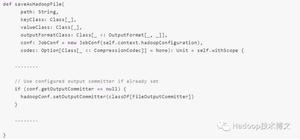
PaddlePaddle升级解读|十余行代码完成迁移学习PaddleHub实战篇

迁移学习 (Transfer Learning) 是属于深度学习的一个子研究领域,该研究领域的目标在于利用数据、任务、或模型之间的相似性,将在旧领域学习过的知识,迁移应用于新领域中。迁移学习吸引了很多研究者投身其中,因为它能够很好的解决深度学习中的以下几个问题:
一些研究领域只有少量标注数据,且数据标注成本较高,不足以训练一个足够鲁棒的神经网络
大规模神经网络的训练依赖于大量的计算资源,这对于一般用户而言难以实现
应对于普适化需求的模型,在特定应用上表现不尽如人意
为了让开发者更便捷地应用迁移学习,百度 PaddlePaddle 开源了预训练模型管理工具 PaddleHub。开发者用使用仅仅十余行的代码,就能完成迁移学习。本文将全面介绍 PaddleHub 及其应用方法。
项目地址:https://github.com/PaddlePaddle/PaddleHub
PaddleHub 介绍
PaddleHub 是基于 PaddlePaddle 开发的预训练模型管理工具,可以借助预训练模型更便捷地开展迁移学习工作,旨在让 PaddlePaddle 生态下的开发者更便捷体验到大规模预训练模型的价值。
PaddleHub 目前的预训练模型覆盖了图像分类、目标检测、词法分析、Transformer、情感分析五大类别。未来会持续开放更多类型的深度学习模型,如语言模型、视频分类、图像生成等预训练模型。
图 1 PaddleHub 功能全景
PaddleHub 主要包括两个功能:命令行工具和 Fine-tune API。
命令行工具
PaddleHub 借鉴了 Anaconda 和 PIP 等软件包管理的理念,开发了命令行工具,可以方便快捷的完成模型的搜索、下载、安装、预测等功能,对应的关键的命令分别是 search,download,install,run 等。我们以 run 命令为例,介绍如何通过命令行工具进行预测。
Run 命令用于执行 Module 的预测,这里分别举一个 NLP 和 CV 的例子。
对于 NLP 任务:输入数据通过--input_text 指定。以百度 LAC 模型(中文词法分析)为例,可以通过以下命令实现单行文本分析。
对于 CV 任务:输入数据通过--input_path 指定。以 SSD 模型(单阶段目标检测)为例子,可以通过以下命令实现单张图片的预测。
更多的命令用法,请读者参考文首的 Github 项目链接。
Fine-tune API
PaddleHub 提供了基于 PaddlePaddle 实现的 Fine-tune API, 重点针对大规模预训练模型的 Fine-tune 任务做了高阶的抽象,让预训练模型能更好服务于用户特定场景的应用。通过大规模预训练模型结合 Fine-tune,可以在更短的时间完成模型的收敛,同时具备更好的泛化能力。
图 2 PaddleHub Fine-tune API 全景
Fine-tune :对一个 Task 进行 Fine-tune,并且定期进行验证集评估。在 Fine-tune 的过程中,接口会定期的保存 checkpoint(模型和运行数据),当运行被中断时,通过 RunConfig 指定上一次运行的 checkpoint 目录,可以直接从上一次运行的最后一次评估中恢复状态继续运行。
迁移任务 Task:在 PaddleHub 中,Task 代表了一个 Fine-tune 的任务。任务中包含了执行该任务相关的 program 以及和任务相关的一些度量指标(如分类准确率 accuracy、precision、 recall、 F1-score 等)、模型损失等。
运行配置 RunConfig:在 PaddleHub 中,RunConfig 代表了在对 Task 进行 Fine-tune 时的运行配置。包括运行的 epoch 次数、batch 的大小、是否使用 GPU 训练等。
优化策略 Strategy:在 PaddleHub 中,Strategy 类封装了一系列适用于迁移学习的 Fine-tune 策略。Strategy 包含了对预训练参数使用什么学习率变化策略,使用哪种类型的优化器,使用什么类型的正则化等。
预训练模型 Module :Module 代表了一个可执行的模型。这里的可执行指的是,Module 可以直接通过命令行 hub run ${MODULE_NAME} 执行预测,或者通过 context 接口获取上下文后进行 Fine-tune。在生成一个 Module 时,支持通过名称、url 或者路径创建 Module。
数据预处理 Reader :PaddleHub 的数据预处理模块 Reader 对常见的 NLP 和 CV 任务进行了抽象。
数据集 Dataset:PaddleHub 提供多种 NLP 任务和 CV 任务的数据集,可供用户载,用户也可以在自定义数据集上完成 Fine-tune。
基于以上介绍的 PaddleHub 两大功能,用户可以实现:无需编写代码,一键使用预训练模型进行预测;通过 hub download 命令,快速地获取 PaddlePaddle 生态下的所有预训练模型;借助 PaddleHub Fine-tune API,使用少量代码完成迁移学习。
以下将从实战角度,教你如何使用 PaddleHub 进行图像分类迁移。
PaddleHub 实战
1. 安装
PaddleHub 是基于 PaddlePaddle 的预训练模型管理框架,使用 PaddleHub 前需要先安装 PaddlePaddle,如果你本地已经安装了 CPU 或者 GPU 版本的 PaddlePaddle,那么可以跳过以下安装步骤。
