java基础之hashcode理解及hashmap实现原理及MD5

1. hashcode值是int的,64位。int hashCode()。
2. java object类默认的hashcode()计算方法是根据对象的内存地址来计算的。所以可由此来判断默认不重写hashcode()方法的两个对象是否相同。
3. 可重写obejetc 类的hashCode()方法,去根据object对象的实际内容生成hashcode值,比如String类,改写了hashcode(),根据string字符串的内容区生成hashcode,而非根据object类默认的内存地址。
4.hashcode值是64为int值。hashcode值是不可逆的,即无法根据hashcode值反推原值。但要注意:hashcode是可能重复的,及不同的原始值,可能hashcode相同。这也就是为什么hashmap还有个equal()方法来判断两个值是否相等。
HashMap实现原理
1.为什么会有hashmap出现?
数组数据结构查找方便,删除困难。
链表插入删除方便,遍历性能低。
所以需设计一种数据结构,既能查询快,又能删除修改快。
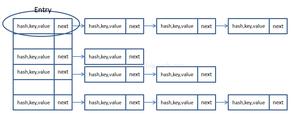
2.数据结构:数组+链表。hashcode决定在数组的存储位置,是根据key的hashcode值(非value)取模%数组长度,来决定数组的index位置。
hashmap默认数组大小是16.即Entry [16]。
通过equal来解决hash冲突情况
3.loadfactor负载因子,决定hashmap扩容
4.hashmap默认的数组大小是16
5.怎么解决hash冲突?:equal()方法判断
6.put(),get()方法内部执行逻辑?
一致性哈希
6.为什么String, Interger这样的wrapper类适合作为键?
String, Interger这样的wrapper类是final类型的,具有不可变性,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。
7.ConcurrentHashMap和Hashtable的区别
Hashtable和ConcurrentHashMap有什么分别呢?它们都可以用于多线程的环境,但是当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。因为ConcurrentHashMap引入了分割(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分,而Hashtable则会锁定整个map。
8.HashMap的遍历
第一种:
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
效率高,以后一定要使用此种方式!
第二种:
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}
效率低,以后尽量少使用!
可是为什么第一种比第二种方法效率更高呢?
HashMap这两种遍历方法是分别对keyset及entryset来进行遍历,但是对于keySet其实是遍历了2次,一次是转为iterator,一次就从hashmap中取出key所对于的value。而entryset只是遍历了第一次,它把key和value都放到了entry中,即键值对,所以就快了。
1.HashMap与Hashtable的区别:
HashMap可以接受null键值和值,而Hashtable则不能。
Hashtable是线程安全的,通过synchronized实现线程同步。而HashMap是非线程安全的,但是速度比Hashtable快。
5.如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办
HashMap默认的负载因子大小为0.75,也就是说,当一个map填满了75%的空间的时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的数组,来重新调整map的大小,并将原来的对象放入新的数组中。
下文转自http://www.cnblogs.com/eternalwt/archive/2013/03/21/2973807.html 感谢作者
1.在软件开发的用户注册功能中常出现MD5加密这个概念,这个概念有一定的误导性。严格来说:MD5还有sha-1、 RIPEMD以及Haval等不能算是加密算法(虽然常用于把密码变成“密文”),他们只是散列算法,或者叫摘要算法。加密对应解密这个概念,加密算法包括:DES、3DES、IDEA、 RSA、AES等。
2.MD5还有sha-1、 RIPEMD以及Haval等不能算是加密算法,只是散列算法,或者叫摘要算法。
2.MD5还有sha-1、 RIPEMD以及Haval等不能算是加密算法,只是散列算法,或者叫摘要算法。
2.MD5还有sha-1、 RIPEMD以及Haval等不能算是加密算法,只是散列算法,或者叫摘要算法。
3.加密对应解密这个概念,加密算法包括:DES、3DES、IDEA、 RSA、AES等。
3.加密对应解密这个概念,加密算法包括:DES、3DES、IDEA、 RSA、AES等。
3.加密对应解密这个概念,加密算法包括:DES、3DES、IDEA、 RSA、AES等。
4.MD5算法除了注册时对用户密码进行MD5运算以外,还常用于验证下载的软件的完整性
5.MD5算法除了注册时对用户密码进行MD5运算以外,还常用于验证下载的软件的完整性
6.MD5运算后的长度是固定的,它显然不可能包含视频、软件等源数据的全部信息。对于加密算法来说,加密后的密文是包含原始数据所有信息的,只是不能被直接读懂变的安全了。
7.MD5运算后的长度是固定的,它显然不可能包含视频、软件等源数据的全部信息。对于加密算法来说,加密后的密文是包含原始数据所有信息的,只是不能被直接读懂变的安全了。
4.要弄懂这两类算法的区别,最本质的方式就是把这两类算法的步骤搞懂,但这需要大量的时间。通过两类算法的表现可以对他们的区别有个大体的了解:
1.MD5算法除了注册时对用户密码进行MD5运算以外,还常用于验证下载的软件的完整性(linux下面md5sum命令可以支持这一典型应用),常用电驴等下载视频和软件的用户应该知道这一点。
MD5运算后的长度是固定的,它显然不可能包含视频、软件等源数据的全部信息。对于加密算法来说,加密后的密文是包含原始数据所有信息的,只是不能被直接读懂变的安全了。
MD5运算后的长度是固定的,它显然不可能包含视频、软件等源数据的全部信息。对于加密算法来说,加密后的密文是包含原始数据所有信息的,只是不能被直接读懂变的安全了。
6. 2.加密算法是一种通信体系,经常用于分布式系统。它的目标是数据经过传输后只能被特定的有密钥的人读懂,包含加密算法和密钥2个要素。而MD5等散列算法却不包含运算后的数据只能被特定人读懂的目标,它只让机器读懂。当用于加密时,它加密后的数据对所有人一视同仁,且没有密钥机制,没有好的方法从加密后的数据得到原始数据,从而保证数据的安全。它并不是通信机制,它是不可逆的。另外它的验证数据完整性的功能上面已经提到,我想,很多有心人最初正是从这一点意识到这两类算法的区别把?
7. 2.加密算法是一种通信体系,经常用于分布式系统。它的目标是数据经过传输后只能被特定的有密钥的人读懂,包含加密算法和密钥2个要素。而MD5等散列算法却不包含运算后的数据只能被特定人读懂的目标,它只让机器读懂。当用于加密时,它加密后的数据对所有人一视同仁,且没有密钥机制,没有好的方法从加密后的数据得到原始数据,从而保证数据的安全。它并不是通信机制,它是不可逆的。另外它的验证数据完整性的功能上面已经提到,我想,很多有心人最初正是从这一点意识到这两类算法的区别把?
8.很多编程人员为了将“密码”不明示,就对密码串进行md5散列,在数据库或文件中保存md5编码;但是,千万要注意,真正到了鉴别用户身份是否合法的时候,不是通过早先记录下来的md5编码生成原文再与用户当场输入的密码串进行比较,而是将用户当场输入的密码串也实施md5变换,比较的是前后两次生成的md5编码串。
8.很多编程人员为了将“密码”不明示,就对密码串进行md5散列,在数据库或文件中保存md5编码;但是,千万要注意,真正到了鉴别用户身份是否合法的时候,不是通过早先记录下来的md5编码生成原文再与用户当场输入的密码串进行比较,而是将用户当场输入的密码串也实施md5变换,比较的是前后两次生成的md5编码串。
以上是 java基础之hashcode理解及hashmap实现原理及MD5 的全部内容, 来源链接: utcz.com/z/394291.html