Java多线程具体解释

Java多线程具体解释
多线程简单介绍
概述
多线程(multithreading)。是指从软件或者硬件上实现多个线程并发运行的技术。具有多线程能力的计算机因有硬件支持而可以在同一时间运行多于一个线程,进而提升总体处理性能。具有这样的能力的系统包含对称多处理机、多核心处理器以及芯片级多处理或同一时候多线程处理器。在一个程序中,这些独立运行的程序片段叫作“线程”(Thread),利用它编程的概念就叫作“多线程处理”。
具有多线程能力的计算机因有硬件支持而可以在同一时间运行多于一个线程,进而提升总体处理性能。
长处
使用线程能够把占领时间长的程序中的任务放到后台去处理
- 用户界面能够更加吸引人,这样比方用户点击了一个button去触发某些事件的处理,能够弹出一个进度条来显示处理的进度
程序的执行速度可能加快
在一些等待的任务实现上如用户输入、文件读写和网络收发数据等。线程就比較实用了。在这样的情况下能够释放一些珍贵的资源如内存占用等等。
- 多线程技术在软件开发中有举足轻重的位置。
缺点
假设有大量的线程,会影响性能,由于操作系统须要在它们之间切换。
很多其它的线程须要很多其它的内存空间。
线程可能会给程序带来很多其它“bug”,因此要小心使用。
线程的中止须要考虑其对程序执行的影响。
通常块模型数据是在多个线程间共享的,须要防止线程死锁情况的发生。
程序、进程、线程
- 程序:程序是指令的集合,它是静态描写叙述文本;程序本身是并不能单独执行,仅仅有将程序装载到内存中,系统为它分配资源才干执行。
比方:我们写的java程序。
- 进程:当系统为程序分配资源。程序就能够执行,就产生了进程。
也就是进程就是程序的一次执行活动。所以:进程是系统进行资源分配和调度的一个独立单位。演示样例:启动任务管理器[PID列默认是不显示]、执行一个main函数。然后观察任务管理器。
- 线程:也称作轻量级进程。是比进程颗粒度更小的能独立执行的基本单位。
是系统资源分配和调度的基本单位。一个进程能够支持多个线程。上述样例中有一个main线程在执行。
多线程内存模型
模型
从上图来看,线程A与线程B之间如要通信的话。必需要经历以下2个步骤:
首先,线程A把本地内存A中更新过的共享变量刷新到主内存中去。
然后。线程B到主内存中去读取线程A之前已更新过的共享变量。
以下通过示意图来说明这两个步骤:
1、如上图所看到的,本地内存A和B有主内存中共享变量x的副本。
如果初始时。这三个内存中的x值都为0。
线程A在运行时,把更新后的x值(如果值为1)暂时存放在自己的本地内存A中。
当线程A和线程B须要通信时。线程A首先会把自己本地内存中改动后的x值刷新到主内存中,此时主内存中的x值变为了1。
随后,线程B到主内存中去读取线程A更新后的x值,此时线程B的本地内存的x值也变为了1。
2、从总体来看。这两个步骤实质上是线程A在向线程B发送消息。并且这个通信过程必需要经过主内存。
JMM通过控制主内存与每一个线程的本地内存之间的交互,来为java程序猿提供内存可见性保证。
内存间交互操作
关于主内存与工作内存之间的详细交互协议,即一个变量怎样从主内存复制到工作内存、怎样从工作内存同步到主内存之间的实现细节,Java内存模型定义了下面八种操作来完毕:
lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才干够被其它线程锁定。
read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
load(加载):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给运行引擎。每当虚拟机遇到一个须要使用变量的值的字节码指令时将会运行这个操作。
assign(赋值):作用于工作内存的变量。它把一个从运行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时运行这个操作。
store(存储):作用于工作内存的变量。把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
假设要把一个变量从主内存中拷贝到工作内存,就须要按顺寻地运行read和load操作,假设把变量从工作内存中同步回主内存中,就要按顺序地运行store和write操作。Java内存模型仅仅要求上述操作必须按顺序运行。而没有保证必须是连续运行。也就是read和load之间,store和write之间是能够插入其它指令的,如对主内存中的变量a、b进行訪问时,可能的顺序是read
a,read b,load b。load a。Java内存模型还规定了在运行上述八种基本操作时,必须满足例如以下规则:
不同意read和load、store和write操作之中的一个单独出现
不同意一个线程丢弃它的近期assign的操作。即变量在工作内存中改变了之后必须同步到主内存中。
不同意一个线程无原因地(没有发生过不论什么assign操作)把数据从工作内存同步回主内存中。
一个新的变量仅仅能在主内存中诞生,不同意在工作内存中直接使用一个未被初始化(load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先运行过了assign和load操作。
一个变量在同一时刻仅仅同意一条线程对其进行lock操作,lock和unlock必须成对出现
假设对一个变量运行lock操作,将会清空工作内存中此变量的值,在运行引擎使用这个变量前须要又一次运行load或assign操作初始化变量的值
