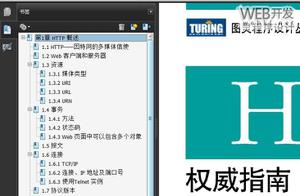
java 文件转成pdf文件 预览

一、前端代码
//预览功能preview: function () {
//判断选中状态
var ids ="";
var num = 0;
$(".checkbox").each(function () {
if($(this).is(\':checked\')){
ids +=$(this).val() + ",";
num++;
}
});
if(num <=0 ){
toastr.error(\'请选择需要预览的文件!\');
return;
}
if(num > 1){
toastr.error(\'页面下载只支持单个文件预览!\');
return;
}
ids = ids.slice(0,ids.length-1);
$.ajax({
type: "post",
url: backbasePath+\'/apia/v1/file/queryById\',
dataType:"json",
data:{
token:$("#token").val(),
id:ids,
},
success: function(data) {
if(\'000000\'==data.code){
// 文件路径
var path=data.data.file_path;
// 文件名称
var fileName=data.data.file_name;
// 获取文件后缀名
var suffix=fileName.substring(fileName.lastIndexOf(".")+1);
//如果对应的是文档
if(suffix == \'doc\' || suffix == \'docx\' || suffix == \'txt\'|| suffix == \'pdf\'){
//打开跳转页面
window.open(frontTemplatesPath + \'previewFile.html?suffix=\'+suffix+\'&path=\'+path+\'&fileName=\'+fileName,"_blank");
} else{
toastr.error(\'当前文件类型暂不支持预览!\');
}
} else if ((\'900000\' == data.code) || (\'999999\'== data.code)) {
toastr.error(\'查询文件信息失败!\');
} else {
toastr.error(data.msg);
}
},
error: function () {
toastr.error(\'查询文件信息失败!\');
}
});
},
<!DOCTYPE html><html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>文件预览界面</title>
</head>
<body>
<div class="container">
<div>
<div >
<iframe style="width: 100%;height: 1000px;" src="" id="pdf"></iframe>
</div>
</div>
</div>
</body>
</html>
<script src="/coalminehwaui/static/js/jquery-3.1.1.min.js"></script>
<script src="/coalminehwaui/static/js/project/common.js"></script>
<script src="/coalminehwaui/static/js/plugins/toastr/toastr.min.js"></script>
<!-- slimscroll把任何div元素包裹的内容区加上具有好的滚动条-->
<script src="/coalminehwaui/static/js/plugins/slimscroll/jquery.slimscroll.min.js"></script>
<script>
\'use strict\';
$(function () {
LookPlan.getUrlString();
LookPlan.init();
});
var LookPlan = new Object({
getUrlString:function(name){
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]);
return \'\';
},
init:function() {
var suffix =LookPlan.getUrlString(\'suffix\');
var path =LookPlan.getUrlString(\'path\');
var fileName =LookPlan.getUrlString(\'fileName\');
var src=backbasePath + \'/apia/v1/file/previewFile?path=\'+path+\'&fileName=\'+fileName+\'&suffix=\'+suffix;
setTimeout(function () {
document.getElementById("pdf").src=src;
}, 500);
}
});
</script>
二、后端代码
<!-- 文件转换成pdf-->
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-local</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-transformer-msoffice-word</artifactId>
<version>1.1.1</version>
</dependency>
import com.documents4j.api.DocumentType;
import com.documents4j.api.IConverter;
import com.documents4j.job.LocalConverter;
/*** 文档文件预览
*/
@RequestMapping(path = "/previewFile")
public void preview(HttpServletResponse response, @RequestParam(required = true)String path, @RequestParam(required = true)String fileName, @RequestParam(required = true)String suffix) throws Exception {
// 读取pdf文件的路径
String pdfPath="";
// 将对应的后缀转换成小写
String lastSuffix=suffix.toLowerCase();
//读取文件内容,获取文件存储的路径
String orgPath = filePath + path;
// 生成pdf文件的路径
String toPath = filePath + "pdf/";
// 判断对应的pdf是否存在,不存在则创建
File folder = new File(toPath);
if (!folder.exists()) {
folder.mkdirs();
}
// doc类型
if (lastSuffix.equals("pdf")) {
// pdf 文件不需要转换,直接从上传文件路径读取即可
pdfPath=orgPath;
} else {
// 转换之后的pdf文件
String newName=fileName.replace(lastSuffix,"pdf");;
File newFile = new File( toPath+"/"+newName);
// 如果转换之后的文件夹中有转换后的pdf文件,则直接从里面读取即可
if (newFile.exists()) {
pdfPath =toPath+"/"+newName;
}else {
pdfPath = wordToPdf(fileName,orgPath, toPath,lastSuffix);
}
}
// 读取文件流上
FileInputStream fis = new FileInputStream(pdfPath);
//设置返回的类型
response.setContentType("application/pdf");
//得到输出流,其实就是发送给客户端的数据。
OutputStream os = response.getOutputStream();
try {
int count = 0;
//fis.available()返回文件的总字节数
byte[] buffer = new byte[fis.available()];
//read(byte[] b)方法一次性读取文件全部数据。
while ((count = fis.read(buffer)) != -1)
os.write(buffer, 0, count);
os.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (os != null)
os.close();
if (fis != null)
fis.close();
}
}
/*** 将之前对应的word文件转换成pdf,然后预览pdf文件
*/
public String wordToPdf(String orgFile,String orgPath, String toPath, String suffix ){
// 转换之后的pdf文件
String targetFile=orgFile.replace(suffix,"pdf");
File inputWord = new File(orgPath);
File outputFile = new File(toPath+targetFile);
try {
InputStream docxInputStream = new FileInputStream(inputWord);
OutputStream outputStream = new FileOutputStream(outputFile);
IConverter converter = LocalConverter.builder().build();
if(suffix.equals("doc")){
converter.convert(docxInputStream).as(DocumentType.DOC).to(outputStream).as(DocumentType.PDF).execute();
} else if(suffix.equals("docx")){
converter.convert(docxInputStream).as(DocumentType.DOCX).to(outputStream).as(DocumentType.PDF).execute();
} else if(suffix.equals("txt")){
converter.convert(docxInputStream).as(DocumentType.TEXT).to(outputStream).as(DocumentType.PDF).execute();
}
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
return toPath+targetFile;
}
以上是 java 文件转成pdf文件 预览 的全部内容, 来源链接: utcz.com/z/393077.html