Mysql优化策略的思考

首先我们先了解什么是索引,以及索引的作用,要解决的问题。
PS:索引是一种排序的数据结构,为了提升数据的查询性能,索引数据本身也是存储在磁盘文件中。
一 索引的使用
1 Mysql中索引类型有哪些呢?
- 主键索引 --主键索引不可以为null
- 唯一索引 --可以有一个为null
- 全文索引 --通过 match against 查询命令支持文本匹配搜索的业务
2 Mysql 中索引数据结构有哪些?
- B+tree
B Tree由平衡二叉平衡树 ,降低树的高度变种为B Tree
通过节点的合并和分裂,降低树的高度;
充分考虑数据页DataPage的大小,充分利用逻辑区域内存
B+ Tree
每个节点存储的数量和定义的度一样,所以树的深度会降低
所有的父节点和分支节点不存储数据或者数据的指向磁盘地址
叶子节点指向了相邻节点的指针--不用重复从根节点访问
降低了数据的存储能力;
叶子节点本身是有序的数据,所以排序能力更好;
- Hash
通过hash码找到对应存储磁盘映射位置hash支持等值,但对于范围值搜索不支持
3 Mysql 存储引擎有哪些呢,索引的存储结构是否会有不同呢?
存储引擎就是表数据存储的类型,以及以何种方式管理数据存储,对于不同的使用场景,则可以使用不同的存储引擎规则创建表;
InnoDB--支持事务机制(行锁和表锁),存储数据文件只有两个.frm 表结构文件和.ibd 索引数据结构文件。这种引擎有以下特点:
--数据就是索引,索引就是数据
--所有的索引的叶子节点,存储的数据行对象
--只有主键索引决定了索引的物理存储顺序,即聚簇索引
--没有主键索引的时候,找的unique key 非null来做聚簇索引组织索引文件,如果都没有则会用rowid
--其它列创建索引则为辅助索引,通过辅助索引B+Tree查找到目标叶子节点,叶子节点只存储了对应的主键索引的值,
再扫描主键索引的B+tree即可找到目标,所以会扫描两次B+Tree,造成了回表
MyIsam--支持表锁,不支持事务。
有以下三个文件构成存储数据:
.frm 表结构文件
.MYD --数据信息文件
.MYI --索引文件
这种引擎有以下特点:
--数据文件和索引文件是分开的,即非聚簇索引
--索引数据文件的叶子节点存储的是数据行内存地址
--主键索引之外的字段都是辅助索引,索引访问机制与主键索引类似
Memory--内存中的数据,重启服务数据就会丢失;
CSV--数据归档,支持压缩,用于存储历史数据
4 使用索引的特殊情况
联合索引最左匹配
--使用索引和创建所以列的顺序一样(优化器会调整查询列的顺序帮助走索引)
--使用该索引时候,列不可中断
回表
通过辅助索引B+Tree查找,最终找到叶子节点,存储了对应的主键索引的值,然后再扫描主键索引的B+tree即可找到目标,
经过了两次的B+tree的扫描
覆盖索引
查询的列,已经包含在索引的里面时候,
直接在辅助索引B+tree中查询返回,不用扫描主键索引B+tree,减少了回表,提高性能
注意事项
索引列不要使用函数或者表达式,计算;列的隐式转换
% 字符索引是从最左开始比较的--推荐用全文索引
Not like !=等等不推荐使用(不一定不走索引,sql优化" title="mysql优化">mysql优化器会根据消耗情况自我优化执行)
创建索引的时候,不要再离散程度不高的列上创建;
Optimazer 优化器,如果索引性能接近全表的话,会放弃索引
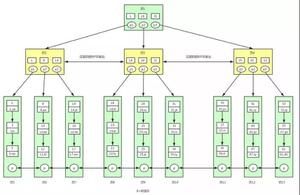
二 分库分表策略
分库分表作为数据库提升存储能力,以及优化查询性能的策略;分为垂直分库分表和水平分库分表两种;
1 分库分表引发的问题思考
如何解决跨库关联查询
--数据冗余方式:记录多余的信息
--数据同步机制,即时同步其它依赖的数据
--全局表:固定不太变化的表,每个DB放一份,俗称广播表;
--RPC:跨库接口查询组装结果集
如何解决分布式事务问题
--通过集成seata,底层已帮我们打通,通过协助方参与,实现二阶段或者三阶段提交的机制
翻页查询
全局ID问题
数据源如何配置
ORM怎么选择数据源
2 解决以上分库分表的问题
- 客户端sharding访问方式
--sharding-jdbc就是jdbc的增强访问
--真实表,物理存在的表
--逻辑表,对应用层一直的访问表
--分片键,根据哪个字段确定分库依据
--动态表,表名会根据时间动态变化
--广播表,全局表,每个DB都有一份副本
--绑定表,父表和子表使用相同的分片规则,落到同样的DB
- 服务端之间建立代理层去访问,mycat服务代理
--下载mycat
--修改conf目录下相应的配置
--wrapper.conf 修改jVM的参数
--server.xml system和user标签
--schema.xml
schema节点配置的是数据库,内部可以添加表节点说明
datanode 配置的是真实的数据库实例节点映射
datahost 配置真实数据库的连接信息
--rule.xml 配置每个表分片的规则
mycat也可搭建高可用集群,提高数据库的可靠性,详细参考Mycat官网
以上是 Mysql优化策略的思考 的全部内容, 来源链接: utcz.com/z/518982.html