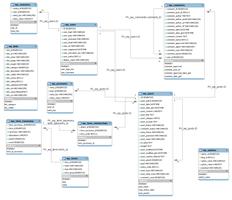
shardingsphere4.0.0RC1版本按年分表(后续优化)

现在面对的问题是LogShardingAlgorithm的实例化是在Spring初始化中间执行的,且它本身的创建不是通过Spring的@Component等注解生成,而是通过反射实例化。若在实例化刚开始,也就是构造方法执行的时候执行初始化,那时候applicationContext还没有初始化完毕,拿不到环境参数,连Datasource也还没开始初始化
1.2. 解决方法
经过改造后,代码如下,单独拎出一个初始化方法,在类对象实例化后调用
/** * @author: laoliangliang
* @description: 日志分片
* @create: 2020/1/2 10:19
**/
@Slf4j
public class LogShardingAlgorithm implements PreciseShardingAlgorithm, RangeShardingAlgorithm<Integer> {
/**
* 缓存存在的表
*/
private List<String> tables;
private final String systemLogHead = "system_log_";
public void init(){
tables = DBUtil.getAllSystemLogTable();
}
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
String target = shardingValue.getValue().toString();
String year = target.substring(target.lastIndexOf("_") + 1, target.lastIndexOf("_") + 5);
if (!tables.contains(systemLogHead + year)) {
DBUtil.createLogTable(year);
tables.add(year);
}
return shardingValue.getLogicTableName() + "_" + year;
}
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Integer> shardingValue) {
Collection<String> availables = new ArrayList<>();
Range valueRange = shardingValue.getValueRange();
for (String target : tables) {
Integer shardValue = Integer.parseInt(target.substring(target.lastIndexOf("_") + 1, target.lastIndexOf("_") + 5));
if (valueRange.hasLowerBound()) {
String lowerStr = valueRange.lowerEndpoint().toString();
Integer start = Integer.parseInt(lowerStr.substring(0, 4));
if (start - shardValue > 0) {
continue;
}
}
if (valueRange.hasUpperBound()) {
String upperStr = valueRange.upperEndpoint().toString();
Integer end = Integer.parseInt(upperStr.substring(0, 4));
if (end - shardValue < 0) {
continue;
}
}
availables.add(target);
}
return availables;
}
}
其中init方法通过另一个类实例化完成后调用,难点在于如何拿到该实例化的LogShardingAlgorithm
import cn.hutool.core.util.ReflectUtil;import com.google.common.base.Optional;
import com.onegene.platform.system.log.LogShardingAlgorithm;
import org.apache.shardingsphere.core.rule.ShardingRule;
import org.apache.shardingsphere.core.rule.TableRule;
import org.apache.shardingsphere.core.strategy.route.ShardingStrategy;
import org.apache.shardingsphere.shardingjdbc.jdbc.core.ShardingContext;
import org.apache.shardingsphere.shardingjdbc.jdbc.core.datasource.ShardingDataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.sql.DataSource;
/**
* @author: laoliangliang
* @description:
* @create: 2020/1/18 8:29
**/
@Component
public class StartupConfig {
@Autowired
private DataSource dataSource;
@PostConstruct
public void init() {
this.loadLogInit();
}
private void loadLogInit() {
if (dataSource instanceof ShardingDataSource) {
ShardingDataSource sds = (ShardingDataSource) dataSource;
ShardingContext shardingContext = sds.getShardingContext();
ShardingRule shardingRule = shardingContext.getShardingRule();
Optional<TableRule> systemLog = shardingRule.findTableRule("system_log");
TableRule tableRule = systemLog.orNull();
if (tableRule != null) {
ShardingStrategy tableShardingStrategy = tableRule.getTableShardingStrategy();
LogShardingAlgorithm preciseShardingAlgorithm = (LogShardingAlgorithm) ReflectUtil.getFieldValue(tableShardingStrategy, "preciseShardingAlgorithm");
LogShardingAlgorithm rangeShardingAlgorithm = (LogShardingAlgorithm) ReflectUtil.getFieldValue(tableShardingStrategy, "rangeShardingAlgorithm");
preciseShardingAlgorithm.init();
rangeShardingAlgorithm.init();
}
}
}
}
1.3. 总结
通过查看源码可以知道,它最后把LogShardingAlgorithm实例化的对象放入了ShardingDataSource,那我们就要从里面把它取出来,若它正常没提供get方法,那我们就用反射硬把它取出来
通过上述代码可以看出,范围分片和精确分片需要实例化两个类,我想是否可以合到一个类,网上也找了一下,发现有的版本使用ComplexKeysShardingAlgorithm算法是可以同时实现范围和精确分片查询的,但经过我实际测试,现在的4.0.0版本不行,原因在于以下代码,此为复杂分片源码
public final class ComplexShardingStrategy implements ShardingStrategy { @Getter
private final Collection<String> shardingColumns;
private final ComplexKeysShardingAlgorithm shardingAlgorithm;
public ComplexShardingStrategy(final ComplexShardingStrategyConfiguration complexShardingStrategyConfig) {
Preconditions.checkNotNull(complexShardingStrategyConfig.getShardingColumns(), "Sharding columns cannot be null.");
Preconditions.checkNotNull(complexShardingStrategyConfig.getShardingAlgorithm(), "Sharding algorithm cannot be null.");
shardingColumns = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
shardingColumns.addAll(Splitter.on(",").trimResults().splitToList(complexShardingStrategyConfig.getShardingColumns()));
shardingAlgorithm = complexShardingStrategyConfig.getShardingAlgorithm();
}
@SuppressWarnings("unchecked")
@Override
public Collection<String> doSharding(final Collection<String> availableTargetNames, final Collection<RouteValue> shardingValues) {
Map<String, Collection<Comparable<?>>> columnShardingValues = new HashMap<>(shardingValues.size(), 1);
String logicTableName = "";
for (RouteValue each : shardingValues) {
// 重点这里他把each的值强行转化成了ListRouteValue而范围查询对应的为BetweenRouteValue,所以在源码级别就被卡死了,除非重写策略,否则这个已经不能像以前那样用了
columnShardingValues.put(each.getColumnName(), ((ListRouteValue) each).getValues());
logicTableName = each.getTableName();
}
Collection<String> shardingResult = shardingAlgorithm.doSharding(availableTargetNames, new ComplexKeysShardingValue(logicTableName, columnShardingValues));
Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
result.addAll(shardingResult);
return result;
}
}
欢迎关注公众号,回复“教学视频”一起学习进步
以上是 shardingsphere4.0.0RC1版本按年分表(后续优化) 的全部内容, 来源链接: utcz.com/z/512839.html