Rabbitmq消息100%投递的解决方案

作者:热心市民小陈
https://blog.csdn.net/weixin_42849915/article/details/87828163
一、前言
现在大多都使用 MQ 来做系统的异构,来做系统的解耦,系统的的模块相当于寄信者与收信者,MQ 则扮演者邮局的角色。作为一个中转的角色,就需要确保消息的100%投递。今天我们就来研究一下如何确保消息的100%的投递。
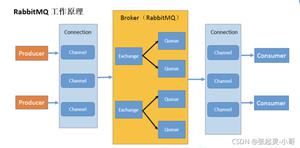
二、先谈谈rabbitmq的特性
rabbitmq 所做的确保是:只要你把消息投递到 Broker 中,那么我就确保这个消息会送达到消费者的手中。当然这是有前提条件的,比如:
- 你需要进行手动应答,
- 最起码 Broker 不挂,且消息进行了持久化等。
结合 rabbitmq 的特性来做分析,针对于投递端,我们只需要确保把消息发送到Broker 中即可,那么如何保证可靠性呢,分下列步骤:
- 消息成功的发送了出去
- 保证 Broker 成功的收到了消息
- 生产者收到了 Broker 的确认应答
- 消息补偿机制,当前三步都跪了,做一个补偿重发机制
- 最后一道屏障,如果第四步重试次数过多,那么说明系统出现问题,我们就需要人工干预了
只要做到上面五步,基本上我们就可以保证,消息投递100%的投递出去。
三、生产者的投递的可靠性保障
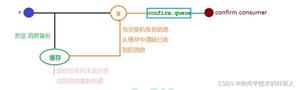
3.1 先上一个示意图
3.2 就上述的图示,我们逐步解析
- step1:数据落库,这一步是必须的
- step2:把消息落库,且初始化其状态为 0 (发送中)
- step3:把消息投递到 Broker 中
- step4:Broker 发送成功应答
- step5:生产者拿到成功应答,修改消息状态为1:(发送成功)
上面讲述的都是正常的流程,下面讲讲如果出现不正常的解决机制:
- step6:定时检查消息的状态是否为1
- step7:如果 step6 的消息的状态仍然为 0 ,则进入重发,重复上述 step1 - step5
- step8:如果消息重发达到一定的的次数,则人工接入处理,因为此时说明可能是消息
上述的方案看似完美无缺,但是细想,如果在 step4 中 Broker 发送应答的过程中,网络出现问题这个消息没有到达生产者会导致整个流程进入补偿的流程当中,此时 Broker 中就有两条消息,也就是发成了重复的投递的问题,所以接下来我们要在消费端来处理这个问题。
四、消费端的幂等:
4.1 导致需要解决幂等的原因
- Broker 发送应答消息的时候,消息未到达生产者
- 消费者在发送应答的时候,消费者挂掉了
4.2 就上述我们的机制的解决
因为上述我的消息都有唯一的标识,所以我们只需要查找对应的消息对应的标识来判断其状态即可
4.3 构建唯一标识的方案
首先说明不同的方案使用不同的应用场景,不要一上来你就说十几万的并发怎么样的,这个慢慢来,一步步往这里走
4.3.1 利用数据库自增id
优点:
1):不能再简单了,在并发不大的情况可以接受
2):对分页和排序是有帮助的
缺点:
1):分库分表和读写分离多住从的情况下不适用
2):性能达不到要求时,不利于扩展
3):不同数据库的语法实现不一样
4.3.2 利用 redis 来生成id
优点:
1):redis 单线程可以生成全局唯一ID
2):可以使用 redis 集群获取更高的吞吐量
缺点:
1):引入新的组件,增加系统复杂度
2):需要注意处理并发问题
4.3.3 利用 twitter 开源的 snowflake
snowflake 是 twitter 开源的一个分布式的 ID 的生成算法,结果是一个 long 的ID,使用 41bit 作为毫秒数,10bit 作为机器 ID(5个 bit 是数据中心,5个 bit 是机器 ID) 12 bit 作为毫秒内的流水号(每个节点每毫秒可以产生 2^12 = 4096 个 ID)最后是一个符号位,
优点:
1):不依赖数据库和其他的中间件,且性能尚可
缺点:
1):是有依赖时间的,如果各个机器的失重不同步就会出现不适全局递增的情况
以上是 Rabbitmq消息100%投递的解决方案 的全部内容, 来源链接: utcz.com/z/512430.html