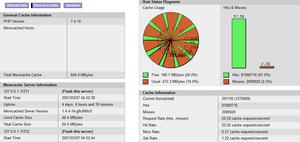
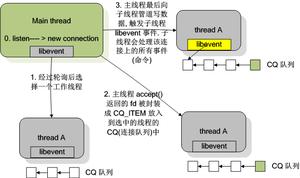
Memcache使用环境

使用Memcache的网站一般流量都是比较大的,为了缓解数据库的压力,让Memcache作为一个缓存区域,把部分信息保存在内存中,在前端能够迅速的进行存取。那么一般的焦点就是集中在如何分担数据库压力和进行分布式,毕竟单台Memcache的内存容量的有限的。我这里简单提出我的个人看法,未经实践,权当参考。
分布式应用
Memcache本来支持分布式,我们客户端稍加改造,更好的支持。我们的key可以适当进行有规律的封装,比如以user为主的网站来说,每个用户都有User ID,那么可以按照固定的ID来进行提取和存取,比如1开头的用户保存在第一台Memcache服务器上,以2开头的用户的数据保存在第二胎Mecache服务器上,存取数据都先按照User ID来进行相应的转换和存取。
但是这个有缺点,就是需要对User ID进行判断,如果业务不一致,或者其他类型的应用,可能不是那么合适,那么可以根据自己的实际业务来进行考虑,或者去想更合适的方法。
减少数据库压力
这个算是比较重要的,所有的数据基本上都是保存在数据库当中的,每次频繁的存取数据库,导致数据库性能极具下降,无法同时服务更多的用户,比如MySQL,特别频繁的锁表,那么让Memcache来分担数据库的压力吧。我们需要一种改动比较小,并且能够不会大规模改变前端的方式来进行改变目前的架构。
考虑的一种简单方法:
后端的数据库操作模块,把所有的Select操作提取出来(update/delete/insert不管),然后把对应的SQL进行相应的hash算法计算得出一个hash数据key(比如MD5或者SHA),然后把这个key去Memcache中查找数据,如果这个数据不存在,说明还没写入到缓存中,那么从数据库把数据提取出来,一个是数组类格式,然后把数据在set到Memcache中,key就是这个SQL的hash值,然后相应的设置一个失效时间,比如一个小时,那么一个小时中的数据都是从缓存中提取的,有效减少数据库的压力。缺点是数据不实时,当数据做了修改以后,无法实时到前端显示,并且还有可能对内存占用比较大,毕竟每次select出来的数据数量可能比较巨大,这个是需要考虑的因素。
以上是 Memcache使用环境 的全部内容, 来源链接: utcz.com/z/518874.html