pythonu开头的字符串乱码怎么解决

python处理u开头的字符串
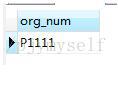
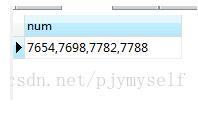
是用python处理excel过程中,从表格中解析除字符串,打印出来的中文却显示成了u'开头的乱码字符串,在控制台中输出的编码格式是
utf-8,而excel表格的数据也是utf-8编码成的,但是解析成字符串则是成了一个unicode编码组成的字符串,“u”后的16进制字符串是
相应汉字的utf-16编码,所以我们需要将这写字符串解码成unicode字符串。
使用decode("unicode_escape")
#!/usr/bin/python# -*- coding: UTF-8 -*-
from collections import OrderedDict
from pyexcel_xls import get_data
from pyexcel_xls import save_data
import redis
def read_xls_file():
xls_data = get_data(r"test.xlsx")
print "Get data type:", type(xls_data)
conn = redis.Redis()
for key in xls_data['sheet1']:
key = str(key).decode("unicode_escape").encode("utf8")
print key
key = key.lstrip()
key = key.rstrip()
# conn.set(key, key)
if __name__ == '__main__':
read_xls_file()
推荐学习《Python教程》!
以上是 pythonu开头的字符串乱码怎么解决 的全部内容, 来源链接: utcz.com/z/525758.html