Python教程:pdfminer抓取PDF中的内容

之前学过pdfminer模块的小伙伴,今天就派上大用场了。本文将通过pdfminer举例,轻松抓取PDF中的内容。
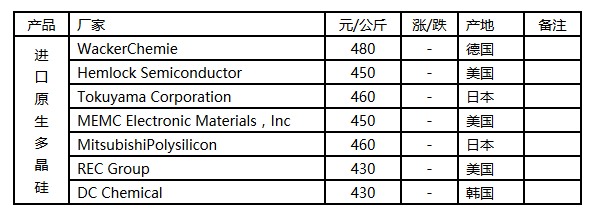
转换 PDF 有很多库可以完成,如下是通过 pdfminer 的示例:
from cStringIO import StringIOfrom pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
def convert_pdf_2_text(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec='utf-8', laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
with open(path, 'rb') as fp:
for page in PDFPage.get_pages(fp, set()):
interpreter.process_page(page)
text = retstr.getvalue()
device.close()
retstr.close()
return text
需要指出的是,pdfminer 不但可以将 PDF 转换为 text 文本,还可以转换为 HTML 等带有标签的文本。上面只是最简单的示例,如果每页有很独特的标志,你还可以按页单独处理。
看完后是不是觉得很简单呢?pdfminer不会的小伙伴可以点击以往的文章学习:进阶PDF,就用Python(pdfminer.six和pdfplumber模块)
以上是 Python教程:pdfminer抓取PDF中的内容 的全部内容, 来源链接: utcz.com/z/528350.html