009.OpenShift管理及监控

一 资源限制
1.1 pod资源限制
pod可以包括资源请求和资源限制:
- 资源请求
用于调度,并控制pod不能在计算资源少于指定数量的情况下运行。调度程序试图找到一个具有足够计算资源的节点来满足pod请求。
- 资源限制
用于防止pod耗尽节点的所有计算资源,基于pod的节点配置Linux内核cgroups特性,以执行pod的资源限制。
尽管资源请求和资源限制是pod定义的一部分,但通常建议在dc中设置。OpenShift推荐的实践规定,不应该单独创建pod,而应该由dc创建。
1.2 应用配额
OCP可以执行跟踪和限制两种资源使用的配额:
对象的数量:Kubernetes资源的数量,如pod、service和route。
计算资源:物理或虚拟硬件资源的数量,如CPU、内存和存储容量。
通过避免master的Etcd数据库的无限制增长,对Kubernetes资源的数量设置配额有助于OpenShift master服务器的稳定性。对Kubernetes资源设置配额还可以避免耗尽其他有限的软件资源,比如服务的IP地址。
同样,对计算资源的数量施加配额可以避免耗尽OpenShift集群中单个节点的计算能力。还避免了一个应用程序使用所有集群容量,从而影响共享集群的其他应用程序。
OpenShift通过使用ResourceQuota对象或简单的quota来管理对象使用的配额及计算资源。
ResourceQuota对象指定项目的硬资源使用限制。配额的所有属性都是可选的,这意味着任何不受配额限制的资源都可以无限制地使用。
注意:一个项目可以包含多个ResourceQuota对象,其效果是累积的,但是对于同一个项目,两个不同的 ResourceQuota 不会试图限制相同类型的对象或计算资源。
1.3 ResourceQuota限制资源
下表显示 ResourceQuota 可以限制的主要对象和计算资源:
对象名
描述
pods
总计的pod数量
replicationcontrollers
总计的rc数量
services
总计的service数量
secrets
总计的secret数量
persistentvolumeclaims
总计的pvc数量
cpu
所有容器的CPU使用总量
memory
所有容器的总内存使用
storage
所有容器的磁盘总使用量Quota属性可以跟踪项目中所有pod的资源请求或资源限制。默认情况下,配额属性跟踪资源请求。要跟踪资源限制,可以在计算资源名称前面加上限制,例如limit.cpu。
示例一:使用YAML语法定义的ResourceQuota资源,它为对象计数和计算资源指定了配额:
1 $ cat2 apiVersion: v1
3 kind: ResourceQuota
4 metadata:
5name: dev-quota
6 spec:
7 hard:
8 services: "10"
9 cpu: "1300m"
10 memory: "1.5Gi"
11 $ oc create -f dev-quota.yml
示例二:使用oc create quota命令创建:
1 $ oc create quota dev-quota2 --hard=services=10
3 --hard=cpu=1300m
4 --hard=memory=1.5Gi
5 $ oc get resourcequota #列出可用的配额
6 $ oc describe resourcequota NAME #查看与配额中定义的任何与限制相关的统计信息
7 $ oc delete resourcequota compute-quota #按名称删除活动配额
提示:若oc describe resourcequota命令不带参数,只显示项目中所有resourcequota对象的累积限制集,而不显示哪个对象定义了哪个限制。
当在项目中首次创建配额时,项目将限制创建任何可能超出配额约束的新资源的能力,然后重新计算资源使用情况。在创建配额和使用数据统计更新之后,项目接受新内容的创建。当创建新资源时,配额使用量立即增加。当一个资源被删除时,在下一次对项目的 quota 统计数据进行全面重新计算时,配额使用将减少。
ResourceQuota 应用于整个项目,但许多 OpenShift 过程,例如 build 和 deployment,在项目中创建 pod,可能会失败,因为启动它们将超过项目 quota。
如果对项目的修改超过了对象数量的 quota,则服务器将拒绝操作,并向用户返回错误消息。但如果修改超出了计算资源的quota,则操作不会立即失败。OpenShift 将重试该操作几次,使管理员有机会增加配额或执行纠正操作,比如上线新节点,扩容节点资源。
注意:如果设置了计算资源的 quota,OpenShift 拒绝创建不指定该计算资源的资源请求或资源限制的pod。
1.3 应用限制范围
LimitRange资源,也称为limit,定义了计算资源请求的默认值、最小值和最大值,以及项目中定义的单个pod或单个容器的限制,pod的资源请求或限制是其容器的总和。
要理解limit rang和resource quota之间的区别,limit rang为单个pod定义了有效范围和默认值,而resource quota仅为项目中所有pod的和定义了最高值。
通常可同时定义项目的限制和配额。
LimitRange资源还可以为image、is或pvc的存储容量定义默认值、最小值和最大值。如果添加到项目中的资源不提供计算资源请求,那么它将接受项目的limit ranges提供的默认值。如果新资源提供的计算资源请求或限制小于项目的limit range指定的最小值,则不创建该资源。同样,如果新资源提供的计算资源请求或限制高于项目的limit range所指定的最大值,则不会创建该资源。
OpenShift 提供的大多数标准 S2I builder image 和 templabe 都没有指定。要使用受配额限制的 template 和 builder,项目需要包含一个 limit range 对象,该对象为容器资源请求指定默认值。
如下为描述了一些可以由LimitRange对象指定的计算资源。
类型
资源名称
描述
Container
cpu
每个容器允许的最小和最大CPU。
Container
memory
每个容器允许的最小和最大内存
Pod
cpu
一个pod中所有容器允许的最小和最大CPU
Pod
memory
一个pod中所有容器允许的最小和最大内存
Image
storage
可以推送到内部仓库的图像的最大大小
PVC
storage
一个pvc的容量的最小和最大容量
示例一:limit rang的yaml示例:
1 $ cat dev-limits.yml2 apiVersion: "v1"
3 kind: "LimitRange"
4 metadata:
5name: "dev-limits"
6 spec:
7 limits:
8 - type: "Pod"
9 max:
10 cpu: "2"
11 memory: "1Gi"
12 min:
13 cpu: "200m"
