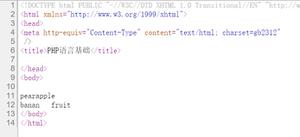
字符串哈希

//hash
#include<bits/stdc++.h>#define f(i,j,n) for(int i=j;i<=n;i++)
#define ll long long
#define ull unsigned ll
constintbase=131;
int prime=233317;ull mod
=212370440130137957ll;int n;ull a[
10010];char s[10010];usingnamespace std;void read(int &x) {int f=1; x
=0;char s=getchar();while(s<'0' or s>'9') {if(s=='-') f=-1; s
=getchar(); }
while(s>='0' and s<='9') { x
=x*10+s-'0'; s
=getchar(); }
x
*=f;}
ull hashe(
char s[]) {int len=strlen(s); ull ans
=0;for (int i=0; i<len; i++) ans
=(ans*base+(ull)s[i])%mod+prime;return ans;}
int main() { read(n);
f(i,
1,n) scanf("%s",&s),a[i]=hashe(s); sort(a
+1,a+n+1);int ans=0; f(i,
1,n-1)if(a[i]!=a[i+1]) ans++; printf(
"%d",ans+1);return0;}
浅析字符串哈希
哈希其实是所有字符串操作中,笔者认为最简单的操作了(except输入输出qwq)。哈希的过程,其实可以看作对一个串的单向加密过程,并且需要保证所加的密不能高概率重复(就像不能让隔壁老王轻易地用它家的钥匙打开你家门一样qwq),通过这种方式来替代一些很费时间的操作。
比如,最常见的,当然就是通过哈希数组来判断几个串是否相同(洛谷P3370)。此处的操作呢,很简单,就是对于每个串,我们通过一个固定的转换方式,将相同的串使其的“密”一定相同,不同的串 尽量 不同。
此处有人指出:那难道不能先比对字符串长度,然后比对ASCLL码之和吗?事实上显然是不行的(比如ab和ba,并不是同一个串,但是如是做却会让其认为是qwq)。这种情况就叫做hash冲突,并且在如此的单向加密哈希中,hash冲突的情况在所难免(bzoj就有这种让你给出一组样例,使得一段哈希代码冲突的题,读者可以尝试尝试)。
而我们此处介绍的,即是最常见的一种哈希:进制哈希。进制哈希的核心便是给出一个固定进制base,将一个串的每一个元素看做一个进制位上的数字,所以这个串就可以看做一个base进制的数,那么这个数就是这个串的哈希值;则我们通过比对每个串的的哈希值,即可判断两个串是否相同
以上是 字符串哈希 的全部内容, 来源链接: utcz.com/z/508866.html