假设一个变量事先没有被lock操作锁定。则不同意对它运行unlock操作;也不同意去unlock一个被其它线程锁定的变量。
对一个变量运行unlock操作之前。必须先把此变量同步到主内存中(运行store和write操作)。
多线程创建和启动
线程创建的两种方法
继承Thread类。
实现步骤:
1、继承Thread而且重写Thread的run(),将线程执行的代码实如今run方法里。
2、创建类的实例。
3、调用start()方法是线程使线程进入就绪状态,等待cpu分配资源。
注意:假设直接调用这个对象的run方法,这时底层资源并没有完毕资源的创建和请求分配,不过简单的对象调用。
代码演示样例:
public class ThreadTest { public static void main(String[] args) {
//实例化一个自己定义线程并启动
//注意,此时线程处于
new MyThread().start();
//主线程中打印输出
for (int i = 0; i < 10; i++) {
//获取当前线程的名称
System.out.println(Thread.currentThread().getName() + " --> " + i);
}
}
}
//创建自己定义线程,继承Thread父类
class MyThread extends Thread {
@Override
//覆写父类的run()方法,从而实现自己的业务逻辑
public void run() {
for (int i = 0; i < 10; i++) {
//Thread.currentThread().getName() 获取当前线程的名称
System.out.println(Thread.currentThread().getName() + " --> " + i);
}
}
}
实现Runnable。
实现步骤:
1、实现Runnable而且重写Runnable的run(),将线程执行的代码实如今run方法里。
2、创建类的实例。
3、将上述的演示样例传入Thread的构造函数来创建Thread实例。
调用Thread实例的start()方法是线程使线程进入就绪状态,等待cpu分配资源。
代码演示样例
public class ThreadTest { public static void main(String[] args) {
//实例化一个自己定义线程并启动
//注意,此时线程处于
MyThread myThread = new MyThread();
new Thread(myThread).start();
//主线程中打印输出
for (int i = 0; i < 10; i++) {
//获取当前线程的名称
System.out.println(Thread.currentThread().getName() + " --> " + i);
}
}
}
//创建自己定义线程,继承Thread父类
class MyThread implements Runnable {
@Override
//覆写父类的run()方法。从而实现自己的业务逻辑
public void run() {
for (int i = 0; i < 10; i++) {
//Thread.currentThread().getName() 获取当前线程的名称
System.out.println(Thread.currentThread().getName() + " --> " + i);
}
}
}
两种创建的差别
差别:
- 在继承Thread中能够直接使用this来调用thread的方法。
比方 this.getName()获取线程名字。而继承Runnable仅仅能先获取当前的进程对象,Thread.currentThread().getName()。
- 假设线程类仅仅是实现了Runnable接口,那么该类还能够继承其他类。
可是继承了thread就不能继承其他类了。
- 实现Runnable。能够多个线程共享一个Runnable target对象的资源,所以很适合多个同样线程来处理同一份资源。
推荐实现Runnable 接口。
用户、守护线程
java中的线程主要分为:用户线程和守护线程:
1、一般java代码默认创建的线程为用户线程。
2、守护线程是指在程序执行的时候在后台提供一种通用服务的线程。比方垃圾回收线程。
java中的守护线程,在其执行之前将Thread实例设置了setDaemon(true)
守护线程演示样例:
//守护线程设置thread.setDaemon(true);
// 准备就绪 等待执行
thread.start();
差别:
守护线程和用户线程的唯一差别是:当进程中没有活动的用户线程时,守护线程会被jvm中断,退出程序
Thread经常用法
线程睡眠——sleep
假设我们须要让当前正在运行的线程暂停一段时间。并进入堵塞状态。则能够通过调用Thread的sleep方法。
public class Test1 { public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 100; i++) {
System.out.println("main" + i);
Thread.sleep(100);
}
}
}
线程让步——yield
yield()方法和sleep()方法有点相似,它也是Thread类提供的一个静态的方法。它也能够让当前正在运行的线程暂停,让出cpu资源给其它的线程。可是和sleep()方法不同的是。它不会进入到堵塞状态。而是进入到就绪状态。