14 memory: "6Mi"
15 - type: "Container"
16 default:
17 cpu: "1"
18 memory: "512Mi"
19 $ oc create -f dev-limits.yml
20 $ oc describe limitranges NAME #查看项目中强制执行的限制约束
21 $ oc get limits #查看项目中强制执行的限制约束
22 $ oc delete limitranges name#按名称删除活动的限制范围
提示:OCP 3.9不支持使用oc create命令参数形式创建limit rang。
在项目中创建limit rang之后,将根据项目中的每个limit rang资源评估所有资源创建请求。如果新资源违反由任何limit rang设置的最小或最大约束,则拒绝该资源。如果新资源没有声明配置值,且约束支持默认值,则将默认值作为其使用值应用于新资源。
所有资源更新请求也将根据项目中的每个limit rang资源进行评估,如果更新后的资源违反了任何约束,则拒绝更新。
注意:避免将LimitRange设的过高,或ResourceQuota设的过低。违反LimitRange将阻止pod创建,并清晰保存。违反ResourceQuota将阻止pod被调度,状态转为pending。
1.4 多项目quota配额
ClusterResourceQuota资源是在集群级别创建的,创建方式类似持久卷,并指定应用于多个项目的资源约束。
可以通过以下两种方式指定哪些项目受集群资源配额限制:
- 使用openshift.io/requester标记,定义项目所有者,该所有者的所有项目均应用quota;
- 使用selector,匹配该selector的项目将应用quota。
示例1:
1 $ oc create clusterquota user-qa2 --project-annotation-selector openshift.io/requester=qa
3 --hard pods=12
4 --hard secrets=20 #为qa用户拥有的所有项目创建集群资源配额
5 $ oc create clusterquota env-qa
6 --project-label-selector environment=qa
7 --hard pods=10
8 --hard services=5 #为所有具有environment=qa标签的项目创建集群资源配额
9 $ oc describe QUOTA NAME #查看应用于当前项目的集群资源配额
10 $ oc delete clusterquota NAME #删除集群资源配额
提示:不建议使用一个集群资源配额来匹配超过100个项目。这是为了避免较大的locking开销。当创建或更新项目中的资源时,在搜索所有适用的资源配额时锁定项目需要较大的资源消耗。
二 限制资源使用
2.1 前置准备
准备完整的OpenShift集群,参考《003.OpenShift网络》2.1。
2.2 本练习准备
1 [student@workstation ~]$ lab monitor-limit setup2.3 查看当前资源
1 [student@workstation ~]$ oc login -u admin -p redhat https://master.lab.example.com2 [student@workstation ~]$ oc describe node node1.lab.example.com | grep -A 4 Allocated
3 [student@workstation ~]$ oc describe node node2.lab.example.com | grep -A 4 Allocated
2.4 创建应用
1 [student@workstation ~]$ oc new-project resources2 [student@workstation ~]$ oc new-app --name=hello
3 --docker-image=registry.lab.example.com/openshift/hello-openshift
4 [student@workstation ~]$ oc get pod -o wide
5 NAME READY STATUS RESTARTS AGE IP NODE
6 hello-1-znk56 1/1 Running 0 24s 10.128.0.16 node1.lab.example.com
2.5 删除应用
1 [student@workstation ~]$ oc delete all -l app=hello2.6 添加资源限制
作为集群管理员,向项目quota和limit range,以便为项目中的pod提供默认资源请求。
1 [student@workstation ~]$ cd /home/student/DO280/labs/monitor-limit/2 [student@workstation monitor-limit]$ cat limits.yml #创建limit range
3 apiVersion: "v1"
4 kind: "LimitRange"
5 metadata:
6name: "project-limits"
7 spec:
8 limits:
9 - type: "Container"
10 default:
11 cpu: "250m
12 [student@workstation monitor-limit]$ oc create -f limits.yml #创建limit range
13 [student@workstation monitor-limit]$ oc describe limitrange #查看limit range
1 [student@workstation monitor-limit]$ cat quota.yml #创建配额2 apiVersion: v1
3 kind: ResourceQuota
4 metadata:
5name: project-quota
6 spec:
7 hard:
8 cpu: "900m"
9 [student@workstation monitor-limit]$ oc create -f quota.yml
10 [student@workstation monitor-limit]$ oc describe quota #确保创建了resource限制
2.7 授权项目
1 [student@workstation monitor-limit]$ oc adm policy add-role-to-user edit developer
2.8 验证资源限制
1 [student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com2 [student@workstation ~]$ oc project resources #选择项目
