java.util.stream 库简介

Java Stream简介
Java SE 8 中主要的新语言特性是拉姆达表达式。可以将拉姆达表达式想作一种匿名方法;像方法一样,拉姆达表达式具有带类型的参数、主体和返回类型。但真正的亮点不是拉姆达表达式本身,而是它们所实现的功能。拉姆达表达式使得将行为表达为数据变得很容易,从而使开发具有更强表达能力、更强大的库成为可能。
Java SE 8 中引入的一个这样的库是 java.util.stream 包 (Streams),它有助于为各种数据来源上的可能的并行批量操作建立简明的、声明性的表达式。较早的 Java 版本中也编写过像 Streams 这样的库,但没有紧凑的行为即数据语言特性,而且它们的使用很麻烦,以至于没有人愿意使用它们。您可以将 Streams 视为 Java 中第一个充分利用了拉姆达表达式的强大功能的库,但它没有什么特别奇妙的地方(尽管它被紧密集成到核心 JDK 库中)。Streams 不是该语言的一部分 — 它是一个精心设计的库,充分利用了一些较新的语言特性。
关于本系列
借助 java.util.stream包,您可以简明地、声明性地表达集合、数组和其他数据源上可能的并行批量操作。在 Java 语言架构师 Brian Goetz 编写的这个 系列 中,全面了解 Streams 库,并了解如何最充分地使用它。
本文是一个深入探索 java.util.stream 库的系列的第一部分。本期介绍该库,并概述它的优势和设计原理。在后续几期中,您将学习如何使用流来聚合和汇总数据,了解该库的内部原理和性能优化。
使用流的查询
流的最常见用法之一是表示对集合中的数据的查询。清单 1 给出了一个简单的流管道示例。该管道获取一个在买家和卖家之间模拟购买的交易集合,并计算生活在纽约的卖家的交易总价值。
清单 1. 一个简单的流管道
1 2 3 4 5 |
|
“流利用了这种最强大的计算原理:组合。”
filter() 操作仅选择与来自纽约的卖家进行的交易。mapToInt() 操作选择所关注交易的交易金额。最终的 sum() 操作将对这些金额求和。
这个例子非常容易理解,即使比较挑剔的人也会发现这个查询的命令版本(for 循环)非常简单,而且需要更少的代码行即可表达。为了体现流方法的好处,示例问题没有必要变得过于复杂。流利用了这种最强大的计算原理:组合。通过使用简单的构建块(过滤、映射、排序、聚合)来组合复杂的操作,在问题变得比相同数据源上更加临时的计算更复杂时,流查询更可能保留写入和读取的简单性。
作为来自清单 1 中的相同领域的更复杂查询,考虑 “打印与年龄超过 65 岁的买家进行交易的卖家姓名,并按姓名排序。”以旧式的(命令)方式编写此查询可能会得到类似清单 2 的结果。
清单 2. 对一个集合的临时查询
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
尽管此查询比第一个查询稍微复杂一点,但很明显采用命令方法的结果代码的组织结构和可读性已开始下降。读者首先看到的不是计算的起点和终点;而是一个一次性中间结果的声明。要阅读此代码,您需要在头脑中缓存大量上下文,然后才能明白代码的实际用途。清单 3 展示了可以如何使用 Streams 重写此查询。
清单 3. 使用 Streams 表达的清单 2 中的查询
1 2 3 4 5 6 7 |
|
清单 3 中的代码更容易阅读,因为用户既没有被 “垃圾” 变量(比如 sellers 和 sorted)分心,也不需要在阅读代码的同时跟踪记录大量上下文;而且代码看起来几乎就像问题陈述一样。可读性更强的代码也更不容易出错,因为维护者更容易一眼就看出代码在做什么。
Streams 登录所采用的设计方法实现了实际的关注点分离。客户端负责指定计算的是 “什么”,而库负责控制 “如何做”。这种分离倾向于与专家经验的分发平行进行;客户端编写者通常能够更好地了解问题领域,而库编写者通常拥有所执行的算法属性的更多专业技能。编写允许这种关注点分离的库的主要推动力是,能够像传递数据一样轻松地传递行为,从而使调用方可在 API 中描述复杂计算的结构,然后离开,让库来选择执行战略。
