Java对正则表达式的支持(二)

正则表达式的主要用途:
a.在目标字符串中找出匹配正则表达式的部分
b.校验目标字符串是否符合正则表达式,例如校验邮箱地址
c.在目标字符串中替换符合正则表达式的部分为其他的字符串
Scanner类是JDK 1.5中引入的扫描类,Scanner类的构造函数可以接受一个Readable对象,具体说来可以是File、String、InputStream等。
下面是一个Scanner类配合正则表达式使用的例子,目的是找出以S、s、c、t开头的单词。
package RegexTest;import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ScannerTest {
public static void main(String [ ] args) throws FileNotFoundException {
Pattern pa = Pattern.compile("\\b[Ssct]\\w+");
Matcher ma = pa.matcher("");
Scanner sc = new Scanner(new File("src/RegexTest/ScannerTest.java"));
while(sc.hasNextLine()){
ma.reset(sc.nextLine());
while(ma.find()){
System.out.println(ma.group());
}
}
}
}
输出结果为:
Scannerclass
ScannerTest
static
String
throws
compile
Ssct
Scanner
sc
Scanner
src
ScannerTest
sc
sc
System
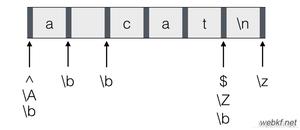
正则表达式"\\b[Ssct]\\w+"的含义如下,\b表示单词的边界,使用正则表达式操作单词时需要使用\b。w代表的是0-9或者a-z或者A-Z。
sc.hasNextLine()可以判断Scanner是否能取到下一行,sc.nextLine()是取下一行的字符串。
Scanner还有hasNextInt()、hasNextLong()、hasNextBigInteger()等方法用于取出下一个基本类型。
Scanner默认地是根据空格来分割输入的字符串,也可以自定义分割符,如下面所示。
import java.util.Scanner;public class ScannerTest2 {
public static void main(String [ ] args) {
String str = "12,42 , 78 ,99, 42";
Scanner sc = new Scanner(str);
sc.useDelimiter("\\s*,\\s*");
while(sc.hasNextInt()){
System.out.println(sc.nextInt());
}
}
}
输出结果为:
1242
78
99
42
sc.useDelimiter("\\s*,\\s*");中的\s代表空白符(空格,回车,换行等),*代表一个或多个,合起来就是“,”前后带任意个空白符。
Scanner除了可以配合Pattern和Matcher使用外,其本身也是支持正则表达式的,如下面的例子。
package RegexTest;import java.util.Scanner;
import java.util.regex.MatchResult;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ScannerTest3 {
public static void main(String [ ] args) {
String str = "58.77.82.161@02/10/2012\n" +
"204.17.82.31@02/11/2012\n" +
"58.77.32.53@02/12/2012\n" +
"28.45.32.161@02/12/2012\n";
Scanner sc = new Scanner(str);
String pattern = "(\\d+\\.\\d+\\.\\d+\\.\\d+)@"+
"(\\d{2}/\\d{2}/\\d{4})";
while(sc.hasNext(pattern)){
sc.next(pattern);
MatchResult mr = sc.match();
String ip = mr.group(1);
String date = mr.group(2);
System.out.format("Threat on %s from %s\n",date,ip);
}
Pattern pa = Pattern.compile("(\\d+\\.\\d+\\.\\d+\\.\\d+)@"+
"(\\d{2}/\\d{2}/\\d{4})",Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);
Matcher matcher = pa.matcher(str);
while(matcher.find()){
String ip = matcher.group(1);
String date = matcher.group(2);
System.out.format("Threat on %s from %s\n",date,ip);
}
}
}
输出结果为:
Threat on 02/10/2012 from 58.77.82.161Threat on 02/11/2012 from 204.17.82.31
Threat on 02/12/2012 from 58.77.32.53
Threat on 02/12/2012 from 28.45.32.161
Threat on 02/10/2012 from 58.77.82.161
Threat on 02/11/2012 from 204.17.82.31
Threat on 02/12/2012 from 58.77.32.53
Threat on 02/12/2012 from 28.45.32.161
下面是一个将IP地址进行排序的例子,如下:
package regExp;import java.util.Arrays;
public class SortIPAddressWithRegExp {
public static void main(String[] args) {
String ip = "102.49.25.254 102.49.23.13 10.10.10.10 2.2.2.2 8.109.90.30";
// 先对IP每一位都添加两个0
String regex = "(\\d+)";
ip = ip.replaceAll(regex,"00$1");
System.out.println(ip);
// 再将IP地址只保留三位
regex = "0*(\\d{3})";
ip = ip.replaceAll(regex,"$1");
System.out.println(ip);
// 下面进行切割
String[] result = ip.split(" +");
System.out.println(Arrays.asList(result));
Arrays.sort(result);
System.out.println("after");
for(int i =0;i<result.length;i++)
result[i]=result[i].replaceAll("0*(\\d+)","$1"); // 将前面的0 去掉
for(String s : result)
System.out.println(s);
}
}
使用正则表达式判断文件中是否含有中文字符的例子为:
import java.io.File;import java.io.FileNotFoundException;
import java.util.Scanner;
import java.util.regex.Pattern;
public class CheckChineseCharacter {
public static void main(String[] args) throws FileNotFoundException {
Scanner sc = new Scanner(new File("UCS_PM_1.1.5_EN.sql"));
String str = "";
int index = 1;
while(sc.hasNextLine()){
str = sc.nextLine();
if(isChinese(str)){
System.out.println(str + "contain Chinese Character");
}else{
System.out.println("no Chinese Character in cloum " + index);
}
index ++;
}
}
// 根据Unicode编码判断中文汉字和符号
private static boolean isChinese(char c) {
Character.UnicodeBlock ub = Character.UnicodeBlock.of(c);
if (ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS || ub == Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS
|| ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A || ub == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_B
|| ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION || ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS
|| ub == Character.UnicodeBlock.GENERAL_PUNCTUATION) {
return true;
}
return false;
}
// 完整的判断中文汉字和符号
public static boolean isChinese(String strName) {
char[] ch = strName.toCharArray();
for (int i = 0; i < ch.length; i++) {
char c = ch[i];
if (isChinese(c)) {
return true;
}
}
return false;
}
// 只能判断部分CJK字符(CJK统一汉字)
public static boolean isChineseByREG(String str) {
if (str == null) {
return false;
}
Pattern pattern = Pattern.compile("[\\u4E00-\\u9FBF]+");
return pattern.matcher(str.trim()).find();
}
// 只能判断部分CJK字符(CJK统一汉字)
public static boolean isChineseByName(String str) {
if (str == null) {
return false;
}
// 大小写不同:\\p 表示包含,\\P 表示不包含
// \\p{Cn} 的意思为 Unicode 中未被定义字符的编码,\\P{Cn} 就表示 Unicode中已经被定义字符的编码
String reg = "\\p{InCJK Unified Ideographs}&&\\P{Cn}";
Pattern pattern = Pattern.compile(reg);
return pattern.matcher(str.trim()).find();
}
}
以上是 Java对正则表达式的支持(二) 的全部内容, 来源链接: utcz.com/z/391377.html