如何使用python爬虫新闻?

现在时事是人们最在意的话题,而且对于新闻行业来说,掌握第一手新闻资料,可是独家新闻,大爆炸,其他圈子小编不清楚,但是娱乐圈,想必大家都知道吧,像第一手资料的狗仔,一直是人们津津乐道的话题,所以怎么去获取第一手资料呢,大家可以跟着小编来学习下,最新新闻的获取内容哦~
首先,打开开发者模式,分析网页。
具体做法:按F12,并用ctrl+f对elements进行搜索,关键字为新闻内容的几个字即可。
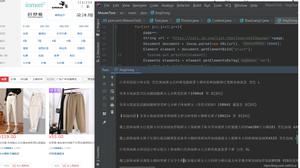
找到内容文字
利用这个方法,我们很轻松就找到了新闻文字内容的位置,通过分析发现其内容都为p标签下的字符串,并且其class="one-p",这可以作为定位该内容的唯一特征。
通过以上的分析,我们确定了定位关键信息的方法,接下来就可以编写python程序了:
实例代码:
# -*- coding:utf-8 -*-import requests
from bs4 import BeautifulSoup
url = "https://new.qq.com/omn/20190704/20190704A0EHMR00.html"r = requests.get(url)
rr = r.content
bs = BeautifulSoup(rr,"lxml")
news_contents = bs.find_all("p",{'class':'one-p'})
news_final = ""for i in news_contents:
print(i.string)
if i.string:
news_final = news_final +i.string + "
"f = open("news_contents.txt",'w')
f.write(news_final)
f.close()
最终打开保存的文件,里面就是获取的新闻内容了哦~
大家可以利用小编的这个方法,去找到想要找的内容文字,方法不仅简单,还很容易操作,直接复制粘贴即可哦~如果还想了解其他内容,可以到网上去查询哦~
以上是 如何使用python爬虫新闻? 的全部内容, 来源链接: utcz.com/z/528418.html