如何实现MySQL的读写分离?

面试题
你们有没有做 MySQL 读写分离?如何实现 MySQL 的读写分离?MySQL 主从复制原理的是啥?如何解决 MySQL 主从同步的延时问题?
面试官心理分析
高并发这个阶段,肯定是需要做读写分离的,啥意思?因为实际上大部分的互联网公司,一些网站,或者是 app,其实都是读多写少。所以针对这个情况,就是写一个主库,但是主库挂多个从库,然后从多个从库来读,那不就可以支撑更高的读并发压力了吗?
面试题剖析
如何实现 MySQL 的读写分离?
其实很简单,就是基于主从复制架构,简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
MySQL 主从复制原理的是啥?
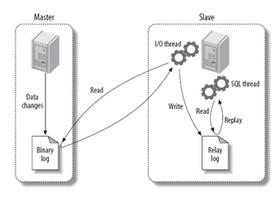
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
所以 MySQL 实际上在这一块有两个机制,一个是半同步复制,用来解决主库数据丢失问题;一个是并行复制,用来解决主从同步延时问题。
这个所谓半同步复制,也叫 semi-sync 复制,指的就是主库写入 binlog 日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 给主库,主库接收到至少一个从库的 ack 之后才会认为写操作完成了。
所谓并行复制,指的是从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
MySQL 主从同步延时问题(精华)
以前线上确实处理过因为主从同步延时问题而导致的线上的 bug,属于小型的生产事故。
是这个么场景。有个同学是这样写代码逻辑的。先插入一条数据,再把它查出来,然后更新这条数据。在生产环境高峰期,写并发达到了 2000/s,这个时候,主从复制延时大概是在小几十毫秒。线上会发现,每天总有那么一些数据,我们期望更新一些重要的数据状态,但在高峰期时候却没更新。用户跟客服反馈,而客服就会反馈给我们。
我们通过 MySQL 命令:
show status查看 Seconds_Behind_Master,可以看到从库复制主库的数据落后了几 ms。
一般来说,如果主从延迟较为严重,有以下解决方案:
- 分库,将一个主库拆分为多个主库,每个主库的写并发就减少了几倍,此时主从延迟可以忽略不计。
- 打开 MySQL 支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到了 2000/s,并行复制还是没意义。
- 重写代码,写代码的同学,要慎重,插入数据时立马查询可能查不到。
- 如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,你要是这么搞,读写分离的意义就丧失了。
关注我的微信公众号,第一时间获得我的博客的更新提醒,更有惊喜等着你哟~
扫一扫下方二维码或搜索微信号shenshan_laoyuan关注
本篇文章由一文多发平台ArtiPub自动发布
以上是 如何实现MySQL的读写分离? 的全部内容, 来源链接: utcz.com/z/516877.html