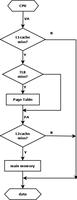
linux2.4.0版本内核代码fork.c浅显分析

结合fork.c文件分析进程创建的过程
本文为作业任务,只做浅显的分析,为大家提供一个分析的思路,很多细节都没有展示。如果想要更详细的分析请去搜索相关函数代码,云海天内有许多有用的信息供大家学习。
int nr_threads;int nr_running;int max_threads;unsigned
long total_forks; /* Handle normal Linux uptimes. */int last_pid;
struct task_struct *pidhash[PIDHASH_SZ];
文件开头定义了线程数量,进程数量,最大线程数,创建的进程总个数,最新的pid号以及存放pid号的哈希表。
void add_wait_queue(wait_queue_head_t *q, wait_queue_t * wait){
unsigned
long flags;wq_write_lock_irqsave(
&q->lock, flags);wait
->flags = 0;__add_wait_queue(q, wait);
wq_write_unlock_irqrestore(
&q->lock, flags);}
void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t * wait){
unsigned
long flags;wq_write_lock_irqsave(
&q->lock, flags);wait
->flags = WQ_FLAG_EXCLUSIVE;__add_wait_queue_tail(q, wait);
wq_write_unlock_irqrestore(
&q->lock, flags);}
void remove_wait_queue(wait_queue_head_t *q, wait_queue_t * wait){
unsigned
long flags;wq_write_lock_irqsave(
&q->lock, flags);__remove_wait_queue(q, wait);
wq_write_unlock_irqrestore(
&q->lock, flags);}
这部分代码与进程的等待队列有关。Linux内核的等待队列是以双循环链表为基础数据结构,与进程调度机制紧密结合,能够用于实现核心的异步事件通知机制。等待队列在include/linux/wait.h中,这是一个通过list_head连接的典型双循环链表,在这个链表中,有两种数据结构:等待队列头(wait_queue_head_t)和等待队列项(wait_queue_t)。等待队列头和等待队列项中都包含一个list_head类型的域作为"连接件"。由于我们只需要对队列进行添加和删除操作,并不会修改其中的对象(等待队列项),因此,我们只需要提供一把保护整个基础设施和所有对象的锁,这把锁保存在等待队列头中,为wq_lock_t类型。在实现中,可以支持读写锁(rwlock)或自旋锁(spinlock)两种类型,通过一个宏定义来切换。如果使用读写锁,将wq_lock_t定义为rwlock_t类型;如果是自旋锁,将wq_lock_t定义为spinlock_t类型。无论哪种情况,分别相应设置wq_read_lock、wq_read_unlock、wq_read_lock_irqsave、wq_read_unlock_irqrestore、wq_write_lock_irq、wq_write_unlock、wq_write_lock_irqsave和wq_write_unlock_irqrestore等宏。在__wait_queue 中定义的WQ_FLAG_EXCLUSIVE表示节点对应的进程对临界资源具有排他性。remove_wait_queue函数用于将等待队列项wait从以q为等待队列头的等待队列中移除
void __init fork_init(unsigned long mempages){
/** The default maximum number of threads is set to a safe
* value: the thread structures can take up at most half
* of memory.
