二进制部署K8s集群第25节之k8s技术点整理

容器几个知识点
容器作用
• 可以把应用程序代码及运行依赖环境打包成镜像,作为交付介质,在各环境部署
• 可以将镜像(image)启动成为容器(container),并且提供多容器的生命周期进行管理(启、停、删)
• container容器之间相互隔离,且每个容器可以设置资源限额
• 提供轻量级虚拟化功能,容器就是在宿主机中的一个个的虚拟的空间,彼此相互隔离,完全独立
• 三大核心要素 镜像(Image)、容器(Container)、仓库(Registry)
• 容器1号进程觉定容器存活
Docker指令:
• COPY|ADD 添加本地文件到镜像中,不同的是,如果是压缩包,ADD会解压,是链接,ADD会下载
cp 可以从宿主机拷贝文件到容器,也可以从容器拷贝镜像到宿主机
• CMD 构建容器后调用,也就是在容器启动时才进行调用,CMD不同于RUN,CMD用于指定在容器启动时所
要执行的命令,而RUN用于指定镜像构建时所要执行的命令。启同容器后执行的命令会覆盖CMD命令
• ENTRYPOINT 设置容器初始化命令,使其可执行化 ENTRYPOINT与CMD非常类似,不同的是通过docker run执行的命令不会覆盖ENTRYPOINT,而docker run命令中指定的任何参数,都会被当做参数再次传递给ENTRYPOINT。Dockerfile中只允许有一个ENTRYPOINT命令,多指定时会覆盖前面的设置,而只执行最后的ENTRYPOINT指令
• ENV 设置环境变量
- UnionFS 联合文件系统
• Linux namespace和cgroup分别解决了容器的资源隔离与资源限制
• 在最新的 Docker 中,overlay2 取代了 aufs 成为了推荐的存储驱动
• 镜像就是由这些层一层一层堆叠起来的,镜像中的这些层都是只读的,当我们运行容器的时候,就可以在这些基
础层至上添加新的可写层,也就是我们通常说的容器层,对于运行中的容器所做的所有更改(比如写入新文件、
修改现有文件、删除文件)都将写入这个容器层。
• 对容器层的操作,主要利用了写时复制(CoW)技术。CoW就是copy-on-write,表示只在需要写时才去复制,
这个是针对已有文件的修改场景。 CoW技术可以让所有的容器共享image的文件系统,所有数据都从image中读
取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。所以无论有多
少个容器共享同一个image,所做的写操作都是对从image中复制到自己的文件系统中的复本上进行,并不会修
改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个复本,每个容器修改的都
是自己的复本,相互隔离,相互不影响。使用CoW可以有效的提高磁盘的利用率。 - Docker网络
• Host模式,容器内部不会创建网络空间,共享宿主机的网络空间。容器启动后,会默认监听3306端口,由于网络模式是host,因为可以直接通过宿主机的3306端口进行访问服务,效果等同于在宿主机中直接启动mysqld的进程。
• Conatiner模式 这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
• none模式,使用--net=none指定 网络模式为空,即仅保留网络命名空间,但是不做任何网络相关的配置(网卡、IP、路由等)
• bridge模式 使用--net=bridge指定,默认设置 bridge本意是桥的意思,其实就是网桥模式。我们可以把网桥看成一个二层的交换机设备,Docker 创建一个容器的时候,创建一对虚拟接口/网卡,也就是veth pair;本地主机一端桥接 到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 veth9953b75;容器一端放到新启动的容器内部,并修改名字作为 eth0,这个网卡/接口只在容器的命名空间可见;从网桥可用地址段中(也就是与该bridge对应的network)获取一个空闲地址分配给容器的 eth0
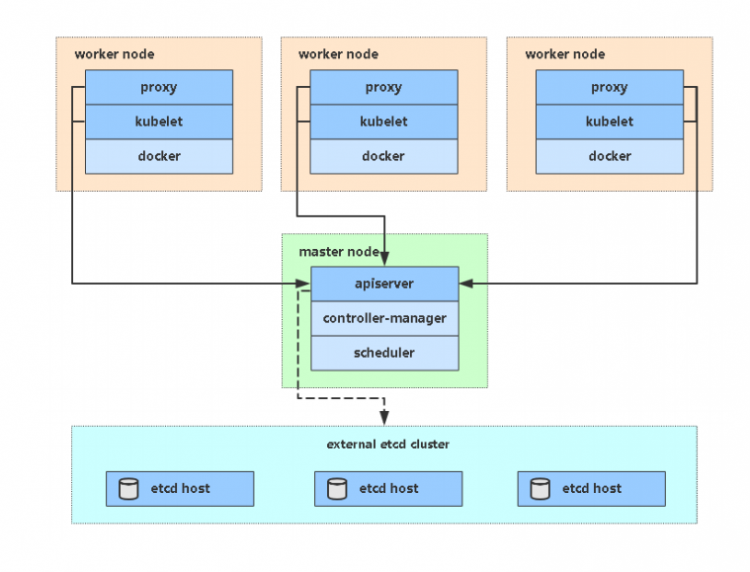
k8s核心组件
ETCD:分布式高性能键值数据库,存储整个集群的所有元数据
ApiServer: API服务器,集群资源访问控制入口,提供restAPI及安全访问控制
Scheduler:调度器,负责把业务容器调度到最合适的Node节点
Controller Manager:控制器管理,确保集群资源按照期望的方式运行
kubelet:运行在每个节点上的主要的“节点代理”,脏活累活
• pod生命周期管理,创建销毁容器
• 容器监控,监控所在节点的资源使用情况,并定时向 master报告,资源使用数据都是通过 cAdvisor 获取的
kube-proxy:维护节点中的iptables或者ipvs规则
K8S工作流程
1、用户准备一个资源文件(记录了业务应用的名称、镜像地址等信息),通过调用APIServer执行创建
Pod
2、APIServer收到用户的Pod创建请求,将Pod信息写入到etcd中
3、调度器通过list-watch的方式,发现有新的pod数据,但是这个pod还没有绑定到某一个节点中
4、调度器通过调度算法,计算出最适合该pod运行的节点,并调用APIServer,把信息更新到etcd中
5、kubelet同样通过list-watch方式,发现有新的pod调度到本机的节点了,因此调用容器运行时,去