推荐使用大于 1.4.0 版本的 PaddlePaddle。
通过以下命令来安装 PaddleHub。
2. 选择合适的模型
首先导入必要的 python 包
接下来我们要在 PaddleHub 中选择合适的预训练模型来 Fine-tune,由于猫狗分类是一个图像分类任务,因此我们使用经典的 ResNet-50 作为预训练模型。PaddleHub 提供了丰富的图像分类预训练模型,包括了最新的神经网络架构搜索类的 PNASNet,我们推荐你尝试不同的预训练模型来获得更好的性能。
3. 数据准备
接着需要加载图片数据集。为了快速体验,我们直接加载 PaddleHub 提供的猫狗分类数据集,如果想要使用自定义的数据进行体验,请查看自定义数据。
4. 自定义数据
本节说明如何组装自定义的数据,如果想使用猫狗数据集进行体验,可以直接跳过本节。使用自定义数据时,我们需要自己切分数据集,将数据集且分为训练集、验证集和测试集。
同时使用三个文本文件来记录对应的图片路径和标签,此外还需要一个标签文件用于记录标签的名称。
训练/验证/测试集的数据列表文件的格式如下
标签列表文件的格式如下
使用如下的方式进行加载数据,生成数据集对象
注意事项:
1、num_labels 要填写实际的分类数量,如猫狗分类该字段值为 2,food101 该字段值为 101,下文以 2 为例子
2、base_path 为数据集实际路径,需要填写全路径,下文以/test/data 为例子
3、训练/验证/测试集的数据列表文件中的图片路径需要相对于 base_path 的相对路径,例如图片的实际位置为/test/data/dog/dog1.jpg,base_path 为/test/data,则文件中填写的路径应该为 dog/dog1.jpg
5. 生成 Reader
接着生成一个图像分类的 reader,reader 负责将 dataset 的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
当我们生成一个图像分类的 reader 时,需要指定输入图片的大小
6. 组建 Fine-tune Task
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个 Task。
由于猫狗分类是一个二分类的任务,而我们下载的 cv_classifer_module 是在 ImageNet 数据集上训练的千分类模型,所以我们需要对模型进行简单的微调,把模型改造为一个二分类模型:
1、获取 cv_classifer_module 的上下文环境,包括输入和输出的变量,以及 Paddle Program;
2、从输出变量中找到特征图提取层 feature_map;
3、在 feature_map 后面接入一个全连接层,生成 Task;
7. 选择运行时配置
在进行 Fine-tune 前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
use_cuda:设置为 False 表示使用 CPU 进行训练。如果本机支持 GPU,且安装的是 GPU 版本的 PaddlePaddle,我们建议你将这个选项设置为 True;
epoch:要求 Fine-tune 的任务只遍历 1 次训练集;
batch_size:每次训练的时候,给模型输入的每批数据大小为 32,模型训练时能够并行处理批数据,因此 batch_size 越大,训练的效率越高,但是同时带来了内存的负荷,过大的 batch_size 可能导致内存不足而无法训练,因此选择一个合适的 batch_size 是很重要的一步;
log_interval:每隔 10 step 打印一次训练日志;
eval_interval:每隔 50 step 在验证集上进行一次性能评估;
checkpoint_dir:将训练的参数和数据保存到 cv_Fine-tune_turtorial_demo 目录中;
strategy:使用 DefaultFine-tuneStrategy 策略进行 Fine-tune;
更多运行配置,请查看文首的 Github 项目链接。
8. 开始 Fine-tune
我们选择 Fine-tune_and_eval 接口来进行模型训练,这个接口在 Fine-tune 的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。
9. 查看训练过程的效果
训练过程中的性能数据会被记录到本地,我们可以通过 visualdl 来可视化这些数据。
我们在 shell 中输入以下命令来启动 visualdl,其中${HOST_IP} 为本机 IP,需要用户自行指定
启动服务后,我们使用浏览器访问${HOST_IP}:8989,可以看到训练以及预测的 loss 曲线和 accuracy 曲线,如下图所示。
10. 使用模型进行预测
当 Fine-tune 完成后,我们使用模型来进行预测,整个预测流程大致可以分为以下几步:
1、构建网络
2、生成预测数据的 Reader
3、切换到预测的 Program
4、加载预训练好的参数
5、运行 Program 进行预测
通过以下命令来获取测试的图片(适用于猫狗分类的数据集)
注意:其他数据集所用的测试图片请自行准备。
完整预测代码如下:
以上是 PaddlePaddle升级解读|十余行代码完成迁移学习PaddleHub实战篇 的全部内容, 来源链接: utcz.com/z/524065.html