yield()方法仅仅是让当前线程暂停一下,又一次进入就绪的线程池中,让系统的线程调度器又一次调度器又一次调度一次,全然可能出现这种情况:当某个线程调用yield()方法之后,线程调度器又将其调度出来又一次进入到运行状态运行。
实际上,当某个线程调用了yield()方法暂停之后,优先级与当前线程同样,或者优先级比当前线程更高的就绪状态的线程更有可能获得运行的机会,当然。仅仅是有可能,由于我们不可能精确的干涉cpu调度线程。
代码演示样例:
class Test1 { public static void main(String[] args) throws InterruptedException {
new MyThread("低级", 1).start();
new MyThread("中级", 5).start();
new MyThread("高级", 10).start();
}
}
class MyThread extends Thread {
public MyThread(String name, int pro) {
super(name);// 设置线程的名称
this.setPriority(pro);// 设置优先级
}
@Override
public void run() {
for (int i = 0; i < 30; i++) {
System.out.println(this.getName() + "线程第" + i + "次运行!");
if (i % 5 == 0)
Thread.yield();
}
}
}
线程合并——join
线程的合并的含义就是将几个并行线程的线程合并为一个单线程运行,应用场景是当一个线程必须等待还有一个线程运行完毕才干运行时,Thread类提供了join方法来完毕这个功能,注意。它不是静态方法。
它有3个重载的方法:
- void join() : 当前线程等该增加该线程后面。等待该线程终止。
- void join(long millis) : 当前线程等待该线程终止的时间最长为 millis 毫秒。 假设在millis时间内,该线程没有运行完,那么当前线程进入就绪状态,又一次等待cpu调度
- void join(long millis,int nanos) : 等待该线程终止的时间最长为 millis 毫秒 + nanos 纳秒。假设在millis时间内。该线程没有运行完。那么当前线程进入就绪状态,又一次等待cpu调度
代码演示样例:
public class Test1 { public static void main(String[] args) throws InterruptedException {
MyThread thread = new MyThread();
thread.start();
thread.join(1);//将主线程增加到子线程后面,只是假设子线程在1毫秒时间内没运行完,则主线程便不再等待它运行完,进入就绪状态,等待cpu调度
for (int i = 0; i < 30; i++) {
System.out.println(Thread.currentThread().getName() + "线程第" + i + "次运行!");
}
}
}
class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println(this.getName() + "线程第" + i + "次运行!");
}
}
}
线程的优先级
每一个线程运行时都有一个优先级的属性,优先级高的线程能够获得较多的运行机会。而优先级低的线程则获得较少的运行机会。与线程休眠类似,线程的优先级仍然无法保障线程的运行次序。
仅仅只是。优先级高的线程获取CPU资源的概率较大,优先级低的也并不是没机会运行。
每一个线程默认的优先级都与创建它的父线程具有同样的优先级,在默认情况下,main线程具有普通优先级。
Thread类提供了setPriority(int newPriority)和getPriority()方法来设置和返回一个指定线程的优先级。当中setPriority方法的參数是一个整数。范围是1~10
代码演示样例:
public class Test1 { public static void main(String[] args) throws InterruptedException {
new MyThread("高级", 10).start();
new MyThread("低级", 1).start();
}
}
class MyThread extends Thread {
public MyThread(String name, int pro) {
super(name);//设置线程的名称
setPriority(pro);//设置线程的优先级
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(this.getName() + "线程第" + i + "次运行。");
}
}
}
守护线程
守护线程与普通线程写法上基本么啥差别,调用线程对象的方法setDaemon(true)。则能够将其设置为守护线程。
- 守护线程使用的情况较少。但并不是无用。举例来说。JVM的垃圾回收、内存管理等线程都是守护线程。
还有就是在做数据库应用时候,使用的数据库连接池。连接池本身也包括着非常多后台线程。监控连接个数、超时时间、状态等等。