根据pod的描述信息,拉取镜像,启动容器,同时生成事件信息
6、同时,把容器的信息、事件及状态也通过APIServer写入到etcd中
架构设计的几点思考
1、系统各个组件分工明确(APIServer是所有请求入口,CM是控制中枢,Scheduler主管调度,而
Kubelet负责运行),配合流畅,整个运行机制一气呵成。
2、除了配置管理和持久化组件ETCD,其他组件并不保存数据。意味除ETCD外其他组件都是无状态
的。因此从架构设计上对kubernetes系统高可用部署提供了支撑。
3、同时因为组件无状态,组件的升级,重启,故障等并不影响集群最终状态,只要组件恢复后就可以
从中断处继续运行。
4、各个组件和kube-apiserver之间的数据推送都是通过list-watch机制来实现。
POD
1、pod是什么
pod是集群可以调度的最小单元
一个pod可以包含一个或多个容器
2、健康检查
• 存活性探测
• 就绪性探测
三种类型:
exec:通过执行命令来检查服务是否正常,返回值为0则表示容器健康
httpGet方式:通过发送http请求检查服务是否正常,返回200-399状态码则表明容器健康
tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康
3、资源限制
• requests: 容器使用的最小资源需求,作用于schedule阶段,作为容器调度时资源分配的判断依赖
只有当前节点上可分配的资源量 >= request 时才允许将容器调度到该节点,request参数不限制容
器的最大可使用资源
• limits:容器能使用资源的最大值,设置为0表示对使用的资源不做限制, 可无限的使用,当pod 内存超过limit时,会被oom,当cpu超过limit时,不会被kill,但是会限制不超过limit值
4、调度策略
• cordon 标记节点为不调度
• nodeName 调度到某一台定义的节点名字服务器
• nodeSelector 调度到打了标签的节点服务器
• Taints and Tolerations 污点与容忍,只有能够容忍污点的容器才能被调用
• drain 维护模式,不允许调度并排关所有容器关闭kubelet
5、安全上下文
如:设置容器内进程root用户启动
7、pod数据持久化
• hostpath
• nfs
• ceph
• emptyDir
8、pod驱逐策略
Kube-controller-manager:周期性检查所有节点状态,当节点处于 NotReady 状态超过一段时间后,驱逐该节点上所有 pod。停掉kubelet
pod-eviction-timeout:NotReady 状态节点超过该时间后,执行驱逐,默认 5 min
Kubelet: 周期性检查本节点资源,当资源不足时,按照优先级驱逐部分 pod
• 节点可用内存
• 根盘可用存储空间
• 可用数量
• 镜像存储盘的可用空间
• 镜像存储盘的inodes可用数量
9、Pod控制器
Workload (工作负载),控制器又称工作负载是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试 进行重启,当根据重启策略无效,则会重新新建pod的资源。
• ReplicaSet: 代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能
• Deployment:工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,提供声明式配置
• DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如EFK服务
• Job:只要完成就立即退出,不需要重启或重建
• Cronjob:周期性任务控制,不需要持续后台运行
• StatefulSet:管理有状态应用
service
1、Kubernetes服务访问之Service
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP 。使用Service对象,通过selector进行标签选择,找到对应的Pod:
2、Service负载均衡之NodePort
cluster-ip为虚拟地址,只能在k8s集群内部进行访问,集群外部如果访问内部服务,实现方式之一为使用NodePort方式。NodePort会默认在 30000-32767 ,不指定的会随机使用其中一个。
3、服务发现
在k8s集群中,组件之间可以通过定义的Service名称实现通信。
4、Service与Pod如何关联:
service对象创建的同时,会创建同名的endpoints对象,若服务设置了readinessProbe, 当readinessProbe检测失败时,endpoints列表中会剔除掉对应的pod_ip,这样流量就不会分发到健康检测失败的Pod中
kube-proxy几种模式
运行在每个节点上,监听 API Server 中服务对象的变化,再通过创建流量路由规则来实现网络的转发
1、User space
让 Kube-Proxy 在用户空间监听一个端口,所有的 Service 都转发到这个端口,然后 Kube-Proxy 在内部应用层对其进行转发 , 所有报文都走一遍用户态,性能不高,k8s v1.2版本后废弃。
2、Iptables
