解决Redis分布式锁业务代码超时导致锁失效问题

1、redis分布式锁" title="redis分布式锁">redis分布式锁的基本实现
redis加锁命令:
SETNX resource_name my_random_value PX 30000 这个命令的作用是在只有这个key不存在的时候才会设置这个key的值(NX选项的作用),超时时间设为30000毫秒(PX选项的作用) 这个key的值设为“my_random_value”。这个值必须在所有获取锁请求的客户端里保持唯一。
SETNX 值保持唯一的是为了确保安全的释放锁,避免误删其他客户端得到的锁。举个例子,一个客户端拿到了锁,被某个操作阻塞了很长时间,过了超时时间后自动释放了这个锁,然后这个客户端之后又尝试删除这个其实已经被其他客户端拿到的锁。所以单纯的用DEL指令有可能造成一个客户端删除了其他客户端的锁,通过校验这个值保证每个客户端都用一个随机字符串’签名’了,这样每个锁就只能被获得锁的客户端删除了。
既然释放锁时既需要校验这个值又需要删除锁,那么就需要保证原子性,redis支持原子地执行一个lua脚本,所以我们通过lua脚本实现原子操作。代码如下:
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1])
else
return 0
end
2、业务逻辑执行时间超出锁的超时限制导致两个客户端同时持有锁的问题
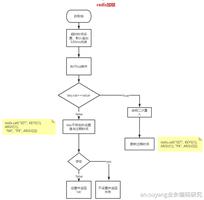
如果在加锁和释放锁之间的逻辑执行得太长,以至于超出了锁的超时限制,就会出现问题。因为这时候第一个线程持有的锁过期了,临界区的逻辑还没有执行完,这个时候第二个线程就提前重新持有了这把锁,导致临界区代码不能得到严格的串行执行。
不难发现正常情况下锁操作完后都会被手动释放,常见的解决方案是调大锁的超时时间,之后若再出现超时带来的并发问题,人工介入修正数据。这也不是一个完美的方案,因为但业务逻辑执行时间是不可控的,所以还是可能出现超时,当前线程的逻辑没有执行完,其它线程乘虚而入。并且如果锁超时时间设置过长,当持有锁的客户端宕机,释放锁就得依靠redis的超时时间,这将导致业务在一个超时时间周期内不可用。
基本上,如果在执行计算期间发现锁快要超时了,客户端可以给redis服务实例发送一个Lua脚本让redis服务端延长锁的时间,只要这个锁的key还存在而且值还等于客户端设置的那个值。 客户端应当只有在失效时间内无法延长锁时再去重新获取锁(基本上这个和获取锁的算法是差不多的)。
启动另外一个线程去检查的问题,这个key是否超时,在某个时间还没释放。
当锁超时时间快到期且逻辑未执行完,延长锁超时时间的伪代码:
if redis.call("get",KEYS[1]) == ARGV[1] then redis.call("set",KEYS[1],ex=3000)
else
getDLock();//重新获取锁
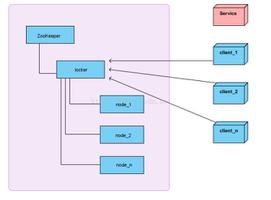
3、redis的单点故障主从切换带来的两个客户端同时持有锁的问题
生产中redis一般是主从模式,主节点挂掉时,从节点会取而代之,客户端上却并没有明显感知。原先第一个客户端在主节点中申请成功了一把锁,但是这把锁还没有来得及同步到从节点,主节点突然挂掉了。然后从节点变成了主节点,这个新的节点内部没有这个锁,所以当另一个客户端过来请求加锁时,立即就批准了。这样就会导致系统中同样一把锁被两个客户端同时持有,不安全性由此产生。
不过这种不安全也仅仅是在主从发生 failover 的情况下才会产生,而且持续时间极短,业务系统多数情况下可以容忍。
4、RedLock算法
如果你很在乎高可用性,希望挂了一台 redis 完全不受影响,可以考虑 redlock。 Redlock 算法是由Antirez 发明的,它的流程比较复杂,不过已经有了很多开源的 library 做了良好的封装,用户可以拿来即用,比如 redlock-py。
import redlock addrs = [{
"host": "localhost",
"port": 6379,
"db": 0
}, {
"host": "localhost",
"port": 6479,
"db": 0
}, {
"host": "localhost",
"port": 6579,
"db": 0
}]
dlm = redlock.Redlock(addrs)
success = dlm.lock("user-lck-laoqian", 5000)
if success:
print "lock success"
dlm.unlock("user-lck-laoqian")
else:
print "lock failed"
RedLock算法的核心原理:
使用N个完全独立、没有主从关系的Redis master节点以保证他们大多数情况下都不会同时宕机,N一般为奇数。一个客户端需要做如下操作来获取锁:
1.获取当前时间(单位是毫秒)。
2.轮流用相同的key和随机值在N个节点上请求锁,在这一步里,客户端在每个master上请求锁时,会有一个和总的锁释放时间相比小的多的超时时间。比如如果锁自动释放时间是10秒钟,那每个节点锁请求的超时时间可能是5-50毫秒的范围,这个可以防止一个客户端在某个宕掉的master节点上阻塞过长时间,如果一个master节点不可用了,我们应该尽快尝试下一个master节点。
3.客户端计算第二步中获取锁所花的时间,只有当客户端在大多数master节点上成功获取了锁((N/2) +1),而且总共消耗的时间不超过锁释放时间,这个锁就认为是获取成功了。
4.如果锁获取成功了,那现在锁自动释放时间就是最初的锁释放时间减去之前获取锁所消耗的时间。
5.如果锁获取失败了,不管是因为获取成功的锁不超过一半(N/2+1)还是因为总消耗时间超过了锁释放时间,客户端都会到每个master节点上释放锁,即便是那些他认为没有获取成功的锁。
5、知识扩展
5.1为什么lua脚本结合redis命令可以实现原子性
Redis 提供了非常丰富的指令集,但是用户依然不满足,希望可以自定义扩充若干指令来完成一些特定领域的问题。Redis 为这样的用户场景提供了 lua 脚本支持,用户可以向服务器发送 lua 脚本来执行自定义动作,获取脚本的响应数据。Redis 服务器会单线程原子性执行 lua 脚本,保证 lua 脚本在处理的过程中不会被任意其它请求打断。
5.2 redis 可重入分布式锁
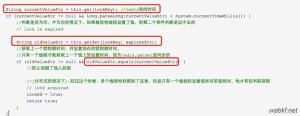
要实现可重入锁,方法很简单,当加锁失败时判断锁的值是不是跟当前线程设置值相同,伪代码如下:
if setnx == 0 if get(key) == my_random_value
//重入
else
//不可重入
else
//获取了锁,等价于可重入
本文由博客一文多发平台 OpenWrite 发布!
以上是 解决Redis分布式锁业务代码超时导致锁失效问题 的全部内容, 来源链接: utcz.com/z/514722.html