流管道剖析
所有流计算都有一种共同的结构:它们具有一个流来源、0 或多个中间操作,以及一个终止操作。流的元素可以是对象引用 (Stream<String>),也可以是原始整数 (IntStream)、长整型 (LongStream) 或双精度 (DoubleStream)。
因为 Java 程序使用的大部分数据都已存储在集合中,所以许多流计算使用集合作为它们的来源。JDK 中的 Collection 实现都已增强,可充当高效的流来源。但是,还存在其他可能的流来源,比如数组、生成器函数或内置的工厂(比如数字范围),而且(如本系列中的 第 3 期 所示)可以编写自定义的流适配器,以便可以将任意数据源充当流来源。表 1 给出了 JDK 中的一些流生成方法。
表 1. JDK 中的流来源
| 方法 | 描述 |
|---|---|
Collection.stream() | 使用一个集合的元素创建一个流。 |
Stream.of(T...) | 使用传递给工厂方法的参数创建一个流。 |
Stream.of(T[]) | 使用一个数组的元素创建一个流。 |
Stream.empty() | 创建一个空流。 |
Stream.iterate(T first, BinaryOperator<T> f) | 创建一个包含序列 first, f(first), f(f(first)), ... 的无限流 |
Stream.iterate(T first, Predicate<T> test, BinaryOperator<T> f) | (仅限 Java 9)类似于 Stream.iterate(T first, BinaryOperator<T> f),但流在测试预期返回 false 的第一个元素上终止。 |
Stream.generate(Supplier<T> f) | 使用一个生成器函数创建一个无限流。 |
IntStream.range(lower, upper) | 创建一个由下限到上限(不含)之间的元素组成的 IntStream。 |
IntStream.rangeClosed(lower, upper) | 创建一个由下限到上限(含)之间的元素组成的 IntStream。 |
BufferedReader.lines() | 创建一个有来自 BufferedReader 的行组成的流。 |
BitSet.stream() | 创建一个由 BitSet 中的设置位的索引组成的 IntStream。 |
Stream.chars() | 创建一个与 String 中的字符对应的 IntStream。 |
中间操作负责将一个流转换为另一个流,中间操作包括 filter()(选择与条件匹配的元素)、map()(根据函数来转换元素)、distinct()(删除重复)、limit()(在特定大小处截断流)和 sorted()。一些操作(比如 mapToInt())获取一种类型的流并返回一种不同类型的流;清单 1 中的示例的开头处有一个 Stream<Transaction>,它随后被转换为 IntStream。表 2 给出了一些中间流操作。
表 2. 中间流操作
| 操作 | 内容 |
|---|---|
filter(Predicate<T>) | 与预期匹配的流的元素 |
map(Function<T, U>) | 将提供的函数应用于流的元素的结果 |
flatMap(Function<T, Stream<U>> | 将提供的流处理函数应用于流元素后获得的流元素 |
distinct() | 已删除了重复的流元素 |
sorted() | 按自然顺序排序的流元素 |
Sorted(Comparator<T>) | 按提供的比较符排序的流元素 |
limit(long) | 截断至所提供长度的流元素 |
skip(long) | 丢弃了前 N 个元素的流元素 |
takeWhile(Predicate<T>) | (仅限 Java 9)在第一个提供的预期不是 true 的元素处阶段的流元素 |