当前默认模式,完全由 IPtables 来实现, 通过各个node节点上的iptables规则来实现service的负载均衡,但是随着service数量的增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降。
3、IPVS
与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。 k8s 1.8版本开始引入,1.11版本开始稳定,需要开启宿主机的ipvs模块。
Kubernetes服务访问之Ingress
对于Kubernetes的Service,无论是Cluster-Ip和NodePort均是四层的负载,集群内的服务如何实现七层的负载均衡,这就需要借助于Ingress,Ingress控制器的实现方式有很多,比如nginx, Contour, Haproxy, trafik, Istio
Ingress-nginx是7层的负载均衡器 ,负责统一管理外部对k8s cluster中Service的请求。主要包含:
• ingress-nginx-controller:根据用户编写的ingress规则(创建的ingress的yaml文件),动态的去更改nginx服务的配置文件,并且reload重载使其生效(是自动化的,通过lua脚本来实现);
• Ingress资源对象:将Nginx的配置抽象成一个Ingress对象
实现逻辑
1)ingress controller通过和kubernetes api交互,动态的去感知集群中ingress规则变化2)然后读取ingress规则(规则就是写明了哪个域名对应哪个service),按照自定义的规则,生成一段nginx配置3)再写到nginx-ingress-controller的pod里,这个Ingress controller的pod里运行着一个Nginx服务,控制器把生成的nginx配置写入/etc/nginx/nginx.conf文件中4)然后reload一下使配置生效。以此达到域名分别配置和动态更新的问题。
configMap
通常用来管理应用的配置文件或者环境变量
Kubernetes认证与授权
APIServer安全控制
Authentication:身份认证- 这个环节它面对的输入是整个http request,负责对来自client的请求进行身份校验,支持的方法包括:
• basic auth
• client证书验证(https双向验证)
• jwt token(用于serviceaccount)
secret
• rbac:基于角色认证,创建一个sa账户或user,配置基于角色的权限[get,list,watch,...],把账户与角色权限绑定,即可操作k8s的资源
• 通过证书与apiserver进行通信
• secret:管理敏感类的信息,默认会base64编码存储,有三种类型
1、generic:通用型secret,指定一个文件,文件内容指定用户名,密码
2、docker registry: 用来存储私有docker registry的认证信息。
3、tls:把证书加载进secret
4、Service Account :用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod
的/run/secrets/kubernetes.io/serviceaccount目录中;创建ServiceAccount后,Pod中指定
serviceAccount后,自动创建该ServiceAccount对应的secret;
5、Opaque : base64编码格式的Secret,用来存储密码、密钥等;
Kubernetes调度
Kubernetes Scheduler 的作用是将待调度的 Pod 按照一定的调度算法和策略绑定到集群中一个合适的 Worker Node 上,并将绑定信息写入到 etcd 中,之后目标 Node 中 kubelet 服务通过 API Server 监听到 Scheduler 产生的 Pod 绑定事件获取 Pod 信息,然后下载镜像启动容器。
调度的过程
Scheduler 提供的调度流程分为预选 (Predicates) 和优选 (Priorities) 两个步骤:
• 预选,K8S会遍历当前集群中的所有 Node,筛选出其中符合要求的 Node 作为候选
• 优选,K8S将对候选的 Node 进行打分
经过预选筛选和优选打分之后,K8S选择分数最高的 Node 来运行 Pod,如果最终有多个 Node 的分数最高,那么 Scheduler 将从当中随机选择一个 Node 来运行 Pod。
Kubernetes集群的网络实现
1、CNI介绍及集群网络选型
容器网络接口(Container Network Interface),实现kubernetes集群的Pod网络通信及管理。包括:
• CNI Plugin负责给容器配置网络,它包括两个基本的接口:配置网络: AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error)清理网络: DelNetwork(net NetworkConfig, rt RuntimeConf) error
• IPAM Plugin负责给容器分配IP地址,主要实现包括host-local和dhcp。
以上两种插件的支持,使得k8s的网络可以支持各式各样的管理模式,当前在业界也出现了大量的支持方案,其中比较流行的比如flannel、calico等。
kubernetes配置了cni网络插件后,其容器网络创建流程为:
• kubelet先创建pause容器生成对应的network namespace
