Kafka及周边深度了解

本文属于原创,转载注明出处,欢迎关注微信小程序小白AI博客 微信公众号小白AI或者网站 https://xiaobaiai.net 或者我的CSDN http://blog.csdn.net/freeape
[TOC]
0 前言
文章有点长,但是写的都挺直白的,慢慢看下来还是比较容易看懂,从Kafka的大体简介到Kafka的周边产品比较,再到Kafka与Zookeeper的关系,进一步理解Kafka的特性,包括Kafka的分区和副本以及消费组的特点及应用场景简介。
1 简介
Apache Kafka" title="Apache Kafka">Apache Kafka 是一个分布式流处理平台,注意是平台:
- 发布 & 订阅,类似消息系统,并发能力强,通过集群可以实现数据总线作用,轻轻松松实现流式记录数据分布式读写
- 以高容错的方式存储海量流式数据
- 可以在流式记录数据产生时就进行处理
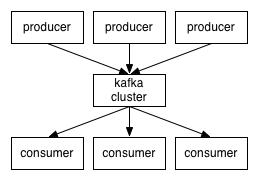
从上面的一个Kafka小型应用架构图可以了解Kafka周边及它的实际能扮演的角色,图中Kafka集群连接了六个数据输入输出部分,分别是Kafka Producer、Kafka Connect Source 、Kafka Streams/KSQL、Kafka Consumer、Kafka Connect Sink。而这些数据的输入输出都可以通过Kafka提供的四个核心API组去解决(除Kafka AdminClient API外):
- Kafka Producer API 允许一个应用程序
发布一串流式的数据到一个或者多个Kafka主题(Topic) - Kafka Consumer API 允许一个应用程序
订阅一个或多个主题(Topic) ,并且对接收到的流式数据进行处理 - Kafka Streams API 允许一个应用程序作为一个
流处理器,消费一个或者多个主题(Topic)产生的输入流,然后生产一个输出流到一个或多个主题(Topic)中去,在输入输出流中进行有效的转换 - Kafka Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka Topics连接到已存在的应用程序或者数据库系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
我们对Kafka的发布 & 订阅功能的作用比较清楚,而图中的KSQL和Kafka Streams是怎么个回事呢?
首先我们需要清楚什么是流处理?流处理可以认为是消息的实时处理,比如在一个时间段内,源源不断地有数据信息进来,而每时每刻都能够对这些数据有一个最后的结果处理,那么这就是流处理,而如果是每隔一个小时或者更久处理一次,那叫大数据分析或者批处理。它的特点更多是实时性的分析,在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算,同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。类似的比较有:Hadoop、Storm以及Spark Streaming及Flink是常用的分布式计算组件,其中Hadoop是对非实时数据做批量处理的组件;Storm、Spark Streaming和Flink是针对实时数据做流式处理的组件,而Kafka Streams是后起之秀。
关于KSQL呢?
