java8 stream 注意点

https://blog.csdn.net/lixiaobuaa/article/details/81099838
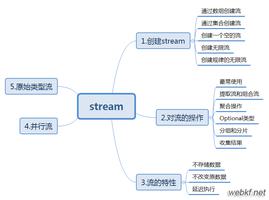
首先,Stream流有一些特性:
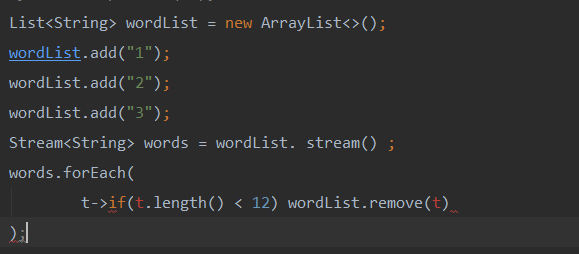
- Stream流不是一种数据结构,不保存数据,它只是在原数据集上定义了一组操作。//特别注意
- 这些操作是惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
- Stream不保存数据,故每个Stream流只能使用一次
关于应用在Stream流上的操作,可以分成两种:Intermediate(中间操作)和Terminal(终止操作)。中间操作的返回结果都是Stream,故可以多个中间操作叠加;终止操作用于返回我们最终需要的数据,只能有一个终止操作。至于哪些方法是中间操作,哪些方法是终止操作,我们一会儿再说。
使用Stream流,可以清楚地知道我们要对一个数据集做何种操作,可读性强。而且可以很轻松地获取并行化Stream流,不用自己编写多线程代码,可以让我们更加专注于业务逻辑。
接下来看一下Stream流的接口继承关系:
基础接口BaseStream<T, S extends BaseStream<T, S>>包含如下方法:
Iterator<T> iterator();
Spliterator<T> spliterator();
boolean isParallel(); //判断是否是并行化流
S sequential(); //将流串行化
S parallel(); //将流并行化
S unordered(); //解除有序流的顺序限制,发挥并行处理的性能优势
S onClose(Runnable closeHandler);
void close();
默认情况下,从有序集合、生成器、迭代器产生的流或者通过调用Stream.sorted产生的流都是有序流,有序流在并行处理时会在处理完成之后恢复原顺序。unordered()方法可以解除有序流的顺序限制,更好地发挥并行处理的性能优势,例如distinct将保存任意一个唯一元素而不是第一个,limit将保留任意n个元素而不是前n个。
BaseStream的四个子接口方法都差不多,只是IntStream、LongStream、DoubleStream直接存储基本类型,可以避免自动装/拆箱,效率会更高一些。下面以Stream为例,将接口的方法分类讲解一下。
一、 流的生成方法
Collection接口的stream()或parallelStream()方法
静态的Stream.of()、Stream.empty()方法
Arrays.stream(array, from, to)
静态的Stream.generate()方法生成无限流,接受一个不包含引元的函数
静态的Stream.iterate()方法生成无限流,接受一个种子值以及一个迭代函数
Pattern接口的splitAsStream(input)方法
静态的Files.lines(path)、Files.lines(path, charSet)方法
静态的Stream.concat()方法将两个流连接起来
……
注意,无限流的存在,侧面说明了流是惰性的,即每当用到一个元素时,才会在这个元素上执行这一系列操作。
二、 流的Intermediate方法(中间操作)
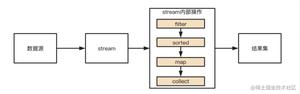
filter(Predicate)
将结果为false的元素过滤掉
map(fun)
转换元素的值,可以用方法引元或者lambda表达式
flatMap(fun)
若元素是流,将流摊平为正常元素,再进行元素转换
limit(n)
保留前n个元素
skip(n)
跳过前n个元素
distinct()
剔除重复元素
sorted()
将Comparable元素的流排序
sorted(Comparator)
将流元素按Comparator排序
peek(fun)
流不变,但会把每个元素传入fun执行,可以用作调试
三、 流的Terminal方法(终结操作)
约简操作
max(Comparator)
min(Comparator)
count()
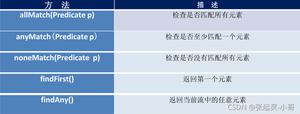
findFirst()
返回第一个元素
findAny()
返回任意元素
anyMatch(Predicate)
任意元素匹配时返回true
allMatch(Predicate)
所有元素匹配时返回true
noneMatch(Predicate)
没有元素匹配时返回true