3 Already on project "resources" on server "https://master.lab.example.com:443".
4 [student@workstation ~]$ oc get limits #查看limit
5 NAME AGE
6 project-limits 14m
7 [student@workstation ~]$ oc delete limits project-limits #验证限制是否有效,但developer用户不能删除该限制
8 Error from server (Forbidden): limitranges "project-limits" is forbidden: User "developer" cannot delete limitranges in the namespace "resources": User "developer" cannot delete limitranges in project "resources"
9 [student@workstation ~]$ oc get quota
10 NAME AGE
11 project-quota 15m
2.9 创建应用
1 [student@workstation ~]$ oc new-app --name=hello2 --docker-image=registry.lab.example.com/openshift/hello-openshift
3 [student@workstation ~]$ oc get pod
4 NAME READY STATUS RESTARTS AGE
5 hello-1-t7tfn 1/1 Running 0 35s
2.10 查看quota
1 [student@workstation ~]$ oc describe quota2 Name: project-quota
3 Namespace: resources
4 Resource Used Hard
5 -------- ---- ----
6 cpu 250m 900m
2.11 查看节点可用资源
1 [student@workstation ~]$ oc login -u admin -p redhat2 https://master.lab.example.com
3 [student@workstation ~]$ oc get pod -o wide -n resources
4 [student@workstation ~]$ oc describe node node1.lab.example.com | grep -A 4 Allocated
5 [student@workstation ~]$ oc describe pod hello-1-t7tfn | grep -A2 Requests
2.12 扩容应用
1 [student@workstation ~]$ oc scale dc hello --replicas=2 #扩容应用2 [student@workstation ~]$ oc get pod #查看扩容后的pod
3 [student@workstation ~]$ oc describe quota #查看扩容后的quota情况
4 [student@workstation ~]$ oc scale dc hello --replicas=4 #继续扩容至4个
5 [student@workstation ~]$ oc get pod #查看扩容的pod
6 [student@workstation ~]$ oc describe dc hello | grep Replicas #查看replaces情况
结论:由于超过了配额规定,会提示控制器无法创建第四个pod。
2.13 添加配额请求
1 [student@workstation ~]$ oc scale dc hello --replicas=12 [student@workstation ~]$ oc get pod
3 [student@workstation ~]$ oc set resources dc hello --requests=memory=256Mi #设置资源请求
4 [student@workstation ~]$ oc get pod
5 [student@workstation ~]$ oc describe pod hello-2-4jvpw | grep -A 3 Requests
6 [student@workstation ~]$ oc describe quota #查看quota
结论:由上可知从项目的配额角度来看,没有什么变化。
2.14 增大配额请求
1 [student@workstation ~]$ oc set resources dc hello --requests=memory=8Gi #将内存请求增大到超过node最大值2 [student@workstation ~]$ oc get pod #查看pod
3 [student@workstation ~]$ oc logs hello-3-deploy #查看log
4 [student@workstation ~]$ oc status
结论:由于资源请求超过node最大值,最终显示一个警告,说明由于内存不足,无法将pod调度到任何节点。
三 OCP升级
3.1 升级OPENSHIFT
当OCP的新版本发布时,可以升级现有集群,以应用最新的增强功能和bug修复。这包括从以前的次要版本(如从3.7升级到3.9)升级,以及对次要版本(3.7)应用更新。
提示:OCP 3.9包含了Kubernetes 1.8和1.9的特性和补丁的合并。由于主要版本之间的核心架构变化,OpenShift Enterprise 2环境无法升级为OpenShift容器平台3,必须需要重新安装。
通常,主版本中不同子版本的node是向前和向后兼容的。但是,运行不匹配的版本的时间不应超过升级整个集群所需的时间。此外,不支持使用quick installer将版本3.7升级到3.9。
3.2 升级方式
有两种方法可以执行OpenShift容器平台集群升级,一种为in-place升级(可以自动升级或手动升级),也可以使用blue-green部署方法进行升级。
in-place升级:使用此方式,集群升级将在单个运行的集群中的所有主机上执行。首先升级master,然后升级node。在node升级开始之前,Pods被迁移到集群中的其他节点。这有助于减少用户应用程序的停机时间。
注意:对于使用quick和高级安装方法安装的集群,可以使用自动in-place方式升级。
当使用高级安装方法安装集群时,您可以通过重用它们的库存文件执行自动化或手动就地升级。
blue-green部署:blue-green部署是一种旨在减少停机时间同时升级环境的方法。在blue-green部署中,相同的环境与一个活动环境一起运行,而另一个环境则被更新。OpenShift升级方法标记了不可调度节点,并将pod调度到可用节点。升级成功后,节点将恢复到可调度状态。
3.3 执行自动化集群升级
使用高级安装方法,可以使用Ansible playbook自动化执行OpenShift集群升级过程。用于升级的剧本位于/usr/share/ansible/openshift-ansible/Playbooks/common/openshift-cluster/updates/中。该目录包含一组用于升级集群的子目录,例如v3_9。