- KSQL 是
Apache Kafka的数据流 SQL 引擎,它使用 SQL 语句替代编写大量代码去实现流处理任务,而Kafka Streams是Kafka中专门处理流数据的 - KSQL 基于 Kafka 的
Stream API构建,它支持过滤(filter)、转换(map)、聚合(aggregations)、连接(join)、加窗操作和Sessionization(即捕获单一会话期间的所有的流事件)等流处理操作,简化了直接使用Stream API编写 Java 或者 Scala 代码,只需使用简单的 SQL 语句就可以开始处理流处理 - KSQL 语句操作实现上都是分布式的、容错的、弹性的、可扩展的和实时的
- KSQL 的用例涉及实现实时报表和仪表盘、基础设施和物联网设备监控、异常检测和欺骗行为报警等
2 相关概念简介
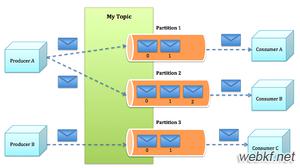
Broker:Kafka集群包含一个或多个服务器,这种服务器被称为brokerTopic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为TopicPartition:Parition是物理上的概念,每个Topic包含一个或多个PartitionReplication:副本,一个partition可以设置一个或者多个副本,副本主要保证系统能够持续不丢失地对外提供服务。在创建topic的时候可以设置partition的replication数Segment:段文件,kafka中最小数据存储单位,kafka可以存储多个topic,各个topic之间隔离没有影响,一个topic包含一个或者多个partition,每个partition在物理结构上是一个文件夹,文件夹名称以topic名称加partition索引的方式命名,一个partition包含多个segment,每个segment以message在partition中的起始偏移量命名以log结尾的文件,producer向topic中发布消息会被顺序写入对应的segment文件中。kafka为了提高写入和查询速度,在partition文件夹下每一个segment log文件都有一个同名的索引文件,索引文件以index结尾。Offset:消息在分区中偏移量,用来在分区中唯一地标识这个消息。Producer:消息生产者,负责发布消息到Kafka brokerConsumer:消息消费者,向Kafka broker读取消息的客户端Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
3 Kafka与ActiveMQ、ZeroMQ、RabbitMQ、RocketMQ、Redis
这个主要是针对消息中间件的选型评估,这里我们讲述一些概念。其他更详细的这里有篇文章讲了: https://juejin.im/post/5b32044ef265da59654c3027 。
3.1 消息队列、点对点和PUB/SUB
在开始之前,我们也需要稍微了解下JMS(Java Messaging System),是一个Java平台中关于面向消息中间件(MOM)的API。JMS支持两种消息模式,一个就是P2P模式,一个就是发布订阅模式。后面会说到哪些消息件支持JMS。
消息队列有两种消息模型:点对点(Point to Point,PTP)和发布/订阅(PUB/SUB)模式。
消息队列点对点,顾名思义,是一个队列,信息只能一对一,一个消息被一个消费者使用完了,那么就不会存在队列中了,就像邮差给别人投递邮件,不可能这封信还有副本,而且还能保证这封信安全送到指定的人手里(这是框架赋予的能力)。
而PUB/SUB消息订阅发布就不一样了,它的特征就是支持多对一,一对一,一对多,就像期刊报社一样,出版的期刊或者报纸,需要可以传递到不同人手里,而且还可以拿到以前日期的期刊或者报纸(这是框架赋予的能力)。