reduce(fun)
从流中计算某个值,接受一个二元函数作为累积器,从前两个元素开始持续应用它,累积器的中间结果作为第一个参数,流元素作为第二个参数
reduce(a, fun)
a为幺元值,作为累积器的起点
reduce(a, fun1, fun2)
与二元变形类似,并发操作中,当累积器的第一个参数与第二个参数都为流元素类型时,可以对各个中间结果也应用累积器进行合并,但是当累积器的第一个参数不是流元素类型而是类型T的时候,各个中间结果也为类型T,需要fun2来将各个中间结果进行合并
收集操作
iterator()
forEach(fun)
forEachOrdered(fun)
可以应用在并行流上以保持元素顺序
toArray()
toArray(T[] :: new)
返回正确的元素类型
collect(Collector)
collect(fun1, fun2, fun3)
fun1转换流元素;fun2为累积器,将fun1的转换结果累积起来;fun3为组合器,将并行处理过程中累积器的各个结果组合起来
然后再看一下有哪些Collector收集器:
Collectors.toList()
Collectors.toSet()
Collectors.toCollection(集合的构造器引用)
Collectors.joining()、Collectors.joining(delimiter)、Collectors.joining(delimiter、prefix、suffix)
字符串元素连接
Collectors.summarizingInt/Long/Double(ToInt/Long/DoubleFunction)
产生Int/Long/DoubleSummaryStatistics对象,它有getCount、getSum、getMax、getMin方法,注意在没有元素时,getMax和getMin返回Integer/Long/Double.MAX/MIN_VALUE
Collectors.toMap(fun1, fun2)/toConcurrentMap
两个fun用来产生键和值,若值为元素本身,则fun2为Function.identity()
Collectors.toMap(fun1, fun2, fun3)/toConcurrentMap
fun3用于解决键冲突,例如(oldValue, newValue) -> oldValue,有冲突时保留原值
Collectors.toMap(fun1, fun2, fun3, fun4)/toConcurrentMap
默认返回HashMap或ConcurrentHashMap,fun4可以指定返回的Map类型,为对应的构造器引元
Collectors.groupingBy(fun)/groupingByConcurrent(fun)
fun是分类函数,生成Map,键是fun函数结果,值是具有相同fun函数结果元素的列表
Collectors.partitioningBy(fun)
键是true/false,当fun是断言函数时用此方法,比groupingBy(fun)更高效
Collectors.groupingBy(fun1, fun2)
fun2为下游收集器,可以将列表转换成其他形式,例如toSet()、counting()、summingInt/Long/Double(fun)、maxBy(Comparator)、minBy(Comparator)、mapping(fun1, fun2)(fun1为转换函数,fun2为下游收集器)
最后提一下基本类型流,与对象流的不同点如下:
IntStream和LongStream有range(start, end)和rangeClosed(start, end)方法,可以生成步长为1的整数范围,前者不包括end,后者包括end
toArray方法将返回基本类型数组
具有sum、average、max、min方法
summaryStatics()方法会产生类型为Int/Long/DoubleSummaryStatistics的对象
可以使用Random类的ints、longs、doubles方法产生随机数构成的流
对象流转换为基本类型流:mapToInt()、mapToLong()、mapToDouble()
基本类型流转换为对象流:boxed()
---------------------
作者:Francis长风
来源:CSDN
原文:https://blog.csdn.net/lixiaobuaa/article/details/81099838
版权声明:本文为博主原创文章,转载请附上博文链接!
以上是 java8 stream 注意点 的全部内容, 来源链接: utcz.com/z/391446.html