注意:将集群升级到 OCP 3.9 前,集群必须已经升级到 3.7。集群升级一次不能跨越一个以上的次要版本,因此,如果集群的版本早于3.6,则必须先渐进地升级,例如从3.5升级到3.6,然后从3.6升级到3.7
要执行升级,可以使用ansible-playbook命令运行升级剧本,如使用v3_9 playbook将运行3.7版本的现有OpenShift集群升级到3.9版本。
自动升级主要执行以下任务:
- 应用最新的配置更改;
- 保存Etcd数据;
- 将api从3.7更新到3.8,然后从3.8更新到3.9;
- 如果存在,将默认路由器从3.7更新到3.9;
- 如果存在,则将默认仓库从3.7更新到3.9;
- 更新默认is和Templates。
注意:在继续升级之前,确保已经满足了所有先决条件,否则可能导致升级失败。
如果使用容器化的GlusterFS,节点将不会从pod中撤离,因为GlusterFS pod作为daemonset的一部分运行。要正确地升级运行容器化GlusterFS的集群,需要:
1:升级master服务器、Etcd和基础设施服务(route、内部仓库、日志记录和metric)。
2:升级运行应用程序容器的节点。
3:一次升级一个运行GlusterFS的节点。
注意:在升级之前,使用oc adm diagnostics命令验证集群的健康状况。这确认节点处于ready状态,运行预期的启动版本,并且没有诊断错误或警告。对于离线安装,使用--network-pod-image="REGISTRY URL/ IMAGE参数指定要使用的image。
3.4 准备自动升级
下面的过程展示了如何为自动升级准备环境,在执行升级之前,Red Hat建议检查配置Inventory文件,以确保对Inventory文件进行了手动更新。如果配置没有修改,则使用默认值覆盖更改。
- 如果这是从OCP 3.7升级到3.9,手动禁用3.7存储库,并在每个master节点和node节点上启用3.8和3.9存储库:
1 [root@demo ~]# subscription-manager repos2 --disable="rhel-7-server-ose-3.7-rpms"
3 --enable="rhel-7-server-ose-3.9-rpms"
4 --enable="rhel-7-server-ose-3.8-rpms"
5 --enable="rhel-7-server-rpms"
6 --enable="rhel-7-server-extras-rpms"
7 --enable="rhel-7-server-ansible-2.4-rpms"
8 --enable="rhel-7-fast-datapath-rpms"
9 [root@demo ~]# yum clean all
- 确保在每个RHEL 7系统上都有最新版本的atom-openshift-utils包,它还更新openshift-ansible-*包。
1 [root@demo ~]# yum update atomic-openshift-utils
- 在OpenShift容器平台的以前版本中,安装程序默认将master节点标记为不可调度,但是,从OCP 3.9开始,master节点必须标记为可调度的,这是在升级过程中自动完成的。
如果没有设置默认的节点选择器(如下配置),它们将在升级过程中添加。则master节点也将被标记为master节点角色。所有其他节点都将标记为compute node角色。
1 openshift_node_labels="{"region":"infra", "node-role.kubernetes.io/compute":"true"}
- 如果将openshift_disable_swap=false变量添加到的Ansible目录中,或者在node上手动配置swap,那么在运行升级之前禁用swap内存。
3.5 升级master节点和node节点
在满足了先决条件(如准备工作)之后,则可以按照如下步骤进行升级:
- 在清单文件中设置openshift_deployment_type=openshift-enterprise变量。
- 如果使用自定义Docker仓库,则必须显式地将仓库的地址指定为openshift_web_console_prefix和template_service_broker_prefix变量。这些值由Ansible在升级过程中使用。
1 openshift_web_console_prefix=registry.demo.example.com/openshift3/ose-2 template_service_broker_prefix=registry.demo.example.com/openshift3/ose-
- 如果希望重启service或重启node,请在Inventory文件中设置openshift_rolling_restart_mode=system选项。如果未设置该选项,则默认值表明升级过程在master节点上执行service重启,但不重启系统。
- 可以通过运行一个Ansible Playbook (upgrade.yml)来更新环境中的所有节点,也可以通过使用单独的Playbook分多个阶段进行升级。
- 重新启动所有主机,重启之后,如果没有部署任何额外的功能,可以验证升级。
3.6 分阶段升级集群
如果决定分多个阶段升级环境,根据Ansible Playbook (upgrade_control_plan .yml)确定的第一个阶段,升级以下组件:
- master节点;
- 运行master节点的节点services;
- Docker服务位于master节点和任何独立Etcd主机上。
第二阶段由upgrade_nodes.yml playbook,升级了以下组件。在运行此第二阶段之前,必须已经升级了master节点。
- node节点的服务;
- 运行在独立节点上的Docker服务。
两个阶段的升级过程允许通过指定自定义变量自定义升级的运行方式。例如,要升级总节点的50%,可以运行以下命令:
1 [root@demo ~]# ansible-playbook2 /usr/share/ansible/openshift-ansible/playbooks/common/openshift-cluster/upgrades/
3 v3_9/upgrade_nodes.yml
4 -e openshift_upgrade_nodes_serial="50%"
若要在HA region一次升级两个节点,请运行以下命令:
1 [root@demo ~]# ansible-playbook2 /usr/share/ansible/openshift-ansible/playbooks/common/openshift-cluster/upgrades/
3 v3_9/upgrade_nodes.yml
4 -e openshift_upgrade_nodes_serial="2"
5 -e openshift_upgrade_nodes_label="region=HA"
要指定每个更新批处理中允许有多少节点失败,可使用openshift_upgrade_nodes_max_fail_percent选项。当故障百分比超过定义的值时,Ansible将中止升级。