*/max_threads
= mempages / (THREAD_SIZE/PAGE_SIZE) / 2;init_task.rlim[RLIMIT_NPROC].rlim_cur
= max_threads/2;init_task.rlim[RLIMIT_NPROC].rlim_max
= max_threads/2;}
如注释所说,默认的最大线程数被设置为一个安全值:线程结构最多可以占用一半的内存。__init在include/linux/wait.h中,作用为将带有__init标识符的函数划分到.init.text段中,此段只在启动时做一次初始化载入。
/* Protects next_safe and last_pid. */spinlock_t lastpid_lock
= SPIN_LOCK_UNLOCKED;staticint get_pid(unsigned long flags){
staticint next_safe = PID_MAX;struct task_struct *p;if (flags & CLONE_PID)return current->pid;spin_lock(
&lastpid_lock);if((++last_pid) & 0xffff8000) {last_pid
= 300; /* Skip daemons etc. */goto inside;
}
if(last_pid >= next_safe) {
inside:
next_safe = PID_MAX;
read_lock(&tasklist_lock);
repeat:
for_each_task(p) {
if(p->pid == last_pid ||
p->pgrp == last_pid ||
p->session == last_pid) {
if(++last_pid >= next_safe) {
if(last_pid & 0xffff8000)
last_pid = 300;
next_safe = PID_MAX;
}
goto repeat;
}
if(p->pid > last_pid && next_safe > p->pid)
next_safe = p->pid;
if(p->pgrp > last_pid && next_safe > p->pgrp)
next_safe = p->pgrp;
if(p->session > last_pid && next_safe > p->session)
next_safe = p->session;
}
read_unlock(&tasklist_lock);
}
spin_unlock(&lastpid_lock);
return last_pid;
}
这部分代码用来给进程分配pid,对get_pid函数添加自旋锁保证函数的运行,对tasklist_lock添加读锁,确保pid数据安全。last_pid用于记录上一次分配给进程时的pid值。分配的pid一般而言是last_pid+1,如果超出进程个数的最大值(0xffff8000),那么进程pid值从300开始重新查找未用的。也就是说,一般用户进程的pid值范围[300,ffff8000]。(0~299,留给系统)。变量next_safe的含义是,在[last_pid,next_safe]之间,都是没有使用过的pid,一旦last_pid+1大于了next_safe,也就是说pid值进入了不可靠空间,有可能这个值被使用,这时需要遍历task来确认。这样遍历task找到一个没有用过的pid,同时确定next_safe,以保证next_safe到last_pid的区间中pid是空闲的,这样只要再次分配pid时,其值小于next_safe就可以直接分配,而不需要遍历task来查找空闲的pid。
static inline int dup_mmap(struct mm_struct * mm){
struct vm_area_struct * mpnt, *tmp, **pprev;int retval;flush_cache_mm(current
->mm);mm
->locked_vm = 0;mm
->mmap = NULL;mm
->mmap_avl = NULL;mm
->mmap_cache = NULL;mm
->map_count = 0;mm
->cpu_vm_mask = 0;mm
->swap_cnt = 0;mm
->swap_address = 0;pprev
= &mm->mmap;for (mpnt = current->mm->mmap ; mpnt ; mpnt = mpnt->vm_next) {struct file *file;retval
= -ENOMEM;if(mpnt->vm_flags & VM_DONTCOPY)continue;tmp
= kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);if (!tmp)goto fail_nomem;*tmp = *mpnt;tmp
->vm_flags &= ~VM_LOCKED;tmp
->vm_mm = mm;mm
->map_count++;tmp
->vm_next = NULL;file
= tmp->vm_file;if (file) {struct inode *inode = file->f_dentry->d_inode;get_file(file);
if (tmp->vm_flags & VM_DENYWRITE)atomic_dec(
&inode->i_writecount);/* insert tmp into the share list, just after mpnt */spin_lock(
&inode->i_mapping->i_shared_lock);if((tmp->vm_next_share = mpnt->vm_next_share) != NULL)mpnt
->vm_next_share->vm_pprev_share =&tmp->vm_next_share;
mpnt->vm_next_share = tmp;
tmp->vm_pprev_share = &mpnt->vm_next_share;
spin_unlock(&inode->i_mapping->i_shared_lock);
}
/* Copy the pages, but defer checking for errors */
retval = copy_page_range(mm, current->mm, tmp);
if (!retval && tmp->vm_ops && tmp->vm_ops->open)
tmp->vm_ops->open(tmp);
/*
* Link in the new vma even if an error occurred,
* so that exit_mmap() can clean up the mess.
*/
*pprev = tmp;
pprev = &tmp->vm_next;
if (retval)
goto fail_nomem;
}
retval = 0;
if (mm->map_count >= AVL_MIN_MAP_COUNT)
build_mmap_avl(mm);
fail_nomem:
flush_tlb_mm(current->mm);
return retval;
}
spinlock_t mmlist_lock __cacheline_aligned = SPIN_LOCK_UNLOCKED;
#define allocate_mm() (kmem_cache_alloc(mm_cachep, SLAB_KERNEL))
#define free_mm(mm) (kmem_cache_free(mm_cachep, (mm)))
staticstruct mm_struct * mm_init(struct mm_struct * mm)
{
atomic_set(&mm->mm_users, 1);
atomic_set(&mm->mm_count, 1);
init_MUTEX(&mm->mmap_sem);
mm->page_table_lock = SPIN_LOCK_UNLOCKED;
mm->pgd = pgd_alloc();
if (mm->pgd)
return mm;
free_mm(mm);
return NULL;
}
/*
* Allocate and initialize an mm_struct.
*/
struct mm_struct * mm_alloc(void)
{
struct mm_struct * mm;
mm = allocate_mm();
if (mm) {
memset(mm, 0, sizeof(*mm));
return mm_init(mm);
}
return NULL;
}
/*
* Called when the last reference to the mm
* is dropped: either by a lazy thread or by
* mmput. Free the page directory and the mm.
