【集合】HashMap的底层实现原理

- HashMap的工作原理
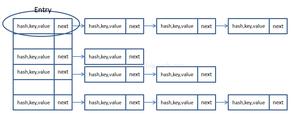
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对
HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
以上是 【集合】HashMap的底层实现原理 的全部内容, 来源链接: utcz.com/z/516830.html