• 调用网络driver,因为配置的是CNI,所以会调用CNI相关代码,识别CNI的配置目录为/etc/cni/net.d
• CNI driver根据配置调用具体的CNI插件,二进制调用,可执行文件目录为/opt/cni/bin,项目
• CNI插件给pause容器配置正确的网络,pod中其他的容器都是用pause的网络
可以在此查看社区中的CNI实现,https://github.com/containernetworking/cni
通用类型:flannel、calico等,部署使用简单
2、Flannel三种模型
1、host-gw模型
host-gw模型即网关模式,在服务器直接添加一条静态路由即可,效率高,各节点必须在同一网段
10.4.7.21通过172.7.22.0这条静态路由连接10.4.7.22这台主机再连接172.7.21网段,反之亦是
2、VxLAN模型
在不同网段,可以用VxLAN模式,主机A会生成一个flannel.1网卡,通过封装头从flannel.1网卡出去通过flanne隧道传出,从flannel.1网卡传入拆包,到达目标主机网卡到指向的静态路由,效率低
3、Directrouting模型
• 直接路由模式,结合了VxLAN和host-gw模型
• 自动识别服务器,如果同网段,则使用host-gw模型,如果不同网段则使用VxLAN模型
通过HPA实现业务应用的动态扩缩容
基于CPU的动态伸缩
基于内存的动态伸缩
基于自定义指标的动态伸缩
kubernetes对接分部式存储
PersistentVolume(持久化卷),是对底层的存储的一种抽象,它和具体的底层的共享存储技术的实现方式有关,比如 Ceph、GlusterFS、NFS 等
因为PV是直接对接底层存储的,就像集群中的Node可以为Pod提供计算资源(CPU和内存)一样,PV可以为Pod提供存储资源。因此PV不是namespaced的资源,属于集群层面可用的资源。Pod如果想使用该PV,需要通过创建PVC挂载到Pod中。
PVC全写是PersistentVolumeClaim(持久化卷声明),PVC 是用户存储的一种声明,创建完成后,可以和PV实现一对一绑定。对于真正使用存储的用户不需要关心底层的存储实现细节,只需要直接使用 PVC 即可。
storageClass实现动态挂载
创建pv及pvc过程是手动,且pv与pvc一一对应,手动创建很繁琐。因此,通过storageClass + provisioner的方式来实现通过PVC自动创建并绑定PV。
动态pvc验证及实现分析
使用流程: 创建pvc,指定storageclass和存储大小,即可实现动态存储。
EFK
Elasticsearch
Elasticsearch一个开源的分布式、Restful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。它可以被下面这样准确地形容:
• 一个分布式的实时文档存储,每个字段可以被索引与搜索;
• 一个分布式实时分析搜索引擎;
• 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
Kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。可以通过Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。也可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Fluentd
Fluentd一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储、kafka等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下 - 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务
为什么推荐使用fluentd作为k8s体系的日志收集工具?
将日志文件JSON化
可插拔架构设计
极小的资源占用
极强的可靠性
• 基于内存和本地文件的缓存
• 强大的故障转移
Prometheus监控
监控接口:xx.xx.xx.xx:xx/metrics
监控类型 :静态监控、动态监控(自动发现)
自动发现资源类型:node、ingress、service、pod、endpoint
监控对像:
• 基础监控:node_exporter CPU、内存、磁盘、IO
• 集群状态:kube-state-metrics k8s集群中各种控制器资源状态
• 容器存活:blackbox-exporter 检查容器存活(http、tcp)是否可用
• 容器资源利用:cadvisor 容器消耗了服务器多少资源
• 核心组件:etcd、kube-apiserver、kubelet、coredns
DevOps
devops = 提倡开发、测试、运维协同工作来实现持续开发、持续交付的一种软件交付模式 + 基于工具和技术支撑的自动化流程的落地实践。
因此devops不是某一个具体的技术,而是一种思想+自动化能力,来使得构建、测试、发布软件能够更加地便捷、频繁和可靠的落地实践。
- 这个环节它面对的输入是整个http request,负责对来自client的请求进行身份校验,支持的方法包括:
以上是 二进制部署K8s集群第25节之k8s技术点整理 的全部内容, 来源链接: utcz.com/z/509016.html