Python按分类样本数占比生成并随机获取样本数据[Python基础]

按分类样本数占比生成并随机获取样本数据
By:授客 QQ:1033553122
开发环境
win 10
python 3.6.5
需求
已知样本分类,每种分类的样本占比数,及样本总数,需要随机获取这些分类的样本。比如,我有4种任务,分别为任务A,任务B,任务C,任务D, 每种任务需要重复执行的总次数为1000,每次执行随机获取一种任务来执行,不同分类任务执行次数占比为 A:B:C:D = 3:5:7:9
代码实现
#!/usr/bin/env python# -*- coding:utf-8 -*-
__author__ = "shouke"
import random
def get_class_instance_by_proportion(class_proportion_dict, amount):
"""
根据每种分类的样本数比例,及样本总数,为每每种分类构造样本数据
class_proportion_dict: 包含分类及其分类样本数占比的字典:{"分类(id)": 分类样本数比例}
amount: 所有分类的样本数量总和
返回一个列表:包含所有分类样本的list
"""
bucket = []
proportion_sum = sum([weight for group_id, weight in class_proportion_dict.items()])
residuals = {} # 存放每种分类的样本数计算差值
for class_id, weight in class_proportion_dict.items():
percent = weight / float(proportion_sum)
class_instance_num = int(round(amount * percent))
bucket.extend([class_id for x in range(class_instance_num)])
residuals[class_id] = amount * percent - round(amount * percent)
if len(bucket) < amount:
# 计算获取的分类样本总数小于给定的分类样本总数,则需要增加分类样本数,优先给样本数计算差值较小的分类增加样本数,每种分类样本数+1,直到满足数量为止
for class_id in [l for l, r in sorted(residuals.items(), key=lambda x: x[1], reverse=True)][: amount - len(bucket)]:
bucket.append(class_id)
elif len(bucket) > amount:
# # 计算获取的分类样本总数大于给定的分类样本总数,则需要减少分类样本数,优先给样本数计算差值较大的分类减少样本数,每种分类样本数-1,直到满足数量为止
for class_id in [l for l, r in sorted(residuals.items(), key=lambda x: x[1])][: len(bucket) - amount]:
bucket.remove(class_id)
return bucket
class A:
def to_string(self):
print("A class instance")
class B:
def to_string(self):
print("B class instance")
class C:
def to_string(self):
print("C class instance")
class D:
def to_string(self):
print("D class instance")
classes_map = {1: A, 2: B, 3:C, 4: D}
class_proportion_dict = {1: 3, 2: 5, 3:7, 4: 9} # {分类id: 样本数比例} ,即期望4个分类的样本数比例为为 3:5:7:9
class_instance_num = 1000 # 样本总数
result_list = get_class_instance_by_proportion(class_proportion_dict, class_instance_num)
for class_id in class_proportion_dict:
print("%s %s" % (classes_map[class_id], result_list.count(class_id)))
# 制造样本并随机获取样本
random.shuffle(result_list)
while result_list:
class_id = random.sample(result_list, 1)[0]
classes_map[class_id]().to_string()
result_list.remove(class_id)
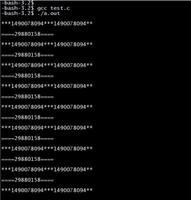
运行结果
说明
以上方式大致实现思路就是在知道总样本数的情况下,提前为每种分类生成样本,然后随机获取,按这种方式可以实现比较准确的结果,但是得提前知道样本总数及不同分类样本数占比
以上是 Python按分类样本数占比生成并随机获取样本数据[Python基础] 的全部内容, 来源链接: utcz.com/z/530027.html