*/
inline void __mmdrop(struct mm_struct *mm)
{
if (mm == &init_mm) BUG();
pgd_free(mm->pgd);
destroy_context(mm);
free_mm(mm);
}
/*
* Decrement the use count and release all resources for an mm.
*/
void mmput(struct mm_struct *mm)
{
if (atomic_dec_and_lock(&mm->mm_users, &mmlist_lock)) {
list_del(&mm->mmlist);
spin_unlock(&mmlist_lock);
exit_mmap(mm);
mmdrop(mm);
}
}
void mm_release(void)
{
struct task_struct *tsk = current;
/* notify parent sleeping on vfork() */
if (tsk->flags & PF_VFORK) {
tsk->flags &= ~PF_VFORK;
up(tsk->p_opptr->vfork_sem);
}
}
这部分代码为内存管理部分,代码中的注释向我们大致说明了本段代码的功能。
Linux内核通过一个被称为进程描述符的task_struct结构体来管理进程,这个结构体包含了一个进程所需的所有信息。它定义在include/linux/sched.h文件中。每一个进程都会有自己独立的mm_struct,这样每一个进程都会有自己独立的地址空间,这样才能互不干扰。在地址空间中,mmap为地址空间的内存区域(用vm_area_struct结构来表示)链表,表示起来更加方便。mm_struct的结构描述了进程的用户空间的结构,定义了用户空间的段分布:数据段,代码段,堆栈段。其中pgd_t是该进程用户空间地址映射到物理地址时使用vm_area_struct是进程用户空间已映射到物理空间的虚拟地址区间,定义在/include/linux/mm.h。mmap是该空间区块组成的链表。vm_flag是描述对虚拟区间的操作的标志。
staticint copy_mm(unsigned long clone_flags, struct task_struct * tsk){
struct mm_struct * mm, *oldmm;int retval;tsk
->min_flt = tsk->maj_flt = 0;tsk
->cmin_flt = tsk->cmaj_flt = 0;tsk
->nswap = tsk->cnswap = 0;tsk
->mm = NULL;tsk
->active_mm = NULL;/** Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/oldmm
= current->mm;if (!oldmm)return0;if (clone_flags & CLONE_VM) {atomic_inc(
&oldmm->mm_users);mm
= oldmm;goto good_mm;}
retval
= -ENOMEM;mm
= allocate_mm();if (!mm)goto fail_nomem;/* Copy the current MM stuff.. */memcpy(mm, oldmm,
sizeof(*mm));if (!mm_init(mm))goto fail_nomem;down(
&oldmm->mmap_sem);retval
= dup_mmap(mm);up(
&oldmm->mmap_sem);/** Add it to the mmlist after the parent.
*
* Doing it this way means that we can order
* the list, and fork() won"t mess up the
* ordering significantly.
*/spin_lock(
&mmlist_lock);list_add(
&mm->mmlist, &oldmm->mmlist);spin_unlock(
&mmlist_lock);if (retval)goto free_pt;/** child gets a private LDT (if there was an LDT in the parent)
*/copy_segments(tsk, mm);
if (init_new_context(tsk,mm))goto free_pt;good_mm:
tsk
->mm = mm;tsk
->active_mm = mm;return0;free_pt:
mmput(mm);
fail_nomem:
return retval;}
static inline struct fs_struct *__copy_fs_struct(struct fs_struct *old){
struct fs_struct *fs = kmem_cache_alloc(fs_cachep, GFP_KERNEL);/* We don"t need to lock fs - think why ;-) */if (fs) {
atomic_set(&fs->count, 1);
fs->lock = RW_LOCK_UNLOCKED;
fs->umask = old->umask;
read_lock(&old->lock);
fs->rootmnt = mntget(old->rootmnt);
fs->root = dget(old->root);
fs->pwdmnt = mntget(old->pwdmnt);
fs->pwd = dget(old->pwd);
if (old->altroot) {
fs->altrootmnt = mntget(old->altrootmnt);
fs->altroot = dget(old->altroot);
} else {
fs->altrootmnt = NULL;
fs->altroot = NULL;
}
read_unlock(&old->lock);
}
return fs;
}
struct fs_struct *copy_fs_struct(struct fs_struct *old)
{
return __copy_fs_struct(old);
}
static inline int copy_fs(unsigned long clone_flags, struct task_struct * tsk)
{
if (clone_flags & CLONE_FS) {
atomic_inc(¤t->fs->count);
return0;
}
tsk->fs = __copy_fs_struct(current->fs);
if (!tsk->fs)
return -1;
return0;
}
staticint count_open_files(struct files_struct *files, int size)
{
int i;
/* Find the last open fd */
for (i = size/(8*sizeof(long)); i > 0; ) {
if (files->open_fds->fds_bits[--i])
break;
}
i = (i+1) * 8 * sizeof(long);
return i;
}
staticint copy_files(unsigned long clone_flags, struct task_struct * tsk)
{
struct files_struct *oldf, *newf;
struct file **old_fds, **new_fds;
int open_files, nfds, size, i, error = 0;
/*
* A background process may not have any files ...
