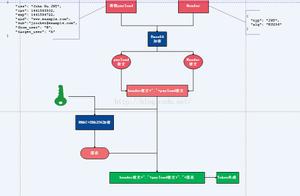
ZooKeeperWatcher机制

从上图可以看到,Watcher 机制包括三个角色:客户端线程、客户端的 WatchManager 以及 ZooKeeper 服务器。Watcher 机制就是这三个角色之间的交互,整个过程分为注册、存储和通知三个步骤:
- 客户端向 ZooKeeper 服务器注册一个 Watcher 监听,
- 把这个监听信息存储到客户端的 WatchManager 中
- 当 ZooKeeper 中的节点发生变化时,会通知客户端,客户端会调用相应 Watcher 对象中的回调方法。
了解了整体的流程之后,接下来就来看下一些细节问题。
客户端处理
要了解 Watcher 机制,首先我们得知道什么时候客户端可以注册一个 Watcher 呢?通过查看 API 我们可以了解到,**在创建 ZooKeeper 对象,或者是在读取数据时(即调用 getData、exists、getChildren 方法)可以注册一个 Watcher 监听,**他们内部的实现都是一样的,这里我们就以 getData 方法为例来探究下 Watcher 机制的实现。
/** * ZooKeeper.java
*/
public byte[] getData(String path, Watcher watcher, Stat stat) throws KeeperException, InterruptedException {
ZooKeeper.WatchRegistration wcb = null;
if (watcher != null) {
wcb = new ZooKeeper.DataWatchRegistration(watcher, path);
}
// ...
GetDataRequest request = new GetDataRequest();
request.setPath(serverPath);
request.setWatch(watcher != null);
ReplyHeader r = this.cnxn.submitRequest(h, request, response, wcb);
// ...
}
/**
* ClientCnxn.java
*/
public ReplyHeader submitRequest(RequestHeader h, Record request,
Record response, WatchRegistration watchRegistration,
WatchDeregistration watchDeregistration)
throws InterruptedException {
ReplyHeader r = new ReplyHeader();
Packet packet = queuePacket(h, r, request, response, null, null, null,
null, watchRegistration, watchDeregistration);
// ...
}
通过上面的代码我们可以了解到,Watcher 对象和其监听的路径会被封装在 WatchRegistration 对象中,然后在 ClientCnxn 还会被封装在 Packet 对象中。这个 Packet 可以被看做是一个最小的通信协议单元,用于进行客户端与服务端之间的网络传输。封装完成之后,将该请求发送给服务端,发送成功后,将 Watcher 相关信息存储到客户端的 ZKWatchManager 对象中,至此客户端的做的工作也就完成了。
不过,这里有一个细节问题,是不是每调用一次 getData 客户端都会把整个 Watcher 对象发送给客户端呢?如果是这样的话,多次 getData 的调用就会导致服务端内存的紧张,我们来看下 ZooKeeper 是怎么处理这个问题的。
/** * Packet.java
*/
public void createBB() {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
boa.writeInt(-1, "len"); // We"ll fill this in later
if (requestHeader != null) {
requestHeader.serialize(boa, "header");
}
if (request instanceof ConnectRequest) {
request.serialize(boa, "connect");
// append "am-I-allowed-to-be-readonly" flag
boa.writeBool(readOnly, "readOnly");
}
}
}
通过查看 Packet 内部的 createBB 方法我们可以看到,**Packet 在进行网络传输时仅仅是把 requestHeader 和 request 两个属性进行序列化,虽然 Watcher 被封装在 Packet 中,但是其并不会通过网络传输给服务端。**request 对象里面的内容可以看上面 ZooKeeper 类中的 Request 对象,它主要给该 Packet 添加一个标识,让服务端判断该请求是否包含 Watcher 监听。
服务端处理
在源码中,服务端是由 ZooKeeperServer 实现的,在其内部,是由 RequestProcessor 接口来处理客户端的请求,我们来看下其中的一个实现类 FinalRequestProcessor。
/** * FinalRequestProcessor
*/
public void processRequest(Request request) {
// ...
ServerCnxn cnxn = request.cnxn;
case OpCode.getData: {
// ...
byte b[] = zks.getZKDatabase().getData(getDataRequest.getPath(), stat,
getDataRequest.getWatch() ? cnxn : null);
break;
}
}
当 FinalRequestProcesor 判断到该请求是一个 Watcher 监听时,会把 ServerCnxn 对象和监听路径传到 getData 方法里面去。这个 ServerCnxn 是什么呢?它是一个 ZooKeeper 客户端和服务端之间的连接接口,代表了一个客户端和服务器的连接,并且实现了 Watcher 的 process 方法,它最终会交由给 WatchManager 管理。
除了管理 Watcher,WatcherManager 还负责 Watcher 事件的触发,并移除那些已经被触发的 Watcher。由于其管理的 ServerCnxn 已经实现了 process 方法,因此当监听对象发生变化时,它就会调用 ServerCnxn 的 process 方法。
/** * NIOServerCnxn
*/
public void process(WatchedEvent event) {
ReplyHeader h = new ReplyHeader(-1, -1L, 0);
WatcherEvent e = event.getWrapper();
sendResponse(h, e, "notification");
}
我们可以看到,服务端执行的逻辑很简单,只是在请求头中标记 -1,表明当前是一个通知,然后将该请求发送给客户端,具体的回调逻辑都是在客户端执行的。
客户端回调 Watcher
客户端在和 ZooKeeper 建立连接时,会启动 sendThread 和 eventThread 线程。
sendThread 线程负责发送请求给服务端,同时也接收服务端发送过来的响应,当它判断到响应中的 XID 标识为 -1,便将它作为一个通知类型的响应,将响应中的信息进行序列化,交给 eventThread 线程处理。
eventThread 会根据响应内容判断该通知对应的 Watcher 类型,从 ZKWatchManager 中取出所有相关的 Watcher,然后放到 waitingEvents 队列中,该队列时一个待处理 Watcher 的队列,eventThrad 每次从中取出一个 Watcher,然后进行串行同步处理,就是依次调用队列中 Watcher 的 process 的方法。
Watcher 特性总结
上面就是 Watcher 机制的整个执行流程了,最后就简单说下我认为 Watcher 机制中两个比较显著的特点。
第一个就是一次性,在整个流程中,不管是服务端还是客户端在处理 Watcher,当 Watcher 触发之后,就会将他们从本地内存中去除掉,如果还需要监听的话就需要反复注册。如果注册一个 Watcher 一直有效的话,那么当更新频繁时,对网络带宽和服务器的压力是很大的。
第二个就是轻量,客户端发送给服务器的请求中只是表明该请求是对哪个路径的监听,并没有把全部信息传给服务端,服务端给客户端做响应也是如此,它只是告诉它监听的节点或子列表发生变化了,具体的变化信息需要重新去服务端获取,这个轻量的设计使得网络带宽和服务器的压力大大减小了。
以上是 ZooKeeperWatcher机制 的全部内容, 来源链接: utcz.com/z/513803.html