setDaemon方法的具体说明:
public final void setDaemon(boolean on)将该线程标记为守护线程或用户线程。当正在执行的线程都是守护线程时,Java 虚拟机退出。
该方法必须在启动线程前调用。
该方法首先调用该线程的 checkAccess 方法,且不带不论什么參数。这可能抛出 SecurityException(在当前线程中)
代码演示样例:
//守护线程设置thread.setDaemon(true);
// 准备就绪 等待执行
thread.start();
怎样结束一个线程
Thread.stop()、Thread.suspend、Thread.resume、Runtime.runFinalizersOnExit这些终止线程执行的方法已经被废弃了,使用它们是极端不安全的!
想要安全有效的结束一个线程。能够使用interrupt结束一个线程。
代码演示样例:
public class Test1 { public static void main(String[] args) throws InterruptedException {
MyThread thread = new MyThread();
thread.start();
}
}
class MyThread extends Thread {
int i = 1;
@Override
public void run() {
while (true) {
System.out.println(i);
System.out.println(this.isInterrupted());
try {
System.out.println("我立即去sleep了");
Thread.sleep(2000);
this.interrupt();
} catch (InterruptedException e) {
System.out.println("异常捕获了" + this.isInterrupted());
return;
}
i++;
}
}
}
线程的等待与唤醒
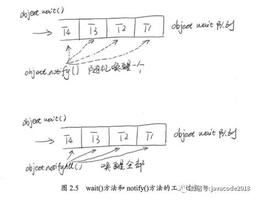
wait():
等待对象的同步锁,须要获得该对象的同步锁才干够调用这种方法,否则编译能够通过。但执行时会收到一个异常:IllegalMonitorStateException。
调用随意对象的 wait() 方法导致该线程堵塞。该线程不可继续运行。而且该对象上的锁被释放。
notify():
唤醒在等待该对象同步锁的线程(仅仅唤醒一个,假设有多个在等待),注意的是在调用此方法的时候。并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程。并且不是按优先级。
调用随意对象的notify()方法则导致因调用该对象的 wait()方法而堵塞的线程中随机选择的一个解除堵塞(但要等到获得锁后才真正可运行)。
notifyAll():
唤醒全部等待的线程,注意唤醒的是notify之前wait的线程,对于notify之后的wait线程是没有效果的。
其它一些方法:
- isAlive(): 推断一个线程是否存活。
- activeCount(): 程序中活跃的线程数。
- enumerate(): 枚举程序中的线程。
- currentThread(): 得到当前线程。
- setName(): 为线程设置一个名称。
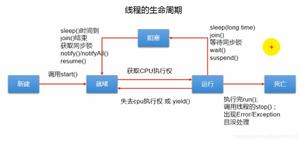
线程的生命周期
图示:
1、新建状态
用newkeyword和Thread类或其子类建立一个线程对象后,该线程对象就处于新生状态。处于新生状态的线程有自己的内存空间。通过调用start方法进入就绪状态(runnable)。
注意:不能对已经启动的线程再次调用start()方法,否则会出现java.lang.IllegalThreadStateException异常。
2、就绪状态
处于就绪状态的线程已经具备了执行条件,但还没有分配到CPU。处于线程就绪队列(虽然是採用队列形式,其实,把它称为可执行池而不是可执行队列。由于cpu的调度不一定是依照先进先出的顺序来调度的),等待系统为其分配CPU。等待状态并非执行状态。当系统选定一个等待执行的Thread对象后,它就会从等待执行状态进入执行状态。系统挑选的动作称之为“cpu调度”。一旦获得CPU。线程就进入执行状态并自己主动调用自己的run方法。
假设希望子线程调用start()方法后马上运行。能够使用Thread.sleep()方式使主线程睡眠一伙儿,转去运行子线程。
3、执行状态
处于执行状态的线程最为复杂,它能够变为堵塞状态、就绪状态和死亡状态。
处于就绪状态的线程,假设获得了cpu的调度,就会从就绪状态变为执行状态。执行run()方法中的任务。假设该线程失去了cpu资源,就会又从执行状态变为就绪状态。又一次等待系统分配资源。也能够对在执行状态的线程调用yield()方法。它就会让出cpu资源,再次变为就绪状态。
当发生例如以下情况是。线程会从执行状态变为堵塞状态:
- 线程调用sleep方法主动放弃所占用的系统资源
- 线程调用一个堵塞式IO方法,在该方法返回之前,该线程被堵塞
- 线程试图获得一个同步监视器,但更改同步监视器正被其它线程所持有
- 线程在等待某个通知(notify)
- 程序调用了线程的suspend方法将线程挂起。
只是该方法easy导致死锁,所以程序应该尽量避免使用该方法。