*/
oldf = current->files;
if (!oldf)
gotoout;
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
gotoout;
}
tsk->files = NULL;
error = -ENOMEM;
newf = kmem_cache_alloc(files_cachep, SLAB_KERNEL);
if (!newf)
gotoout;
atomic_set(&newf->count, 1);
newf->file_lock = RW_LOCK_UNLOCKED;
newf->next_fd = 0;
newf->max_fds = NR_OPEN_DEFAULT;
newf->max_fdset = __FD_SETSIZE;
newf->close_on_exec = &newf->close_on_exec_init;
newf->open_fds = &newf->open_fds_init;
newf->fd = &newf->fd_array[0];
/* We don"t yet have the oldf readlock, but even if the old
fdset gets grown now, we"ll only copy up to "size" fds */
size = oldf->max_fdset;
if (size > __FD_SETSIZE) {
newf->max_fdset = 0;
write_lock(&newf->file_lock);
error = expand_fdset(newf, size);
write_unlock(&newf->file_lock);
if (error)
goto out_release;
}
read_lock(&oldf->file_lock);
open_files = count_open_files(oldf, size);
/*
* Check whether we need to allocate a larger fd array.
* Note: we"re not a clone task, so the open count won"t
* change.
*/
nfds = NR_OPEN_DEFAULT;
if (open_files > nfds) {
read_unlock(&oldf->file_lock);
newf->max_fds = 0;
write_lock(&newf->file_lock);
error = expand_fd_array(newf, open_files);
write_unlock(&newf->file_lock);
if (error)
goto out_release;
nfds = newf->max_fds;
read_lock(&oldf->file_lock);
}
old_fds = oldf->fd;
new_fds = newf->fd;
memcpy(newf->open_fds->fds_bits, oldf->open_fds->fds_bits, open_files/8);
memcpy(newf->close_on_exec->fds_bits, oldf->close_on_exec->fds_bits, open_files/8);
for (i = open_files; i != 0; i--) {
struct file *f = *old_fds++;
if (f)
get_file(f);
*new_fds++ = f;
}
read_unlock(&oldf->file_lock);
/* compute the remainder to be cleared */
size = (newf->max_fds - open_files) * sizeof(struct file *);
/* This is long word aligned thus could use a optimized version */
memset(new_fds, 0, size);
if (newf->max_fdset > open_files) {
int left = (newf->max_fdset-open_files)/8;
int start = open_files / (8 * sizeof(unsigned long));
memset(&newf->open_fds->fds_bits[start], 0, left);
memset(&newf->close_on_exec->fds_bits[start], 0, left);
}
tsk->files = newf;
error = 0;
out:
return error;
out_release:
free_fdset (newf->close_on_exec, newf->max_fdset);
free_fdset (newf->open_fds, newf->max_fdset);
kmem_cache_free(files_cachep, newf);
gotoout;
}
static inline int copy_sighand(unsigned long clone_flags, struct task_struct * tsk)
{
struct signal_struct *sig;
if (clone_flags & CLONE_SIGHAND) {
atomic_inc(¤t->sig->count);
return0;
}
sig = kmem_cache_alloc(sigact_cachep, GFP_KERNEL);
tsk->sig = sig;
if (!sig)
return -1;
spin_lock_init(&sig->siglock);
atomic_set(&sig->count, 1);
memcpy(tsk->sig->action, current->sig->action, sizeof(tsk->sig->action));
return0;
}
static inline void copy_flags(unsigned long clone_flags, struct task_struct *p)
{
unsigned long new_flags = p->flags;
new_flags &= ~(PF_SUPERPRIV | PF_USEDFPU | PF_VFORK);
new_flags |= PF_FORKNOEXEC;
if (!(clone_flags & CLONE_PTRACE))
p->ptrace = 0;
if (clone_flags & CLONE_VFORK)
new_flags |= PF_VFORK;
p->flags = new_flags;
}
父进程中在调用fork()派生新进程,实际上相当于创建了进程的一个拷贝;复制出来的子进程有自己的 task_struct结构和系统空间堆栈,但与父进程共享其他所有的资源。Linux为此提供了两个系统调用,一个是fork(),另一个是clone()。我们现在主要讨论fork()。fork()是全部复制,父进程所需的资源全部通过数据结构的复制传递给子进程,而完成这一操作的函数定义就是上方所写的代码段。调用fork时,内核会在copy_mm函数中处理子进程的mm_struct,在copy_files函数中处理拷贝父进程打开的文件的相关事宜,在copy_fs中记录进程所在文件系统的根目录和当前目录信息, copy_sighand中复制进程对信号的处理方式。
/** Ok, this is the main fork-routine. It copies the system process
* information (task[nr]) and sets up the necessary registers. It also
* copies the data segment in its entirety. The "stack_start" and
* "stack_top" arguments are simply passed along to the platform
* specific copy_thread() routine. Most platforms ignore stack_top.
