数据库水平切分方法
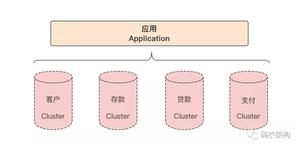
在大中型项目中,在数据库设计的时候,考虑到数据库最大承受数据量,通常会把数据库或者数据表水平切分,以降低单个库,单个表的压力。我这里介绍两个我们项目中常用的数据表切分方法。当然这些方法都是在程序中使用一定的技巧来路由到具体的表的。首先我们要确认根据什么来水平切分?在我们的系统(SNS)中,用户的 UID 贯穿系统,唯一自增长,根据这个字段分表,再好不过。
方法一:使用 MD5 哈希
做法是对 UID 进行 md5 加密,然后取前几位(我们这里取前两位),然后就可以将不同的 UID 哈希到不同的用户表(user_xx)中了。
function getTable( $uid ){ $ext = substr ( md5 ( $uid ) , 0 , 2 );
return " user_ " . $ext ;
}
通过这个技巧,我们可以将不同的 UID 分散到 256 中用户表中,分别是 user_00,user_01 …… user_ff。因为 UID 是数字且递增,根据 md5 的算法,可以将用户数据几乎很均匀的分别到不同的 user 表中。
但是这里有个问题是,如果我们的系统的用户越来越多,势必单张表的数据量越来越大,而且根据这种算法无法扩展表,这又会回到文章开头出现的问题了。
方法二:使用移位
具体方法是:
public function getTable( $uid ) { return " user_ " . sprintf ( " %04d " , ( $uid >> 20 ) );
}
这里,我们将 uid 向右移动 20 位,这样我们就可以把大约前 100 万的用户数据放在第一个表 user_0000,第二个 100万 的用户数据放在第二个表 user_0001 中,这样一直下去,如果我们的用户越来越多,直接添加用户表就行了。由于我们保留的表后缀是四位,这里我们可以添加 1 万张用户表,即 user_0000,user_0001 …… user_9999。一万张表,每张表 100万 数据,我们可以存 100 亿条用户记录。当然,如果你的用户数据比这还多,也不要紧,你只要改变保留表后缀来增加可以扩展的表就行了,如如果有 1000 亿条数据,每个表存 100万,那么你需要 10 万张表,我们只要保留表后缀为 6 位即可。
上面的算法还可以写的灵活点:
/* * * 根据UID分表算法 ** @param int $uid //用户ID
* @param int $bit //表后缀保留几位
* @param int $seed //向右移动位数
*/
function getTable( $uid , $bit , $seed ){
return " user_ " . sprintf ( " %0{ $bit }d " , ( $uid >> $seed ) );
}
总结
上面两种方法,都要对我们当前系统的用户数据量做出可能最大的预估,并且对数据库单个表的最大承受量做出预估。
比如第二种方案,如果我们预估我们系统的用户是 100 亿,单张表的最优数据量是 100 万,那么我们就需要将 UID 移动20来确保每个表是 100 万的数据,保留用户表(user_xxxx)四位来扩展1万张表。
又如第一种方案,每张表 100 万,md5 后取前两位,就只能有 256 张表了,系统总数据库就是:256*100万;如果你系统的总数据量的比这还多,那你实现肯定要 MD5 取前三位或者四位甚至更多位了。
两种方法都是将数据水平切分到不同的表中,相对第一种方法,第二种方法更具扩展性。
以上是 数据库水平切分方法 的全部内容, 来源链接: utcz.com/z/264566.html