使用openshift_upgrade_nodes_drain_timeout选项指定中止play前等待的时间。
示例:如下所示一次升级10个节点,以及如果20%以上的节点(两个节点)失败,以及终止play执行的等待时间。
1 [root@demo ~]# ansible-playbook2 /usr/share/ansible/openshift-ansible/playbooks/common/openshift-cluster/upgrades/
3 v3_9/upgrade_nodes.yml
4 -e openshift_upgrade_nodes_serial=10
5 -e openshift_upgrade_nodes_max_fail_percentage=20
6 -e openshift_upgrade_nodes_drain_timeout=600
3.7 使用Ansible Hooks
可以通过hook为特定的操作执行定制的任务。hook允许通过定义在升级过程中特定点之前或之后执行的任务来扩展升级过程的默认行为。例如,可以在升级集群时验证或更新自定义基础设施组件。
提示:hook没有任何错误处理机制,因此,hook中的任何错误都会中断升级过程。需要修复hook并重新运行升级过程。
使用Inventory文件的[OSEv3:vars]部分来定义hook。每个hook必须指向一个.yaml文件,该文件定义了可能的任务。该文件是作为include语句的一部分集成的,该语句要求定义一组任务,而不是一个剧本。Red Hat建议使用绝对路径来避免任何歧义。
以下hook可用于定制升级过程:
1. openshift_master_upgrade_pre_hook:hook在更新每个master节点之前运行。
2. openshift_master_upgrade_hook:hook在每个master节点升级之后、主服务或节点重新启动之前运行。
3.openshift_master_upgrade_post_hook:hook在每个master节点升级并重启服务或系统之后运行。
示例:在库存文件中集成一个钩子。
1 [OSEv3:vars]2 openshift_master_upgrade_pre_hook=/usr/share/custom/pre_master.yml
3 openshift_master_upgrade_hook=/usr/share/custom/master.yml
4 openshift_master_upgrade_post_hook=/usr/share/custom/post_master.yml
如上示例,引入了一个pre_master.yml,包括了以下任务:
1 ---2 - name: note the start of a master upgrade
3 debug:
4 msg: "Master upgrade of {{ inventory_hostname }} is about to start"
5 - name: require an operator agree to start an upgrade pause:
6 prompt: "Hit enter to start the master upgrade"
3.8 验证升级
升级完成后,应该执行以下步骤以确保升级成功。
1 [root@demo ~]# oc get nodes #验证node处于ready2 [root@demo ~]# oc get -n default dc/docker-registry -o json | grep "image"
3#验证仓库版本
4 [root@demo ~]# oc get -n default dc/router -o json | grep "image
5#验证image版本
6 [root@demo ~]# oc adm diagnostics #使用诊断工具
3.9 升级步骤汇总
- 确保在每个RHEL 7系统上都有atom-openshift-utils包的最新版本。
- 如果使用自定义Docker仓库,可以选择将仓库的地址指定为openshift_web_console_prefix和template_service_broker_prefix变量。
- 禁用所有节点上的swap。
- 重新启动所有主机,重启之后,检查升级。
- 可选地:检查Inventory文件中的节点选择器。
- 禁用3.7存储库,并在每个master主机和node节点主机上启用3.8和3.9存储库。
- 通过使用合适的Ansible剧本集,使用单个或多个阶段策略进行更新。
- 在清单文件中设置openshift_deployment_type=openshift-enterprise变量。
四 使用probes监视应用
4.1 OPENSHIFT探针介绍
OpenShift应用程序可能会因为临时连接丢失、配置错误或应用程序错误等问题而异常。开发人员可以使用探针来监视他们的应用程序。探针是一种Kubernetes操作,它定期对正在运行的容器执行诊断。可以使用oc客户端命令或OpenShift web控制台配置探针。
目前,可以使用两种类型的探测:
- Liveness探针
Liveness探针确定在容器中运行的应用程序是否处于健康状态。如果Liveness探针返回检测到一个不健康的状态,OpenShift将杀死pod并试图重新部署它。开发人员可以通过配置template.spec.container.livenessprobe来设置Liveness探针。
- Readiness探针
Readiness探针确定容器是否准备好为请求服务,如果Readiness探针返回失败状态,OpenShift将从所有服务的端点删除容器的IP地址。开发人员可以使用Readiness探针向OpenShift发出信号,即使容器正在运行,它也不应该从代理接收任何流量。开发人员可以通过配置template.spec.containers.readinessprobe来设置Readiness探针。
OpenShift为探测提供了许多超时选项,有五个选项控制支持如上两个探针:
initialDelaySeconds:强制性的。确定容器启动后,在开始探测之前要等待多长时间。
timeoutSeconds:强制性的确定等待探测完成所需的时间。如果超过这个时间,OpenShift容器平台会认为探测失败。
periodSeconds:可选的,指定检查的频率。
successThreshold:可选的,指定探测失败后被认为成功的最小连续成功数。
failureThreshold:可选的,指定探测器成功后被认为失败的最小连续故障。
4.2 检查应用程序健康
Readiness和liveness probes可以通过三种方式检查应用程序的健康状况:
HTTP检查:当使用HTTP检查时,OpenShift使用一个webhook来确定容器的健康状况。如果HTTP响应代码在200到399之间,则认为检查成功。
示例:演示如何使用HTTP检查方法实现readiness probe 。
1 ...2 readinessProbe:
3 httpGet:
4path: /health #检测的URL
5 port: 8080 #端口
6 initialDelaySeconds: 15 #在容器启动后多久才能检查其健康状况
7 timeoutSeconds: 1 #要等多久探测器才能完成
8 ...