* For an example that"s using stack_top, see
* arch/ia64/kernel/process.c.
*/int do_fork(unsigned long clone_flags, unsigned long stack_start,struct pt_regs *regs, unsigned long stack_size)
{
int retval = -ENOMEM;
struct task_struct *p;
DECLARE_MUTEX_LOCKED(sem);
if (clone_flags & CLONE_PID) {
/* This is only allowed from the boot up thread */
if (current->pid)
return -EPERM;
}
current->vfork_sem = &sem;
p = alloc_task_struct();
if (!p)
goto fork_out;
*p = *current;
retval = -EAGAIN;
if (atomic_read(&p->user->processes) >= p->rlim[RLIMIT_NPROC].rlim_cur)
goto bad_fork_free;
atomic_inc(&p->user->__count);
atomic_inc(&p->user->processes);
/*
* Counter increases are protected by
* the kernel lock so nr_threads can"t
* increase under us (but it may decrease).
*/
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
get_exec_domain(p->exec_domain);
if (p->binfmt && p->binfmt->module)
__MOD_INC_USE_COUNT(p->binfmt->module);
p->did_exec = 0;
p->swappable = 0;
p->state = TASK_UNINTERRUPTIBLE;
copy_flags(clone_flags, p);
p->pid = get_pid(clone_flags);
p->run_list.next = NULL;
p->run_list.prev = NULL;
if ((clone_flags & CLONE_VFORK) || !(clone_flags & CLONE_PARENT)) {
p->p_opptr = current;
if (!(p->ptrace & PT_PTRACED))
p->p_pptr = current;
}
p->p_cptr = NULL;
init_waitqueue_head(&p->wait_chldexit);
p->vfork_sem = NULL;
spin_lock_init(&p->alloc_lock);
p->sigpending = 0;
init_sigpending(&p->pending);
p->it_real_value = p->it_virt_value = p->it_prof_value = 0;
p->it_real_incr = p->it_virt_incr = p->it_prof_incr = 0;
init_timer(&p->real_timer);
p->real_timer.data = (unsigned long) p;
p->leader = 0; /* session leadership doesn"t inherit */
p->tty_old_pgrp = 0;
p->times.tms_utime = p->times.tms_stime = 0;
p->times.tms_cutime = p->times.tms_cstime = 0;
#ifdef CONFIG_SMP
{
int i;
p->has_cpu = 0;
p->processor = current->processor;
/* ?? should we just memset this ?? */
for(i = 0; i < smp_num_cpus; i++)
p->per_cpu_utime[i] = p->per_cpu_stime[i] = 0;
spin_lock_init(&p->sigmask_lock);
}
#endif
p->lock_depth = -1; /* -1 = no lock */
p->start_time = jiffies;
retval = -ENOMEM;
/* copy all the process information */
if (copy_files(clone_flags, p))
goto bad_fork_cleanup;
if (copy_fs(clone_flags, p))
goto bad_fork_cleanup_files;
if (copy_sighand(clone_flags, p))
goto bad_fork_cleanup_fs;
if (copy_mm(clone_flags, p))
goto bad_fork_cleanup_sighand;
retval = copy_thread(0, clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_sighand;
p->semundo = NULL;
/* Our parent execution domain becomes current domain
These must match for thread signalling to apply */
p->parent_exec_id = p->self_exec_id;
/* ok, now we should be set up.. */
p->swappable = 1;
p->exit_signal = clone_flags & CSIGNAL;
p->pdeath_signal = 0;
/*
* "share" dynamic priority between parent and child, thus the
* total amount of dynamic priorities in the system doesnt change,
* more scheduling fairness. This is only important in the first
* timeslice, on the long run the scheduling behaviour is unchanged.