dropWhile(Predicate<T>) | (仅限 Java 9)丢弃了所提供的预期为 true 的初始元素分段的流元素 |
中间操作始终是惰性的:调用中间操作只会设置流管道的下一个阶段,不会启动任何操作。重建操作可进一步划分为无状态 和有状态 操作。无状态操作(比如 filter() 或 map())可独立处理每个元素,而有状态操作(比如 sorted() 或 distinct())可合并以前看到的影响其他元素处理的元素状态。
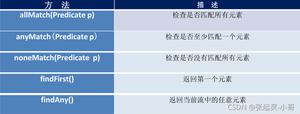
数据集的处理在执行终止操作时开始,比如缩减(sum() 或 max())、应用 (forEach()) 或搜索 (findFirst()) 操作。终止操作会生成一个结果或副作用。执行终止操作时,会终止流管道,如果您想再次遍历同一个数据集,可以设置一个新的流管道。表 3 给出了一些终止流操作。
表 3. 终止流操作
| 操作 | 描述 |
|---|---|
forEach(Consumer<T> action) | 将提供的操作应用于流的每个元素。 |
toArray() | 使用流的元素创建一个数组。 |
reduce(...) | 将流的元素聚合为一个汇总值。 |
collect(...) | 将流的元素聚合到一个汇总结果容器中。 |
min(Comparator<T>) | 通过比较符返回流的最小元素。 |
max(Comparator<T>) | 通过比较符返回流的最大元素。 |
count() | 返回流的大小。 |
{any,all,none}Match(Predicate<T>) | 返回流的任何/所有元素是否与提供的预期相匹配。 |
findFirst() | 返回流的第一个元素(如果有)。 |
findAny() | 返回流的任何元素(如果有)。 |
流与集合比较
尽管流在表面上可能类似于集合(您可以认为二者都包含数据),但事实上,它们完全不同。集合是一种数据结构;它的主要关注点是在内存中组织数据,而且集合会在一段时间内持久存在。集合通常可用作流管道的来源或目标,但流的关注点是计算,而不是数据。数据来自其他任何地方(集合、数组、生成器函数或 I/O 通道),而且可通过一个计算步骤管道处理来生成结果或副作用,在此刻,流已经完成了。流没有为它们处理的元素提供存储空间,而且流的生命周期更像一个时间点 — 调用终止操作。不同于集合,流也可以是无限的;相应地,一些操作(limit()、findFirst())是短路,而且可在无限流上运行有限的计算。
集合和流在执行操作的方式上也不同。集合上的操作是急切和突变性的;在 List 上调用 remove() 方法时,调用返回后,您知道列表状态会发生改变,以反映指定元素的删除。对于流,只有终止操作是急切的;其他操作都是惰性的。流操作表示其输入(也是流)上的功能转换,而不是数据集上的突变性操作(过滤一个流会生成一个新流,新流的元素是输入流的子集,但没有从来源删除任何元素)。
将流管道表达为功能转换序列可以实现多种有用的执行战略,比如惰性、短路 或操作融合。短路使得管道能够成功终止,而不必检查所有数据;类似 “找到第一笔超过 1000 美元的交易” 这样的查询不需要在找到匹配值后检查其他任何交易。操作融合表示,可在数据上的一轮中执行多个操作;在 清单 1 的示例中,3 个操作组合成了数据上的一轮操作,而不是首先选择所有匹配的交易,然后选择所有对应的金额,最后对它们求和。
类似 清单 1 和 清单 3 中的查询的命令版本通常依靠物化集合来获得中间计算的结果,比如过滤或映射的结果。这些结果不仅可能让代码变得杂乱,还可能让执行变得混乱。中间集合的物化仅作用于实现,而不作用于结果,而且它使用计算周期将中间结果组织为将会被丢弃的数据结构。
相反,流管道将它们的操作融合到数据上尽可能少的轮次中,通常为单轮。(有状态中间操作,比如排序,可引入对多轮执行必不可少的障碍点。)流管道的每个阶段惰性地生成它的元素,仅在需要时计算元素,并直接将它们提供给下一阶段。您不需要使用集合来保存过滤或映射的中间结果,所以省去了填充(和垃圾收集)中间集合的工作。另外,遵循 “深度优先” 而不是 “宽度优先” 的执行战略(跟踪一个数据元素在整个管道中的深度),会让被处理的操作在缓存中变得更 “热”,所以您可以将更多时间用于计算,花更少时间来等待数据。