4.3 容器执行检查
当使用容器执行检查时,kubelet agent在容器内执行命令。退出状态为0的检查被认为是成功的。
示例:实现容器检查。
1 ...2 livenessProbe:
3 exec:
4 command:
5 - cat
6 - /tmp/health
7 initialDelaySeconds: 15
8 timeoutSeconds: 1
9 ...
4.4 TCP Socket检查
当使用TCP Socket检查时,kubelet agent尝试打开容器的socket。如果检查能够建立连接,则认为容器是健康的。
示例:使用TCP套接字检查方法实现活动探测。
1 ...2 livenessProbe:
3 tcpSocket:
4 port: 8080
5 initialDelaySeconds: 15
6 timeoutSeconds: 1
7 ...
4.5 使用Web管理probes
开发人员可以使用OpenShift web控制台管理readiness和liveness探针。对于每个部署,探针管理都可以从Actions下拉列表中获得。
对于每种探针类型,开发人员可以选择该类型,例如HTTP GET、TCP套接字或命令,并为每种类型指定参数。web控制台还提供了删除探针的选项。
web控制台还可以用于编辑定义部署配置的YAML文件。在创建探针之后,将一个新条目添加到DC的配置文件中。使用DC编辑器来检查或编辑探针。实时编辑器允许编辑周期秒、成功阈值和失败阈值选项。
五 使用探针监视应用程序实验
5.1 前置准备
准备完整的OpenShift集群,参考《003.OpenShift网络》2.1。
5.2 本练习准备
1 [student@workstation ~]$ lab probes setup5.3 创建应用
1 [student@workstation ~]$ oc login -u developer -p redhat2 https://master.lab.example.com
3 [student@workstation ~]$ oc new-project probes
4 [student@workstation ~]$ oc new-app --name=probes
5 http://services.lab.example.com/node-hello
6 [student@workstation ~]$ oc status
1 [student@workstation ~]$ oc get pods -w2 NAME READY STATUS RESTARTS AGE
3 probes-1-build 0/1 Completed 0 1m
4 probes-1-nqpwh 1/1 Running 0 12s
5.4 暴露服务
1 [student@workstation ~]$ oc expose svc probes --hostname=probe.apps.lab.example.com2 [student@workstation ~]$ curl http://probe.apps.lab.example.com
3 Hi! I am running on host -> probes-1-nqpwh
5.5 检查服务
1 [student@workstation ~]$ curl http://probe.apps.lab.example.com/health2 OK
3 [student@workstation ~]$ curl http://probe.apps.lab.example.com/ready
4 READY
5.6 创建readiness探针
使用Web控制台登录。并创建readiness探针。
Add readiness probe
参考5.5存在的用于检查健康的链接添加probe。
5.7 创建Liveness探针
使用Web控制台登录。并创建Liveness探针。
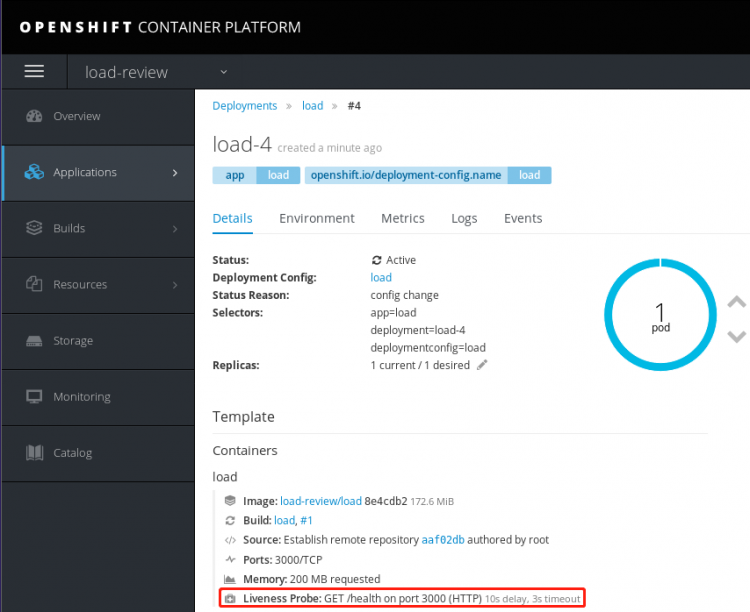
参考5.5存在的用于检查健康,特意使用healtz错误的值而不是health创建,从而测试相关报错。这个错误将导致OpenShift认为pod不健康,这将触发pod的重新部署。
提示:由于探针更新了部署配置,因此更改将触发一个新的部署。
5.8 确认探测
通过单击侧栏上的Monitoring查看探测的实现。观察事件面板的实时更新。此时将标记为不健康的条目,这表明liveness探针无法访问/healtz资源。
view details查看详情。
[student@workstation ~]$ oc get events --sort-by=".metadata.creationTimestamp" | grep "probe failed" #查看probe失败事件
5.9 修正probe
修正healtz为health。
5.10 再次确认
1 [student@workstation ~]$ oc get events2 --sort-by=".metadata.creationTimestamp"
#从终端重新运行oc get events命令,此时OpenShift在重新部署DC新版本,以及杀死旧pod。同时将不会有任何关于pod不健康的信息。
六 Web控制台使用
6.1 WEB控制台简介
OpenShift web控制台是一个可以从web浏览器访问的用户界面。它是管理和监视应用程序的一种方便的方法。尽管命令行界面可以用于管理应用程序的生命周期,但是web控制台提供了额外的优势,比如部署、pod、服务和其他资源的状态,以及
关于系统范围内事件的信息。
可使用Web查看基础设施内的重要信息,包括:
- pod各种状态;
- volume的可用性;
- 通过使用probes获得应用程序的健康行;
登录并选择项目之后,web控制台将提供项目项目的概述。
- 项目允许在授权访问的项目之间切换。
- Search Catalog:浏览image目录。
- Add to project:向项目添加新的资源和应用程序。可以从文件或现有项目导入资源。
- Overview:提供当前项目的高级视图。它显示service的名称及其在项目中运行的相关pod。
- Applications:提供对部署、pod、服务和路由的访问。它还提供了对Stateful set的访问,Kubernetes hat特性为pod提供了一个惟一的标识,用于管理部署的顺序。
- build:提供对构建和IS的访问。
