raft一致性算法简单解释

1. 理解分布式一致性问题
- 假设我们的分布式系统只有一个节点,我们可以认为他是一个数据库服务端,存储了一个整型数据
- 我们还有一个客户端,用于访问系统该数据库的数据(读/写)
one-node-system.png
显然,对已只有一个节点的系统,我们写操作很简单的得到满足
multi-node-system.png
这就是分布式系统的一致性问题。
在分布式环境中, 一致性是指数据在多个副本之间是否能够保持一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作之后, 应该能够保证系统的数据仍然处于一致的状态。
对于一个将数据副本分别在不同分布式节点上的系统来说,如果对于第一个节点的数据进行了更新操作,并且成功更新之后,却没有使得其他节点上的数据得到相应的更新,于是在对第二个节点的数据进行读操作时,获取的是老数据(脏数据),这就是典型的分布式数据不一致的情况。
在一个分布式系统中,如果能够做到针对一个数据项的更新操作执行成功之后,所有的用户都可以读取到其中的最新值,那么这样的系统就被认为是具有强一致性(严格一致性)。
当然,在有些分布式系统实现中,并不需要实时保证系统数据的强一致性,它允许数据存在中间状态,并认为该中间状态不会影响系统的整体可用性(允许数据在不同节点之间的同步存在延时),在经过一段时间之后,最终能够达到一个一致的状态,这就是最终一致性(弱一致性)。
2. Raft过程概述
- 在raft中,一个节点可以有三种状态
status.png
- 所有的节点初始状态都是Follower状态
- 如果没有收到来之Leader的消息,则节点自举为Candidate状态
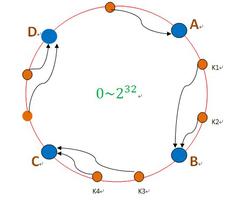
- Candidate节点然后向其他节点广播投票请求,参考下图
- 假如Candidate获取到超过半数的选票,当然,自动升级成Leader了
选举过程要求节点为奇数(包括自身节点),否则可能出现选票无法超过一半的情况,无法选举出Leader
以上过程就是Leader Election
leader-election.png
- Leader选择出来之后,所有对分布式系统的修订操作都直接作用于Leader节点上了。
- 所有操作都会向节点添加log(redo/undo等)
- Log并不立即提交,因此节点的值并不会立即更新
- Leader通告Follower操作,Follower也添加log,但是未提交
log.png
- Follower反馈
- Leader收到Follower反馈之后,执行提交操作,节点值更新
- Leader更新之后,通告Follower更新
- 整个过程完成
report.png
commit.png
3. Leader Election
status-machine.png
- 所有节点初始状态为Follower
- Follower等待Election timeout(150ms~300ms),超时将自举成Candidate
- Election timeout之后,node成为Candidate,开始新的周期
- Candidate vote for itself and send vote request to other nodes
vote-1.png
- Follower收到vote request之后,开启新的周期,同时反馈vote信息
- Candidate收到Follower的vote反馈之后,就升级成Leader(必须半数以上的反馈才算是选举成功,包括自身)
- Leader开始周期性发送Append Entries消息给Follower,作为保活消息,这个消息发送间隔为heartbeat timeout
- Follower收到append entries消息之后做出回应,然后重置heartbeat timeout
- 以上过程将持续进行,直到某个follower不再收到heartbeats,并且在election timeout之后自举成candidate,开始一个新的周期
vote-2.png
vote-3.png
- 假如现在停止Leader的append entries,在heartbeats timeout 和 election timeout之后, B或C将有一个节点自举成candidate
- 开始新一轮的Leader选举过程,结果如下图所示
在第二个周期,C节点成为了Leader,A节点已经down掉了
注意:奇数个节点参与竞选Leader是个重要的要求,否则,将有可能无法达成多数个节点投票的条件,导致无法选出leader
vote-4.png
4. Log Replication
一旦选出了Leader节点,我们需要将Leader上的修订同步到所有的其他节点上,以满足分布式系统的一致性原则,这个过程是通过Append Entries消息实现的。
- 首先, client对leader写操作, leader生成操作log,但是还没提交
- Leader在下一个心跳周期通告所有的follower操作log
- Follower收到通告之后,生成操作log,同时反馈给leader
- 当Leader收到大多数的Follower反馈成功之后,将进行commit操作,leader上的节点更新成功
- Leader更新成功之后,反馈给Client
- 下一个heartbeat,Follower收到Leader的消息之后,将commit log,更新节点
以上具体过程可以参考第2小节中的图片描述
Raft算法的动画演示
http://thesecretlivesofdata.com/raft/
以上是 raft一致性算法简单解释 的全部内容, 来源链接: utcz.com/z/514775.html