来自淘宝的分布式数据层TDDL

就目前而言,许多大厂也在出一些更加优秀和社区支持更广泛的DAL层产品,比如Hibernate Shards、Ibatis-Sharding等。TDDL位于数据库和持久层之间,它直接与数据库建立交道,如图所示:
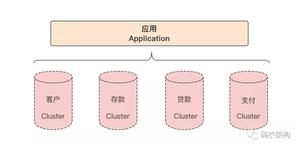
淘宝很早就对数据进行过分库的处理,上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作一个数据库一样操作多个库。但是随着数据量的增长,对于库表的分法有了更高的要求,例如,你的商品数据到了百亿级别的时候,任何一个库都无法存放了,于是分成2个、4个、8个、16个、32个……直到1024个、2048个。好,分成这么多,数据能够存放了,那怎么查询它?这时候,数据查询的中间件就要能够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。下图展示了一个简单的分库分表数据查询策略:
TDDL的主要优点:
1、数据库主备和动态切换2、带权重的读写分离
3、单线程读重试
4、集中式数据源信息管理和动态变更
5、剥离的稳定jboss数据源
6、支持mysql和oracle数据库
7、基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8、无server,client-jar形式存在,应用直连数据库
9、读写次数,并发度流程控制,动态变更
10、可分析的日志打印,日志流控,动态变更12345678910
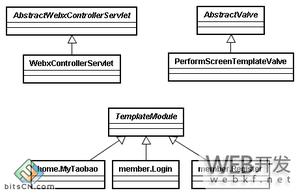
TDDL的体系架构
TDDL其实主要可以划分为3层架构,分别是Matrix层、Group层和Atom层。
**Matrix层:**用于实现分库分表逻辑,底层持有多个Group实例。而Group层和Atom共同组成了动态数据源, **Group层:**实现了数据库的Master/Salve模式的写分离逻辑,底层持有多个Atom实例。
**Atom层 (TAtomDataSource):**实现数据库ip,port,password,connectionProperties等信息的动态推送,以及持有原子的数据源分离的JBOSS数据源)。
持久层只关心对数据源的CRUD操作,而多数据源的访问并不应该由它来关心。也就是说TDDL透明给持久层的数据源接口应该是统一且“单一”的,至于数据库到底如何分库分表持久层无需知道也无需编写对应的SQL去实行应对策略。这个时候对TDDL一些疑问就出现了,TDDL需要对SQL进行二次解析和拼装吗?答案是不解析仅拼装。TDDL只需要从持久层拿到发出的SQL再按照一些分库分表条件,进行特定的SQL扩充以此满足访问路路由操作。
TDDL除了拿到分库分表条件外,还需要拿到order by、group by、limit、join等信息,SUM、MAX、MIN等聚合函数信息,DISTINCT信息。具有这些关键字的SQL将会在单库和多库情况下进行,语义是不同的。TDDL必须对使用这些关键字的SQL返回的结果做出合适的处理;
TDDL行复制需重新拼写SQL,带上sync_version字段。不通过SQL解析,因为TDDL遵守JDBC规范,它不可能去扩充JDBC规范里面的接口,所以只能通过SQL中加额外的字符条件(也就是HINT方式)或者ThreadLocal方式进行传递,前者使SQL过长,后者难以维护,开发debug时不容易跟踪,而且需要判定是在一条SQL执行后失效还是1个连接关闭后才失效;
TDDL现在也同时支持Hint方式和ThreadLocal方式传递这些信息;
参考地址
- https://blog.csdn.net/diu_brother/article/details/51554555
- https://github.com/alibaba/tb_tddl
如果大家喜欢我的文章,可以关注个人订阅号。欢迎随时留言、交流。如果想加入微信群的话一起讨论的话,请加管理员简栈文化-小助手(lastpass4u),他会拉你们进群。
以上是 来自淘宝的分布式数据层TDDL 的全部内容, 来源链接: utcz.com/z/513829.html