- 当线程的run()方法执行完,或者被强制性地终止,比如出现异常,或者调用了stop()、desyory()方法等等,就会从执行状态转变为死亡状态。
4、堵塞状态
处于执行状态的线程在某些情况下,如执行了sleep(睡眠)方法,或等待I/O设备等资源。将让出CPU并临时停止自己的执行,进入堵塞状态。
在堵塞状态的线程不能进入就绪队列。仅仅有当引起堵塞的原因消除时,如睡眠时间已到,或等待的I/O设备空暇下来,线程便转入就绪状态,又一次到就绪队列中排队等待。被系统选中后从原来停止的位置開始继续执行。
有三种方法能够暂停Threads执行:
5、死亡状态
当线程的run()方法运行完,或者被强制性地终止,就觉得它死去。
这个线程对象或许是活的,可是。它已经不是一个单独运行的线程。线程一旦死亡。就不能复生。 假设在一个死去的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
线程的同步
同步原因:
- 多线程同一时候操作同一变量的时候会产生脏数据。也就是不是预期的结果。
- 多线程可能造成死锁,导致程序崩溃。
脏数据
原因:
其它线程在一个线程将本地内存中变量写入准内存之前读取了这个变量。导致错误。
代码演示样例(售票问题):
public class SellTicket { public static void main(String[] args) {
SaleTicket st = new SaleTicket();
//创建四个线程买票
Thread t1 = new Thread(st, "一号窗体");
Thread t2 = new Thread(st, "二号窗体");
Thread t3 = new Thread(st, "三号窗体");
Thread t4 = new Thread(st, "四号窗体 ");
t1.start();
t2.start();
t3.start();
t4.start();
}
}
class SaleTicket implements Runnable {
private int tickets = 100;
public void run() {
//当票量大于0时,继续买票
while (tickets > 0) {
System.out.println(Thread.currentThread().getName() + "卖出 第 " + (tickets--) + "张票");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
死锁
原因:
即由于两个或多个线程都无法得到对应的锁而造成的两个线程都等待的现象。这样的现象主要是由于相互嵌套的synchronized代码段而造成,因此,在程序中尽可能少用嵌套的synchronized代码段是防止线程死锁的好方法。
代码演示样例:
public class DeadLock { //水壶
private Object object1 = new Object();
//水杯
private Object object2 = new Object();
public static void main(String[] args) {
new DeadLock().test();
}
private void test() {
// TODO Auto-generated method stub
//people 1
Thread th1 = new Thread(new Dead(0), "小明");
//people 2
Thread th2 = new Thread(new Dead(1), "小华");
th1.start();
th2.start();
try {
Thread.sleep(6000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//死锁类
class Dead implements Runnable {
private int tag = 0;
public Dead(int _tag) {
tag = _tag;
// TODO Auto-generated constructor stub
}
@Override
public void run() {
// TODO Auto-generated method stub
if (tag == 0) {
//尝试着拿水壶
synchronized (object1) {
System.out.println(Thread.currentThread().getName() + "拿到了水壶");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//尝试着去拿水杯
System.out.println(Thread.currentThread().getName() + "尝试着拿水杯");
synchronized (object2) {
System.out.println(Thread.currentThread().getName() + "也拿到了水杯");
}
}
} else {
//尝试着拿水杯
synchronized (object2) {
System.out.println(Thread.currentThread().getName() + "拿到了水杯");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//尝试着去拿水壶