除了将流用于计算之外,您可能还希望考虑通过 API 方法使用流来返回聚合结果,而在以前,您可能返回一个数组或集合。返回流的效率通常更高一些,因为您不需要将所有数据复制到一个新数组或集合中。返回流通常更加灵活;库选择返回的集合形式可能不是调用方所需要的,而且很容易将流转换为任何集合类型。(返回流不合适,而返回物化集合更合适的主要情形是,调用方需要查看某个时间点的状态的一致快照。)
并行性
将计算构建为功能转换的一个有益的结果是,您只需对代码进行极少的更改,即可轻松地在顺序和并行执行之间切换。流计算的顺序表达和相同计算的并行表达几乎相同。清单 4 展示了如何并行地执行 清单 1 中的查询。
清单 4. 清单 1 的并行版本
1 2 3 4 5 |
|
“将流管道表达为一系列功能转换,有助于实施一些有用的执行战略,比如惰性、并行性、短路和操作融合。”
第一行将会请求一个并行流而不是顺序流,这是与 清单 1 的唯一区别,因为 Streams 库有效地从执行计算的战略中分解出了计算的描述和结构。以前,并行执行要求完全重写代码,这样做不仅代价高昂,而且往往容易出错,因为得到的并行代码与顺序版本不太相似。
所有流操作都可以顺序或并行执行,但请记住,并行性并不是高性能的原因。并行执行可能比顺序执行更快、一样快或更慢。最好首先从顺序流开始,在您知道您能够获得提速(并从中受益)时才应用并行性。
内置收集器
| 收集器 | 行为 |
|---|---|
toList() | 将元素收集到一个 List 中。 |
toSet() | 将元素收集到一个 Set 中。 |
toCollection(Supplier<Collection>) | 将元素收集到一个特定类型的 Collection 中。 |
toMap(Function<T, K>, Function<T, V>) | 将元素收集到一个 Map 中,依据提供的映射函数将元素转换为键值。 |
summingInt(ToIntFunction<T>) | 计算将提供的 int 值映射函数应用于每个元素(以及 long 和 double 版本)的结果的总和。 |
summarizingInt(ToIntFunction<T>) | 计算将提供的 int 值映射函数应用于每个元素(以及 long 和 double 版本)的结果的 sum、min、max、count 和 average。 |
reducing() | 向元素应用缩减(通常用作下游收集器,比如用于groupingBy)(各种版本)。 |
partitioningBy(Predicate<T>) | 将元素分为两组:为其保留了提供的预期的组和未保留预期的组。 |
partitioningBy(Predicate<T>, Collector) | 将元素分区,使用指定的下游收集器处理每个分区。 |
groupingBy(Function<T,U>) | 将元素分组到一个 Map 中,其中的键是所提供的应用于流元素的函数,值是共享该键的元素列表。 |
groupingBy(Function<T,U>, Collector) | 将元素分组,使用指定的下游收集器来处理与每个组有关联的值。 |
minBy(BinaryOperator<T>) | 计算元素的最小值(与 maxBy() 相同)。 |
mapping(Function<T,U>, Collector) | 将提供的映射函数应用于每个元素,并使用指定的下游收集器(通常用作下游收集器本身,比如用于groupingBy)进行处理。 |
joining() | 假设元素为 String 类型,将这些元素联结到一个字符串中(或许使用分隔符、前缀和后缀)。 |
counting() | 计算元素数量。(通常用作下游收集器。) |
参考资料:Brian Goetz Stream API系列
以上是 java.util.stream 库简介 的全部内容, 来源链接: utcz.com/z/391918.html