RabbitMQ是消息代理,持多种消息传递协议,如AMQP,MQTT3.1,XMPP, SMTP, STOMP,HTTP, WebSockets协议,由内在高并发的Erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。它既支持消息队列点对点,也支持PUB/SUB。RabbitMQ对JMS所有特性并不完全支持(https://www.rabbitmq.com/jms-client.html#limitations)Redis以内存数据库而闻名。但是,也可以将其用作消息队列点对点和PUB/SUB管理工具,不过因为内存缓冲区的效率,如果消费者失去了与队列的连接,那么很有可能在连接丢失时丢失消息。另外,在实现消息队列点对点功能上,至少要创建3个队列:主队列、工作队列、被拒绝队列,实现有点复杂。Apache RocketMQ作为阿里开源的一款高性能、高吞吐量的分布式消息中间件,PUB/SUB就是基本功能了,支持消息优先级、消息有序保证、消息过滤,保证每个消息至少投递一次。RocketMQ的集群消费功能大等于PTP模型。因为RocketMQ单个Consumer Group内的消费者类似于PTP,单个Consumer Group里面的消费者均摊消息,等于实现点对点功能,接收者单位是Group。Apache ActiveMQ支持点对点和PUB/SUB,支持多种跨语言客户端和协议,具有易于使用的企业集成模式和许多高级功能,同时完全支持JMS 1.1和j2ee1.4ZeroMQ是用C实现的,性能高、轻量级自然是它的特点。ZeroMQ 并非严格意义上的at least once或者at most once,以其 Pub/Sub 模式来说,ZeroMQ 构建了消息确认和重传机制,却未对消息进行持久化,那么内存耗尽或者进程崩溃都会造成消息丢失,而重传则可能会造成消息被发送 1 到 n 次。当然,在企业级WEB服务中,尤其是微服务中我们对ZeroMQ的选择是偏少的。Kafka更多的是作为发布/订阅系统,结合Kafka Stream,也是一个流处理系统
3.2 关于持久化
ZeroMQ支持内存、磁盘,不支持数据库持久化Kafka支持内存、磁盘(主),支持数据库持久化,支持大量数据堆积RabbitMQ支持内存、磁盘,支持数据堆积,但是数据堆积影响生产效率ActiveMQ支持内存、磁盘,自持数据库持久化RocketMQ的所有消息都是持久化的,先写入系统 pagecache(页高速缓冲存储器),然后刷盘,可以保证内存与磁盘都有一份数据,访问时,直接从内存读取
3.3 关于吞吐量
RabbitMQ在吞吐量方面稍逊于Kafka,他们的出发点不一样,RabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。Kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高ZeroMQ也具有很高的吞吐量RocketMQ相比RabbitMQ的吞吐量要大,但是没有Kafka的大ActiveMQ相对RabbitMQ而言要弱
3.4 关于集群
Kafka:天然的"Leader-Slave"无状态集群,每台服务器既是Master也是SlaveZeroMQ:去中心化,不支持集群RabbitMQ:支持简单集群RocketMQ:支持集群,常用多对"Master-Slave" 模式ActiveMQ:支持简单集群模式,比如"主-备",对高级集群模式支持不好。
3.5 关于负载均衡
Kafka:支持负载均衡,结合内置Zookeeper,有效的实现Kafka集群的Load BalancerZeroMQ:去中心化,不支持负载均衡,本身只是一个多线程网络库RocketMQ:支持负载均衡RabbitMQ:对负载均衡的支持不好ActiveMQ:支持负载均衡,可以基于Zookeeper实现负载均衡
3.6 关于单机队列数
单机队列数越大,单机可以创建更多主题,因为每个主题都是由一批队列组成,消费者的集群规模和队列数成正比,队列越多,消费类集群可以越大。
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长。Kafka分区数无法过多的问题
- RocketMQ单机支持最高5万个队列,负载不会发生明显变化
4 Kafka Streams与Storm、Spark Streaming、Flink
4.1 流处理框架特点和处理方式
