password
}
# 将字典序列化
json_dict = json.dumps(user_dict, ensure_ascii=False)
# 开始写入文件中
# 注意:保存json数据时,用.json作为文件的后缀名,让人见名知意
with open("user.json", "w", encoding="utf-8") as f:
f.write(json_dict)
json.dump(): # 序列化:.dumps()将python数据 ---> json数据格式 ---> 字符串
- 内部实现f.write
json.load(): # 反序列化:.loads()字符串 ---> json数据格式 ---> python或者其他语言的数据类型
- 内部实现f.read()
注意:上面两种方法可以内部读、写文件,无需再写读、写的代码(推荐使用)
例:将字典存放到本地json文件内
# dump,load演示import json
dic2 = {
"username": "坦克",
"age": 17
}
# 写入数据
with open("user.json", "w", encoding="utf-8") as f1:
json.dump(dic2, f1, ensure_ascii=False)
# 读数据
with open("user.json", "r", encoding="utf-8") as f2:
dic3 = json.load(f2)
print(dic3)
执行结果:
{"username": "坦克", "age": 17}3、pickle模块
pickle是一个python自带的序列化模块,
pickle模块可以存集合,但是里面只能含有字符串类型数据
注意:pickle模块存取数据必须以bytes存入
优点:
可以支持python中所有的数据类型
可以直接存bytes类型的数据
存取速度要比json快
缺点(致命的缺点):
只能支持python使用,不能跨平台
例:将集合set1写入以.pickle结尾的文件
import pickleset1
= {"1", "name", "坦克"}# 文件以.pickle命名,二进制写入文件with open("user.pickle", "wb") as f1:
pickle.dump(set1, f1)
# 以二进制读取文件
with open("user.pickle", "rb") as f2:
set2 = pickle.load(f2)
print(set2)
执行结果:
{"坦克", "name", "1"}以上是 序列化模块(json、pickle) 的全部内容, 来源链接: utcz.com/z/530406.html