mysql存储过程循环分表

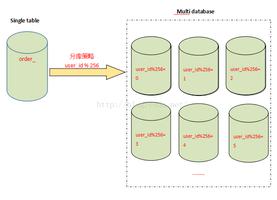
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
mysql> DELIMITER $$
mysql> CREATE procedure wx_user_fans()
-> BEGIN
-> DECLARE `@i` int(11);
-> DECLARE `@sqlstr` varchar(2560);
-> SET `@i`=0;
-> WHILE `@i` < 10 DO
-> SET @sqlstr = CONCAT(
-> "CREATE TABLE wx_user_fans_",`@i`,
-> "( `id` int(11) NOT NULL AUTO_INCREMENT, `userid` int(11) DEFAULT '0', PRIMARY KEY (`id`)) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 "
-> );
-> prepare stmt from @sqlstr;
-> execute stmt;
->
-> SET `@i` = `@i` + 1;
-> END WHILE;
-> end $$
Query OK, 0 rows affected (0.00 sec)
mysql> DELIMITER ;
mysql> call wx_user_fans();
Query OK, 0 rows affected (0.13 sec)
mysql> drop procedure wx_user_fans;
Query OK, 0 rows affected (0.00 sec)
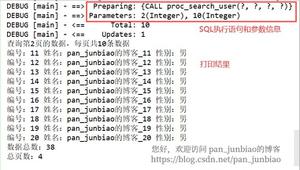
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| admin |
| files |
| mytest |
| tb_orderlist |
| wx_user_fans_0 |
| wx_user_fans_1 |
| wx_user_fans_2 |
| wx_user_fans_3 |
| wx_user_fans_4 |
| wx_user_fans_5 |
| wx_user_fans_6 |
| wx_user_fans_7 |
| wx_user_fans_8 |
| wx_user_fans_9 |
| zcctest |
+----------------+
15 rows in set (0.00 sec)
以上是 mysql存储过程循环分表 的全部内容, 来源链接: utcz.com/z/509399.html