- Resources:提供对配额管理和各种资源(如角色和端点)的访问。
- Storage:提供对持久卷和存储请求的访问。
- Monitoring选项卡提供对构建、部署和pod日志的访问。它还提供了对项目中各种对象的事件通知的访问。
- Catalog选项卡提供对可用于部署应用程序包的模板的访问。
6.2 使用HAWKULAR管理指标
Hawkular是一组用于监控环境的开源项目。它由各种组件组成,如Hawkular services、Hawkular Application Performance Management (APM)和Hawkular metrics。Hawkular可以通过Hawkular OpenShift代理在OpenShift集群中收集应用程序指标。通过在OpenShift集群中部署Hawkular,可以访问各种指标,比如pod使用的内存、cpu数量和网络使用情况。
在部署了Hawkular代理之后,web控制台可以查看各种pod的图表了。
6.3 管理Deployments和Pods
·Actions按钮可用于pod和部署,允许管理各种设置。例如,可以向部署添加存储或健康检查(包括准备就绪和活动探测)。该按钮还允许访问YAML编辑器,以便通过web控制台实时更新配置。
6.4 管理存储
web控制台允许访问存储管理,可以使用该接口创建卷声明,以使用向项目公开的卷。注意,该接口不能用于创建持久卷,因为只有管理员才能执行此任务。管理员创建持久性卷之后,可以使用web控制台创建请求。该接口支持使用选择器和标签属性。
定义卷声明之后,控制台将显示它所使用的持久性卷,这是由管理员定义的。、
七 Web控制台监控指标
7.1 前置准备
准备完整的OpenShift集群,参考《003.OpenShift网络》2.1。
同时安装OpenShift Metrics,参考《008.OpenShift Metric应用》3.1
7.2 本练习准备
1 [student@workstation ~]$ lab web-console setup7.3 创建项目
1 [student@workstation ~]$ oc login -u developer -p redhat2 https://master.lab.example.com
3 [student@workstation ~]$ oc new-project load
4 [student@workstation ~]$ oc new-app --name=load http://services.lab.example.com/node-hello
7.4 ·暴露服务
1 [student@workstation ~]$ oc expose svc load2 [student@workstation ~]$ oc get pod
3 NAME READY STATUS RESTARTS AGE
4load-1-build 1/1 Running 0 48s
7.5 压力测试
1 [student@workstation ~]$ sudo yum install httpd-tools2 [student@workstation ~]$ ab -n 3000000 -c 20
3 http://load-load.apps.lab.example.com/
7.6 控制台扩容pod
workstation节点上登录控制填,并扩展应用。
查看概览页面,确保有一个pod在运行。单击部署配置load #1,所显示的第一个图,它对应于pod使用的内存。并指示pod使用了多少内存,突出显示第二张图,该图表示pods使用的cpu数量。突出显示第三个图,它表示pod的网络流量。
单击pod视图圈旁的向上指向的箭头,将此应用程序的pod数量增加到两个。
导航到应用程序→部署以访问项目的部署
注意右侧的Actions按钮,单击它并选择Edit YAML来编辑部署配置。
检查部署的YAML文件,确保replicas条目的值为2,该值与为该部署运行的pod的数量相匹配。
7.7 查看metric
单击Metrics选项卡访问项目的度量,可以看到应用程序的四个图:使用的内存数量、使用的cpu数量、接收的网络数据包数量和发送的网络数据包数量。对于每个图,有两个图,每个图被分配到一个pod。
7.8 查看web控制监视
在侧窗格中,单击Monitoring以访问Monitoring页面。Pods部分下应该有两个条目,deployment部分下应该有一个条目。
向下滚动以访问部署,并单击部署名称旁边的箭头以打开框架。日志下面应该有三个图表:一个表示pod使用的内存数量,一个表示pod使用的cpu数量,一个表示pod发送和接收的网络数据包。
7.9 创建PV
为应用程序创建PVC,此练习环境已经提供了声明将绑定到的持久卷。
单击Storage创建持久卷声明,单击Create Storage来定义声明。输入web-storage作为名称。选择Shared Access (RWX)作为访问模式。输入1作为大小,并将单元保留为GiB
单击Create创建持久卷声明。
7.10 向应用程序添加存储
导航到应用程序——>部署来管理部署,单击load条目以访问部署。单击部署的Actions,然后选择Add Storage选项。此选项允许将现有的持久卷声明添加到部署配置的模板中。选择web-storage作为存储声明,输入/web-storage作为挂载路径,web-storage作为卷名。
7.11 检查存储
从deployment页面中,单击由(latest)指示的最新部署。等待两个副本被标记为活动的。确保卷部分将卷web存储作为持久卷。从底部的Pods部分中,选择一个正在运行的Pods。单击Terminal选项卡打开pod的外壳。
也可在任何一个pod中运行如下命令查看:
八 管理和监控OpenShift
8.1 前置准备
准备完整的OpenShift集群,参考《003.OpenShift网络》2.1。
8.2 本练习准备
1 [student@workstation ~]$ lab review-monitor setup8.3 创建项目
1 [student@workstation ~]$ oc login -u developer -p redhat https://master.lab.example.com、2 [student@workstation ~]$ oc new-project load-review
8.4 创建limit range