System.out.println(Thread.currentThread().getName() + "尝试着拿水壶");
synchronized (object1) {
System.out.println(Thread.currentThread().getName() + "也拿到了水壶");
}
}
}
}
}
}
同步三种方法
Java 语言提供了两个keyword:synchronized 和volatile,一个对象ReetrantLock来实现线程的同步。
synchronized
synchronized是Java中的keyword,是一种同步锁。它修饰的对象有下面几种:
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2. 修饰一个方法。被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这种方法的对象;
3. 改动一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的全部对象;
4. 改动一个类。其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的全部对象。
给某个对象加锁:
//object必须为要同步的对象。也就是可能会出现故障的对象synchronized (object){
//业务逻辑
}
修饰一个方法:
写法一:
public synchronized void method (){
// todo
}
写法二:
public void method (){
synchronized (this) {
// todo
}
}
修饰静态方法:
public synchronized static void method () { // todo
}
修饰类:
class ClassName { public void method() {
synchronized (ClassName.class) {
// todo
}
}
}
要点:
- 不管synchronizedkeyword加在方法上还是对象上,假设它作用的对象是非静态的。则它取得的锁是对象;假设synchronized作用的对象是一个静态方法或一个类,则它取得的锁是对类,该类全部的对象同一把锁。
- 每一个对象仅仅有一个锁(lock)与之相关联,谁拿到这个锁谁就能够执行它所控制的那段代码。
- 实现同步是要非常大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
volatile
- Volatile:它是一个类型修饰符,线程在获取用volatile声明的变量时。直接从主存读取,改动后直接写入主存。
volatilekeyword为域变量的訪问提供了一种免锁机制, 使用volatile修饰域相当于告诉虚拟机该域可能会被其它线程更新。因此每次使用该域就要又一次计算,而不是使用寄存器中的值。
- volatile不会提供不论什么原子操作,它也不能用来修饰final类型的变量。
代码演示样例:
class Bank { //须要同步的变量加上volatile
private volatile int account = 100;
public int getAccount() {
return account;
}
//这里不再须要synchronized
public void save(int money) {
account += money;
}
}
注意:
Volatile Volatile 变量的同步性较差(但有时它更简单并且开销更低),并且其使用也更easy出错,所以尽量使用synchronized同步
ReetrantLock
java.util.concurrent.lock 中的 Lock 框架是锁定的一个抽象,它同意把锁定的实现作为 Java 类。而不是作为语言的特性来实现。这就为 Lock 的多种实现留下了空间,各种实现可能有不同的调度算法、性能特性或者锁定语义。
ReentrantLock 类实现了 Lock 。它拥有与 synchronized 同样的并发性和内存语义,可是加入了类似锁投票、定时锁等候和可中断锁等候的一些特性。此外,它还提供了在激烈争用情况下更佳的性能。(换句话说。当很多线程都想訪问共享资源时。JVM
能够花更少的时候来调度线程。把很多其它时间用在运行线程上。
)
ReetrantLock 是在代码的不论什么地方都能够获得锁、释放锁、可是为了安全推荐在finally块中释放锁。
代码演示样例:
Lock lock = new ReentrantLock();lock.lock();
try {
// update object state
} finally {
lock.unlock();
}
线程池
线程池的作用
1、 在java中。假设每一个请求到达就创建一个新线程,开销是相当大的。在实际使用中。server在创建和销毁线程上花费的时间和消耗的系统资源都相当大,甚至可能要比在处理实际的用户请求的时间和资源要多的多。
除了创建和销毁线程的开销之外,活动的线程也须要消耗系统资源。假设在一个jvm里创建太多的线程,可能会使系统因为过度消耗内存或“切换过度”而导致系统资源不足。为了防止资源不足。server应用程序须要採取一些办法来限制不论什么给定时刻处理的请求数目,尽可能降低创建和销毁线程的次数,特别是一些资源耗费比較大的线程的创建和销毁,尽量利用已有对象来进行服务,这就是“池化资源”技术产生的原因。