上面我们说过了流处理就是对数据集进行连续不断的处理,聚合,分析的过程,它的延迟要求尽可能的低(毫秒级或秒级),从流处理的几个重要方面来讲述,分布式流处理框架需要具有如下特点:
消息传输正确性保证,保证区分有:- 消息At Most Once,即消息可以丢失或者传递一次
- 消息At Least Once,即消息至少一次,存在重复传递的情况
- 消息Exactly Once,即消息不会丢失也不会重复传递
高容错性:在发生诸如节点故障、网络故障等故障时,框架应该能够恢复,并且应该从它离开的地方重新开始处理。这是通过不时地检查流到某个持久性存储的状态来实现的。状态管理:绝大部分分布式系统都需要保持状态处理的逻辑。流处理平台应该提供存储,访问和更新状态信息的能力高性能:这包括低延迟(记录处理的时间)、高吞吐量(throughput,记录处理/秒)和可伸缩性。延迟应尽可能短,吞吐量应尽可能多,不过这很难同时兼顾到这两者,需要做一个平衡高级特性:Event Time Processing(事件时间处理)、水印、支持窗口,如果流处理需求很复杂,则需要这些特性。例如,基于在源代码处生成记录的时间来处理记录(事件时间处理)成熟度:如果框架已经被大公司证明并在大规模上进行了测试,这就很好。更有可能在论坛或者其他地方获得良好的社区支持和帮助
流处理的方式有两种:
- Native Streaming
- 每一个传入的记录一到达就被处理,而不必等待其他记录。有一些持续运行的进程(我们称之为operators/tasks/bolts,命名取决于框架)会永远运行,并且每个记录都会经过这些进程来进行处理,示例:Storm、Flink、Kafka Streams。
- Micro-batching
- 快速批处理,这意味着每隔几秒钟传入的记录都会被批处理在一起,然后以几秒的延迟在一个小批中处理,例如: Spark Streaming
这两种方法都有一些优点和缺点。当每个记录一到达就被处理时,处理结果就感觉很自然,允许框架实现尽可能最小的延迟。但这也意味着在不影响吞吐量的情况下很难实现容错,因为对于每个记录,我们需要在处理后跟踪和检查点。此外,状态管理也很容易,因为有长时间运行的进程可以轻松地维护所需的状态;而小批处理方式,则完全相反,容错是附带就有了,因为它本质上是一个批处理,吞吐量也很高,因为处理和检查点将一次性完成记录组。但它会以一定的延迟为代价,让人感觉不像是自然的流处理。同时,高效的状态管理也将是一个挑战。
4.2 主流流处理框架比对
流处理框架 特点 缺点
Strom是流处理界的hadoop。它是最古老的开源流处理框架,也是最成熟、最可靠的流处理框架之一
非常低的延迟,真正的流处理,成熟和高吞吐量;非常适合不是很复杂流式处理场景;
消息至少一次保证机制;没有高级功能,如事件时间处理、聚合、窗口、会话、水印;
Spark Streaming
支持Lambda架构,免费提供Spark;高吞吐量,适用于许多不需要子延迟的场景;简单易用的高级api;社区支持好;此外,结构化流媒体更为抽象,在2.3.0版本中可以选择在微批处理和连续流媒体模式之间切换;保证消息恰好传递一次;
不是真正的流媒体,不适合低延迟要求;参数太多,很难调参;在许多高级功能上落后于Flink;
Flink
支持Lambda架构;开源流媒体领域的创新领导者;第一个真正的流式处理框架,具有所有高级功能,如事件时间处理、水印等;低延迟,高吞吐量,可根据需要配置;自动调整,没有太多参数需要调整;保证消息恰好传递一次;在像Uber、阿里巴巴这样的规模大公司接受。
进入流处理界晚,还没被广泛接受;社区支持相对较少,不过在蓬勃发展;
Kafka Streams
非常轻量级的库,适用于微服务和物联网应用;不需要专用群集;继承了卡夫卡所有的优良品质;支持流连接,内部使用rocksDb来维护状态。保证消息恰好传递一次;
与卡夫卡紧密结合,否则无法使用;刚刚起步,还未有大公司选择使用;不合适重量级的流处理;
总的来说,Flink作为专门流处理是一个很好的选择,但是对于轻量级并且和Kafka一起使用时,Kafka Streaming是个不错的选择。
5 Zookeeper & Kafka?
Zookeeper在Kafka集群中主要用于协调管理,主要作用:
- Kafka将元数据信息保存在Zookeeper中
- 通过Zookeeper的协调管理来实现整个kafka集群的动态扩展
- 实现整个集群的负载均衡
- Producer通过 Zookeeper 感知 partition 的Leader
- 保存Consumer消费的状态信息。
- 通过 ZK 管理集群配置,选举 Kafka Leader,以及在 Consumer Group 发生变化时进行 Rebalance
Zookeeper是由java编写的,所以需要先安装JDK。
5.1 Zookeeper是必须要有的吗?
是的,在Kafka中,尽管你只想使用一个代理、一个主题和一个分区,其中有一个生产者和多个消费者,不希望使用Zookeeper,浪费开销,但是这情况也需要Zookeeper,协调分布式系统中的任务、状态管理、配置等,而且使用单节点的场景显然没有利用到Kafka的优点。
另外,Apacke Kafka维护团队开始讨论去除Zookeeper了(2019年11月6日),目前,Kafka使用ZooKeeper来存储分区和代理的元数据,并选择一个Broker作为Kafka控制器,而希望通过删除对ZooKeeper的依赖,将使Kafka能够以一种更具伸缩性和健壮性的方式管理元数据,启用对更多分区的支持,它还将简化Kafka的部署和配置,因为ZooKeeper是一个单独的系统,具有自己的配置文件语法,管理工具和部署模式。另外Kafka和ZooKeeper配置是分开的,所以很容易出错。例如,管理员可能在Kafka上设置了SASL,并且错误地认为他们已经保护了通过网络传输的所有数据。实际上,这样做还必须在单独的外部ZooKeeper系统中配置安全性。统一两个系统将提供统一的安全配置模型。将来Kafka可能希望支持单节点Kafka模式,这对于想要快速测试Kafka而无需启动多个守护程序的人很有用,删除掉ZooKeeper的依赖关系使之成为可能。
5.2 Zookeeper在Kafka中是自带的,可以使用自定义安装的ZK吗?
这个当然是可以的,你可以不启动Kafka自带的ZK。
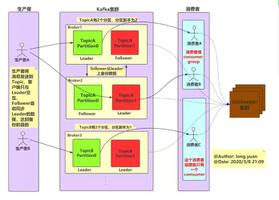
6 理解Kafka数据模型: Topics、Partitions及Replication
Kafka的分区机制实现了Topic的水平扩展和顺序性保证。这一节我们深度了解下是怎么回事?
Topic在逻辑上可以被认为是一个队列。每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个队列里。为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件,比如我们创建了一个主题叫xiaobiao,然后Kafka有三个Brokers,结合《Kafka,ZK集群开发或部署环境搭建及实验》这一篇文章中的实验环节,我们创建主题的时候需要指定:
# 利用Kafka提供的命令行脚本,创建两分区两副本的主题xiaobiao./bin/kafka-topics.sh --create --zookeeper localhost:2181,localhost:2182,localhost:2183 --replication-factor 2 --partitions 2 --topic xiaobiao
两分区,两副本,如何理解呢?我们指定了三个服务,我们将xiaobiao主题分为两个子部分,可以认为是两个子队列,对应的在物理上,我们可以在log.dir参数设定的目录下看到两个文件夹xiaobiao-0和xiaobiao-1,不过根据Kafka的分区策略,对于多个Kafka Brokers,分区(多个文件夹)一般会分散在不同的Broker上的log.dir设定的目录下,当只有一个Broker时,所有的分区就只分配到该Broker上,消息会通过负载均衡发布到不同的分区上,消费者会监测偏移量来获取哪个分区有新数据,从而从该分区上拉取消息数据。这是分区的表现。不过分区数越多,在一定程度上会提升消息处理的吞吐量,因为Kafka是基于文件进行读写,因此也需要打开更多的文件句柄,也会增加一定的性能开销,但是Kafka社区已经在制定解决方案,实现更多的分区,而性能不会受太多影响。
如果分区过多,那么日志分段也会很多,写的时候由于是批量写,其实就会变成随机写了,随机 I/O 这个时候对性能影响很大。所以一般来说 Kafka 不能有太多的 Partition。
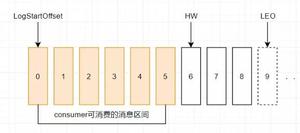
那副本呢?顾名思义,即主题的副本个数,即我们上面有两个主题分区,即物理上两个文件夹,那么指定副本为2后,则会复制一份,则会有两个xiaobai-0两个xiaobai-1,副本位于集群中不同的broker上,也就是说副本的数量不能超过broker的数量,否则创建主题时就会失败。那么副本有什么用呢?当Kafka某个代理(Broker)出现故障且无法为请求(Consumer)提供服务时,为了达到可用性的唯一目的而设置有多个数据副本,这样就不担心集群中某个Broker挂掉了,这里也进一步可以知道,达到这个作用,那么一个主题的分区副本是需要在不同的Broker上的,而且对应副本分区是保持数据同步的。不可避免地,副本越多,那么对Kafka的吞吐量是会造成影响的。下图就是Replication Factor等于2时数据同步示意图:
分区Leader: 对于每个分区,都有一个副本被指定为Leader。Leader负责发送和接收该分区的数据,所有其他副本都称为分区的同步副本(或跟随者)。
In sync replicas是分区的所有副本的子集,该分区与主分区具有相同的消息。