1 [student@workstation ~]$ oc login -u admin -p redhat2 [student@workstation ~]$ oc project load-review
3 [student@workstation ~]$ cat /home/student/DO280/labs/monitor-review/limits.yml
4 apiVersion: "v1"
5 kind: "LimitRange"
6 metadata:
7name: "review-limits"
8 spec:
9 limits:
10 - type: "Container"
11 max:
12 memory: "300Mi"
13 default:
14 memory: "200Mi"
15 [student@workstation ~]$ oc create -f /home/student/DO280/labs/monitor-review/limits.yml
16 [student@workstation ~]$ oc describe limitrange
17 Name: review-limits
18 Namespace: load-review
19 Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
20 ---- -------- --- --- --------------- ------------- -----------------------
21 Container memory - 300Mi 200Mi 200Mi -
8.5 创建应用
1 [student@workstation ~]$ oc login -u developer -p redhat2 [student@workstation ~]$ oc new-app --name=load http://services.lab.example.com/node-hello
3 [student@workstation ~]$ oc get pods
4 NAME READY STATUS RESTARTS AGE
5load-1-6szhm 1/1 Running 0 6s
6load-1-build 0/1 Completed 0 43s
7 [student@workstation ~]$ oc describe pod load-1-6szhm
8.6 扩大资源请求
1 [student@workstation ~]$ oc set resources dc load --requests=memory=350M2 [student@workstation ~]$ oc get events | grep Warning
结论:请求资源超过limit限制,则会出现如上告警。
1 [student@workstation ~]$ oc set resources dc load --requests=memory=200Mi
8.7 创建ResourceQuota
1 [student@workstation ~]$ oc status ; oc get pod1 [student@workstation ~]$ oc login -u admin -p redhat2 [student@workstation ~]$ cat /home/student/DO280/labs/monitor-review/quotas.yml
3 apiVersion: "v1"
4 kind: "LimitRange"
5 metadata:
6name: "review-limits"
7 spec:
8 limits:
9 - type: "Container"
10 max:
11 memory: "300Mi"
12 default:
13 memory: "200Mi"
14 [student@workstation ~]$ oc create -f /home/student/DO280/labs/monitor-review/quotas.yml
15 [student@workstation ~]$ oc describe quota
16 Name: review-quotas
17 Namespace: load-review
18 Resource Used Hard
19 -------- ---- ----
20 requests.memory 200M 600Mi -
8.8 创建应用
1 [student@workstation ~]$ oc login -u developer -p redhat2 [student@workstation ~]$ oc scale --replicas=4 dc load
3 [student@workstation ~]$ oc get pods
4 NAME READY STATUS RESTARTS AGE
5load-1-build 0/1 Completed 0 7m
6load-3-577fc 1/1 Running 0 5s
7load-3-nnncf 1/1 Running 0 4m
8load-3-nps4w 1/1 Running 0 5s
9 [student@workstation ~]$ oc get events | grep Warning
结论:当前已应用配额规定会阻止创建第四个pod。
1 [student@workstation ~]$ oc scale --replicas=1 dc load
8.9 暴露服务
1 [student@workstation ~]$ oc expose svc load --hostname=load-review.apps.lab.example.com
8.10 创建探针
Web控制台创建。
Applications ——> Deployments ——> Actions ——> Edit Health Checks。
9.11 确认验证
导航到Applications ——> Deployments,选择应用程序的最新部署。
在Template部分中,找到以下条目:
1 [student@workstation ~]$ lab review-monitor grade #脚本判断结果2
原文链接:https://www.cnblogs.com/itzgr/archive/2020/06/22/13179348.html
以上是 009.OpenShift管理及监控 的全部内容, 来源链接: utcz.com/z/517720.html