2、线程池主要用来解决线程生命周期开销问题和资源不足问题。通过对多个任务反复使用线程,线程创建的开销就被分摊到了多个任务上了。并且因为在请求到达时线程已经存在。所以消除了线程创建所带来的延迟。
这样,就能够马上为请求服务,使用应用程序响应更快。另外,通过适当的调整线程中的线程数目能够防止出现资源不足的情况。
介绍四种线程池
1. new SingleThreadExecutor
创建一个单线程的线程池。这个线程池仅仅有一个线程在工作。也就是相当于单线程串行运行全部任务。假设这个唯一的线程由于异常结束,那么会有一个新的线程来替代它。
此线程池保证全部任务的运行顺序依照任务的提交顺序运行。
2.new FixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。
线程池的大小一旦达到最大值就会保持不变,假设某个线程由于运行异常而结束。那么线程池会补充一个新线程。
3. new CachedThreadPool
创建一个可缓存的线程池。假设线程池的大小超过了处理任务所须要的线程,
那么就会回收部分空暇(60秒不运行任务)的线程。当任务数添加时,此线程池又可以智能的加入新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小全然依赖于操作系统(或者说JVM)可以创建的最大线程大小。
4.new ScheduledThreadPool
创建一个运行延时、周期行运行任务的线程池。
ExecutorService表述了异步运行的机制。而且能够让任务在后台运行。
ExecutorService对象一般使用流程:
1、Executors创建一个线程池
2、调用submit 加入线程任务(參数是一个实现Runnable接口的对象)。(周期线程:schedule、scheduleAtFixedRate、scheduleWithFixedDelay)
3、调用shutdown等任务完毕后关闭线程池。
代码演示样例:
//单线程池ExecutorService executorService= Executors.newSingleThreadExecutor();
executorService.submit(new SayHello());
executorService.submit(new SayHello());
executorService.submit(new SayHello());
//固定大小的线程池ExecutorService executorServiceFixed=Executors.newFixedThreadPool(4);
executorServiceFixed.submit(new SayHello());
executorServiceFixed.submit(new SayHello());
executorServiceFixed.submit(new SayHello());
executorService.shutdown();
//可变的(缓存)线程池ExecutorService executorServiceCache=Executors.newCachedThreadPool();
executorServiceCache.submit(new SayHello());
executorServiceCache.submit(new SayHello());
executorServiceCache.submit(new SayHello());
executorServiceCache.submit(new SayHello());
//周期性线程池ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(3);
//延迟的调用scheduledExecutorService.schedule(new SayHello(), 2, TimeUnit.SECONDS);
System.out.println(new Date());
//固定延时的线程池。//long initialDelay 初始化的延迟时间:提交任务X(TimeUnit)后開始运行此任务。
//long delay 周期性的延迟时间:运行完毕一个任务后的X(TimeUnit)后再运行下一个任务,时间间隔是以完毕任务时的时间点。
//本次任务完毕的时间点+delay(TimeUnit)=下次任务開始的时间。
scheduledExecutorService.scheduleWithFixedDelay(new SayHello(), 2, 4, TimeUnit.SECONDS);
System.out.println(new Date());
//固定运行间隔的线程池//long delay 周期性的运行时间:開始运行一个任务后的X(TimeUnit)后再运行下一个任务。时间间隔是以開始任务时的时间点。
//本次任务開始的时间点+delay(TimeUnit)=下次任务開始的时间。可是:假设delay小于运行任务的运行时间的时候,第二个任务会在第一个任务完毕后開始。
scheduledExecutorService.scheduleAtFixedRate(new SayHello(), 3, 4, TimeUnit.SECONDS);
System.out.println(new Date());
以上是 Java多线程具体解释 的全部内容, 来源链接: utcz.com/z/391185.html