比如当Broker2 挂掉后,由于broker 2是分区1的负责人(Leader),因此现在无法访问分区1。发生这个情况的时候Kafka会自动选择一个同步副本(在上图中只有一个副本)并使它成为领导者(Leader)。现在,当broker 2重新上线时,broker 2中分区1可以再次尝试成为Leader。
当然,上面所说副本和分区没有具体深入到内部机制是怎么实现的,怎么保证的,这里就先不展开了。
7 Kafka的Consumer Group
Consumer Group:每一个消费者实例都属于一个消费Group,每一条消息只会被同一个消费Group里的一个消费者实例消费(不同消费Group可以同时消费同一条消息)。不同于一般的队列,Kafka实现了消息被消费完后也不会将消息删除的功能,即我们能够借助Kafka实现离线处理和实时处理,跟Hadoop和Flink这两者特性可以对应起来,因此可以分配两个不同消费组分别将数据送入不同处理任务中。
8 总结
这一篇文章让我们对Kafka有了个基本的认识,可以做消息订阅/发布系统,可以做实时流处理,对Kafka的分区和副本有了一定的认识,对Kafka的消费组的特性也有了个基本了解,接下来就进入实践,实践过后,我们再深入探讨Kafka的内部原理和实现机制。
9 参考资料
- http://kafka.apache.org/intro.html
- http://kafka.apachecn.org/intro.html
- https://stackoverflow.com/questions/23751708/is-zookeeper-a-must-for-kafka
- https://stackoverflow.com/questions/38024514/understanding-kafka-topics-and-partitions
- https://www.bigendiandata.com/2016-11-15-Data-Types-Compared/
- https://stackoverflow.com/questions/44014975/kafka-consumer-api-vs-streams-api
- https://kafka.apache.org/documentation/streams/
- https://medium.com/@stephane.maarek/the-kafka-api-battle-producer-vs-consumer-vs-kafka-connect-vs-kafka-streams-vs-ksql-ef584274c1e
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum
- https://juejin.im/post/5b32044ef265da59654c3027
- https://www.infoq.cn/article/democratizing-stream-processing-apache-kafka-ksql
- https://cloud.tencent.com/developer/article/1031210
- http://www.54tianzhisheng.cn/2018/01/05/SpringBoot-Kafka/#
- http://www.54tianzhisheng.cn/2018/01/04/Kafka/
- https://www.infoq.cn/article/kafka-analysis-part-7
- https://juejin.im/post/5b32044ef265da59654c3027
- http://kafka.apachecn.org/documentation.html
- https://www.linkedin.com/pulse/message-que-pub-sub-rabbitmq-apache-kafka-pubnub-krishnakantha
- https://www.rabbitmq.com/
- https://medium.com/@anvannguyen/redis-message-queue-rpoplpush-vs-pub-sub-e8a19a3c071b
- http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/
- https://activemq.apache.org/components/artemis/documentation/2.0.0/address-model.html
- https://www.journaldev.com/9731/jms-tutorial
- https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b
- https://medium.com/@_amanarora/replication-in-kafka-58b39e91b64e
- http://www.jasongj.com/2015/01/02/Kafka%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90/
- https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Client-side+Assignment+Proposal
以上是 Kafka及周边深度了解 的全部内容, 来源链接: utcz.com/z/511618.html