*/
p->counter = (current->counter + 1) >> 1;
current->counter >>= 1;
if (!current->counter)
current->need_resched = 1;
/*
* Ok, add it to the run-queues and make it
* visible to the rest of the system.
*
* Let it rip!
*/
retval = p->pid;
p->tgid = retval;
INIT_LIST_HEAD(&p->thread_group);
write_lock_irq(&tasklist_lock);
if (clone_flags & CLONE_THREAD) {
p->tgid = current->tgid;
list_add(&p->thread_group, ¤t->thread_group);
}
SET_LINKS(p);
hash_pid(p);
nr_threads++;
write_unlock_irq(&tasklist_lock);
if (p->ptrace & PT_PTRACED)
send_sig(SIGSTOP, p, 1);
wake_up_process(p); /* do this last */
++total_forks;
fork_out:
if ((clone_flags & CLONE_VFORK) && (retval > 0))
down(&sem);
return retval;
bad_fork_cleanup_sighand:
exit_sighand(p);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup:
put_exec_domain(p->exec_domain);
if (p->binfmt && p->binfmt->module)
__MOD_DEC_USE_COUNT(p->binfmt->module);
bad_fork_cleanup_count:
atomic_dec(&p->user->processes);
free_uid(p->user);
bad_fork_free:
free_task_struct(p);
goto fork_out;
}
如开头注释第一句所说,这部分代码是fork.c中最主要的函数。
do_fork首先进行一些参数及权限的检查,仅允许从线程启动。之后进行内存的分配,复制父进程的task_struct。判断进程数量,将从父进程中继承的task_struct初始化,获取新的pid,分配CPU,解锁后设定运行时间。将子进程的pid放入pidhash表中,就可以唤醒子进程了。代码中间部分有设置进程判断,若发现非法进程会直接清理掉。清理函数在代码尾部定义。
/* SLAB cache for signal_struct structures (tsk->sig) */kmem_cache_t
*sigact_cachep;/* SLAB cache for files_struct structures (tsk->files) */kmem_cache_t
*files_cachep;/* SLAB cache for fs_struct structures (tsk->fs) */kmem_cache_t
*fs_cachep;/* SLAB cache for vm_area_struct structures */kmem_cache_t
*vm_area_cachep;/* SLAB cache for mm_struct structures (tsk->mm) */kmem_cache_t
*mm_cachep;void __init proc_caches_init(void){
sigact_cachep
= kmem_cache_create("signal_act",sizeof(struct signal_struct), 0,SLAB_HWCACHE_ALIGN, NULL, NULL);
if (!sigact_cachep)panic(
"Cannot create signal action SLAB cache");files_cachep
= kmem_cache_create("files_cache",sizeof(struct files_struct), 0,SLAB_HWCACHE_ALIGN, NULL, NULL);
if (!files_cachep)panic(
"Cannot create files SLAB cache");fs_cachep
= kmem_cache_create("fs_cache",sizeof(struct fs_struct), 0,SLAB_HWCACHE_ALIGN, NULL, NULL);
if (!fs_cachep)panic(
"Cannot create fs_struct SLAB cache");vm_area_cachep
= kmem_cache_create("vm_area_struct",sizeof(struct vm_area_struct), 0,SLAB_HWCACHE_ALIGN, NULL, NULL);
if(!vm_area_cachep)panic(
"vma_init: Cannot alloc vm_area_struct SLAB cache");mm_cachep
= kmem_cache_create("mm_struct",sizeof(struct mm_struct), 0,SLAB_HWCACHE_ALIGN, NULL, NULL);
if(!mm_cachep)panic(
"vma_init: Cannot alloc mm_struct SLAB cache");}
最后这部分代码作用是处理进程的缓存,为proc文件系统创建高速缓冲。
从文件开头的宏定义,到等待队列的处理,到线程数的安全处理,到pid的分配,到进程的内存管理,到父进程复制出子进程。fork()函数中对进程的创建大致是以上步骤。主要在于copy部分对task_struct复制和复制后的初始化。
以上是 linux2.4.0版本内核代码fork.c浅显分析 的全部内容, 来源链接: utcz.com/z/519672.html